
For the Gemini 3 Hackathon , I’ve built a Massively Multiplayer Online Role-Playing Storyteller (MMORPS). It’s a platform where humans and AI co-create persistent, branching narratives with history, memory, and consequence.
Problem Statement
Traditional AI story generators produce “stateless” prose. If you edit a character’s fate in Chapter 1, the system often forgets that change by Chapter 10, or worse, it overwrites the original story entirely.
Living Storybook solves this by treating every story as a branching multiverse. It provides:
- Long-term Narrative Memory: Causal links that persist across chapters.
- Manifested Souls: AI characters that evolve based on their historical experiences.
- Canonical Integrity: A stateful validation layer that ensures consistency across parallel timelines.
🔗 Source Code
https://github.com/seehiong/living-storybook
Angular · FastAPI · LangGraph · Firestore
System Overview: Narrative Control Flow
Before diving into the code, here is the high-level control flow that governs planning, prose generation, validation, and state mutation for each narrative turn:
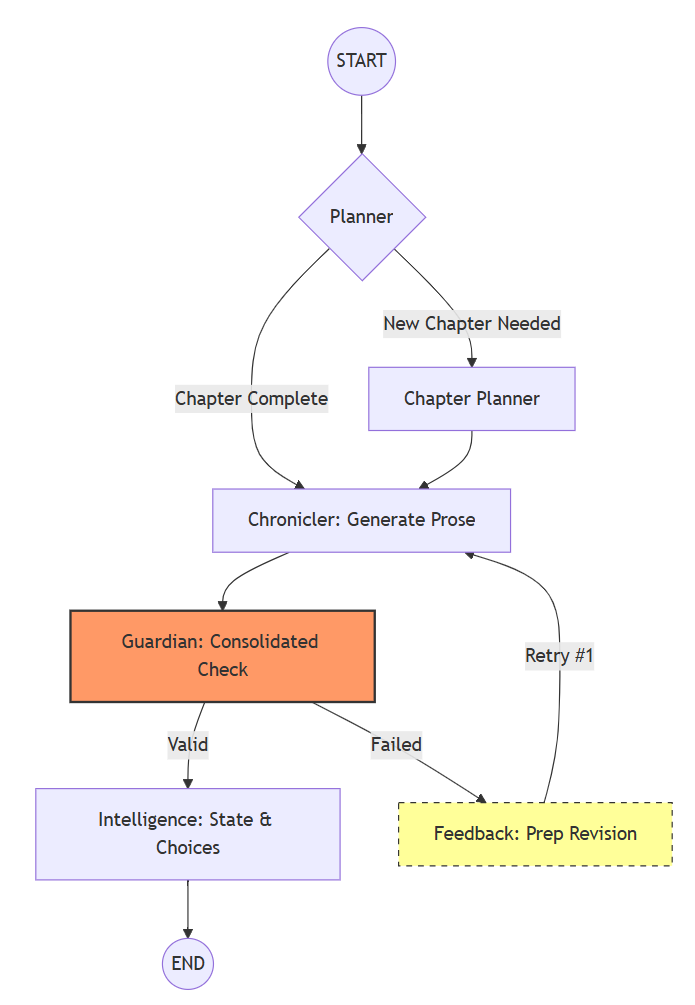
The diagram highlights the system’s single-retry guardrail and the separation between creative generation (Chronicler) and canonical authority (Guardian).
Setup
The project is structured as a decoupled full-stack application:
- Frontend: Angular 18 (with NgRx for state management).
- Backend: FastAPI + LangGraph (Python orchestrator).
- Cloud: Google Cloud (Cloud Run, Firestore, Firebase Auth/Storage).
Firestore
I use a hierarchical Firestore schema designed for high-frequency narrative updates:
stories/{storyId}: Main metadata and sequential counters.stories/{storyId}/segments/{segId}: Discrete narrative nodes (prose, choices).stories/{storyId}/chapters/{chapId}: Structural blueprints for the AI.stories/{storyId}/characters/{charId}: Persistent “soul” data (personality, evolution).
Architectural Intent: Why Firestore over a Graph DB?
While Living Storybook models a Directed Acyclic Graph (DAG), I chose Firestore over specialized Graph DBs (like Neo4j) or SQL recursive CTEs for several key reasons:
- O(Depth) Pathing: Because the story is “Backward-Linked,” reconstructing a timeline never requires recursive queries. It’s a simple iterative retrieval of parents, which Firestore handles with extremely low latency.
- Real-time Synchronization: Firebase’s listener patterns allow the LHP (Multiverse Map) to update instantly as agents commit new branches.
- Write Efficiency: Atomic batch writes allow for O(1) commits regardless of graph complexity.
Access Controls
Security is handled via Firebase Authentication (Google & Anonymous) and fine-grained Firestore rules.
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /{document=**} {
// For development, we allow open access; production uses per-user claims
allow read, write: if request.auth != null;
}
}
}Key Components
LangGraph Backend (The “Narrative Brain”)
The core innovation is the Narrative Brain — a LangGraph-powered multi-agent system. Instead of one giant prompt, I orchestrate specialized Gemini 3 agents:
# From backend/app/brain.py
workflow = StateGraph(UpdatedNarrativeState)
# Specialized Nodes
workflow.add_node("planner", chapter_planner_node)
workflow.add_node("chronicler", chronicler_node)
workflow.add_node("guardian", canon_guardian_node)
workflow.add_node("feedback", guardian_feedback_node)
workflow.add_node("intelligence", narrative_intelligence_node)
# Defining the Causal Loop
workflow.set_entry_point("planner")
workflow.add_edge("planner", "chronicler")
workflow.add_edge("chronicler", "guardian")
# Intelligent Routing
workflow.add_conditional_edges(
"guardian",
route_post_validation,
{"intelligence": "narrative_intelligence", "retry": "feedback"}
)
# Back-edges & Termination
workflow.add_edge("feedback", "chronicler")
workflow.add_edge("narrative_intelligence", END)- Chronicler: Focuses exclusively on high-quality literary prose.
- Guardian: Validates the prose against the established “Canon” and “Style Guide”.
- Intelligence: Updates the narrative state and generates logical “Choice Specs”.
- Feedback: Provides the Chronicler with specific revision blueprints if validation fails.
Angular Frontend Architecture
The frontend is built with Angular 18 and NgRx, designed to handle the high complexity of branching timelines. Key features include:
- Time-Weave Navigation (LHP): A dynamic sidebar that uses a combination of Backward and Forward Pathing to project the active narrative branch.
- Narrative DNA Tracker: Reactive state management that preserves world-rules even as the story forks.
- Optimistic Narrative Persistence: The UI remains responsive by leveraging local state while backend pipelines run in the background.
Key components include:
StoryEditorMainComponent: The primary writing interface.TimeWeaveNavComponent: The “multiverse map” for jumping between timelines.ChapterDraftingTableComponent: Where I guide the AI’s long-term planning.
NgRx for Multiverse Traversal
To reconstruct the “Unified Projection” of the narrative branches, I use specialized NgRx selectors that walk the Directed Acyclic Graph (DAG) in real-time.
// From src/app/store/selectors/story.selectors.ts
export const selectNavigationNodes = createSelector(
selectActivePathNodes,
selectAllNodes,
(activePath, allNodes) => {
const nodesMap = new Map<string, any>();
// 1. Add the active linear path (Backtraced from current leaf)
activePath.forEach(n => nodesMap.set(n.id, n));
// 2. Add "Anchors" (Root nodes of all possible chapters/branches)
Object.values(allNodes).forEach(n => {
if (n.depth === 1) nodesMap.set(n.id, n);
});
// 3. Sort by Chapter Number then Linear Depth
return Array.from(nodesMap.values()).sort((a, b) => {
return (a.depth || 1) - (b.depth || 1);
});
}
);Shared Pathing Utilities
The “structural truth” of the story is maintained through a simple but robust backward-linkage pattern:
// From src/app/utils/story.utils.ts
static reconstructGenericPath(currentNode: StoryNode, allNodesMap: { [id: string]: StoryNode }): StoryNode[] {
const path: StoryNode[] = [];
let visitor: StoryNode | undefined = currentNode;
while (visitor) {
path.unshift(visitor); // Add to start of array
if (!visitor.prevSegId) break; // Found root
visitor = allNodesMap[visitor.prevSegId];
}
return path;
}Performance & Cost Envelope
Maintaining a sub-60s latency for a multi-agent pipeline and managing token costs are critical for production viability.
Efficiency Targets
- Latency: The average “Narrate” operation takes 40-60s, reduced from >120s by consolidating 10+ sequential agents into a 3-stage LangGraph loop.
- Tokens: A typical segment generation consumes ~1,500 – 3,000 tokens (including history context). Summarization logic prevents context bloating as the story deepens.
- Cold Starts: Running on Cloud Run with a
min-instances: 1setting for the API keeps response times snappy. - Writes: Story initialization involves a Single Firestore Batch (creating 6+ documents), ensuring atomic success or failure.
Optimization Key Pillars
- Single-Pass Intelligence: Instead of multiple LLM calls for metadata, choices, and world-updates, everything is synthesized in one structured Gemini 3 pass.
- Consolidated Guardian: Lore-checks, style-validation, and character-presence are validated in one pass with a strict 1-retry ceiling.
- Batch Persistence: All narrative updates are saved to Firestore in atomic batches, eliminating the O(N) write penalty.
Adaptive Latency Calibration
The frontend MetricsService maintains a capped moving average of E2E latency. This allows the UI to “learn” the current network and model performance, adjusting predictive countdown timers for the user.
// src/app/services/metrics.service.ts
/**
* Calculates a capped moving average to ensure the system "learns" quickly (max 10 samples)
*/
private calculateCappedAverage(currentAvg: number, currentCalls: number, newValue: number): number {
const weight = Math.min(currentCalls, 10);
return ((currentAvg * weight) + newValue) / (weight + 1);
}E2E Latency Measurement
Latency is measured end-to-end at the service level, capturing the entire round-trip from the client through the Narrative Brain.
// src/app/services/gemini.service.ts
async narrate(params: { ... }): Promise<GeminiResult<any>> {
const startTime = Date.now();
const response = await firstValueFrom(this.http.post<any>(url, payload));
const e2eLatencyMs = Date.now() - startTime;
const usage = {
...response.data.usage,
latencyMs: e2eLatencyMs,
isStoryContinue: !params.blueprint
};
await this.metrics.recordUsage(usage);
return { data: response.data, usage };
}Cost Tracking & User Usage
Aggregated metrics are stored in the user’s profile, allowing for granular visibility into token consumption and API efficiency.
// src/app/models/user.model.ts
export interface UserUsage {
totalTokensInput: number;
totalTokensOutput: number;
totalApiCalls: number;
averageLatencyMsPerNarrate: number; // Narrative Brain (/api/story/narrate)
averageLatencyMsPerStoryStart: number; // Story Creation (/api/story/start)
averageLatencyMsPerOracle: number; // Oracle Planning (/api/story/suggest_blueprint)
}Architectural Guardrails: Data Model Invariants
To prevent state corruption across the multiverse, the following invariants are enforced at the type level and in the persistence layer:
- Singleton Parentage: Every
StoryNode(segment) has exactly oneprevSegId. This prevents narrative loops and ensures a clean DAG structure. - Immutability of the Past: Once a node is part of a published edition, it is Temporally Locked. Mutations are rejected; users must Fork to change history.
- Causal Continuity: Forked stories must increment
depthand copy current sequential counters (currentSegId) to ensure new segments don’t collide with original numbering. - Attribution Inheritance: Every forked segment retains a
forkedFromreference, maintaining a clear lineage across the multiverse.
Code Representation: The Story Node
The StoryNode is the atomic unit of the multiverse. Its structure enforces parentage and depth invariants:
// From src/app/models/story.model.ts
export interface StoryNode {
id: string; // e.g., "seg_1"
storyId: string; // e.g., "story_abc123"
prevSegId?: string; // The SINGLE parent link
depth: number; // Linear position in branch (relative to chapter)
text: string; // The generated prose
choices: Choice[]; // Branching entry points
publishedInEditions?: string[]; // Locking signal
}The Story Metadata
The root Story document tracks the global state and sequential counters:
export interface Story {
id: string;
startSegId: string;
currentSegId?: number; // Global counter for segment IDs
totalChapters?: number; // Counter for chapter IDs
forkedFrom?: string; // Multiverse lineage
narrativeDNA?: NarrativeDNA; // World rules
}Failure Modes & Safeguards
Building for a hackathon means planning for when things go wrong:
- Probabilistic Validation: The
Guardiannode occasionally provides confidence-scored “soft failures.” - Narrative Stalling: If the AI detects a narrative loop (e.g., repeating the same scene), the
Intelligencenode injects Narrative Disruptors (new stakes, time jumps, or character pressure). - State Corruption: Because Firestore is the source of truth, if an agent fails mid-process, the LangGraph
StateGraphensures the story doesn’t advance, preventing “broken” segments from appearing in the user’s timeline.
Dynamic Pathing (The Multiverse Engine)
The “In Action” experience is powered by a sophisticated pathing system that maintains a “Unified Projection” of the story.
The Structural Truth
In Living Storybook, truth is Backward-Linked. Each segment points to its parent (prevSegId), allowing us to reconstruct any specific timeline by walking back from a leaf node to the root.
Celestial Archive (Locking)
To prevent “causal paradoxes,” any node that has been published as part of a Chronicle is marked as Temporally Locked. This preserves the historical record while forcing new ideas to Fork into parallel timelines.
Temporal Anchors
The system uses “Anchors” (typically the first segment of each chapter) to ensure the navigation panel feels consistent, even when the reader is exploring a deep, unconventional branch.
Narrative State Architecture (Data Model)
To support true branching narratives, Living Storybook separates content from state. Rather than mutating a single story document, each segment captures immutable snapshots of world state, narrative DNA, and memory. This allows timelines to fork freely while preserving causal integrity and historical truth.
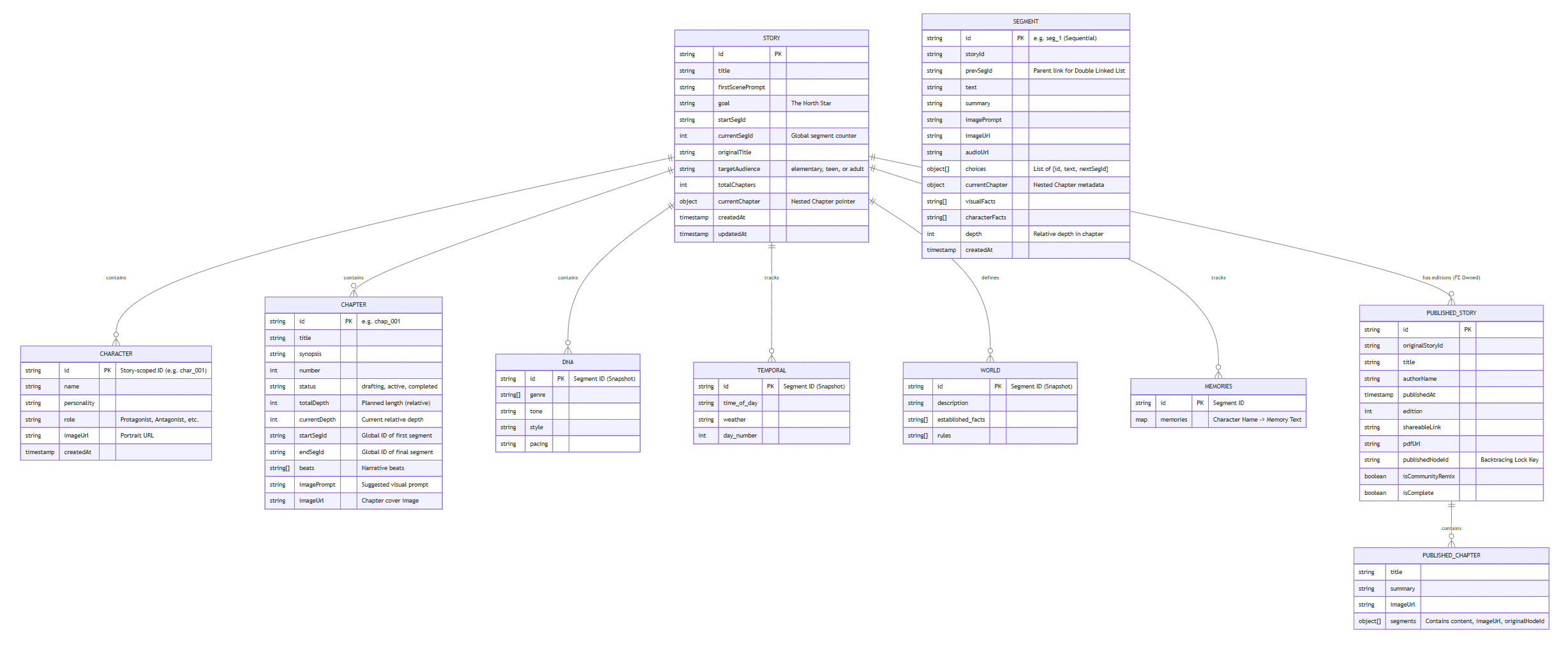
Deletion Logic Rules
These lifecycle rules ensure the multiverse remains coherent even when users revise, prune, or reset narrative branches.
| Action | Deleted Items |
|---|---|
| Prune Segment X | Segment X + All Descendant Segments. Matching IDs in temporals, worlds, memories, dnas. |
| Delete Chapter Y | Chapter Y Document. Matching ID in dnas. |
| Reset Story | All Segments (Prune from Root). Keeps Story Metadata. Clears startSegId. |
| Delete Story | Story Document + All Collections. (Removes from Library). |
| Unpublish Story | Story Edition Archive entry (metadata only). |
Getting Started
Running Locally
- Backend:
cd backend python -m app.main - Frontend:
ng serve
Deploying to Google Cloud
The backend is containerized for Google Cloud Run, ensuring it can scale to zero during idle periods.
gcloud run deploy backend-service \
--image us-central1-docker.pkg.dev/YOUR-PROJECT-ID/living-storybook-repo/backend \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--set-env-vars="GOOGLE_API_KEY=your-gemini-key,PROJECT_ID=living-storybook" Deploy to Firebase
firebase deploy --only hostingIn Action: Navigating the Multiverse
Living Storybook is more than a writing app; it’s a window into a branching reality. Here is how the system handles the complexities of co-authoring and causal persistence.
1. The Multiverse Navigator
The Time-Weave Navigation panel (LHP) is the heart of the experience. Unlike linear sidebars, it reconstructs the active timeline in real-time. When you select a segment, the system walks the backward-links to project exactly which nodes belong to your current “truth.”
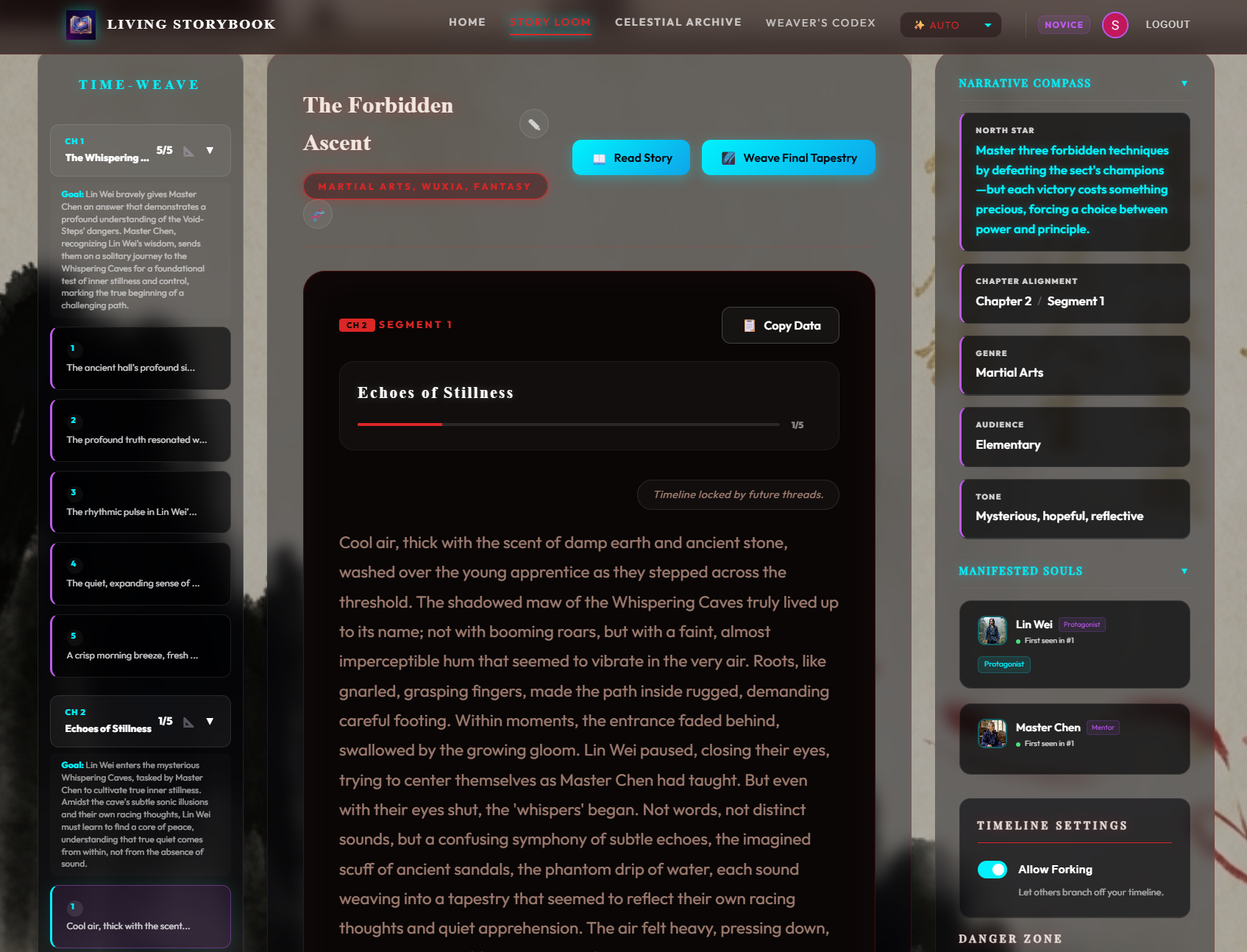 Caption: The Time-Weave Navigation panel projecting the active narrative path.
Caption: The Time-Weave Navigation panel projecting the active narrative path.
2. Co-Authoring with the Oracle
Before a single word is written, you collaborate with the Gemini 3 Oracle. By providing a high-level prompt, the Oracle suggests a structured Chapter Blueprint, including emotional beats and narrative goals that will guide the subsequent generation.
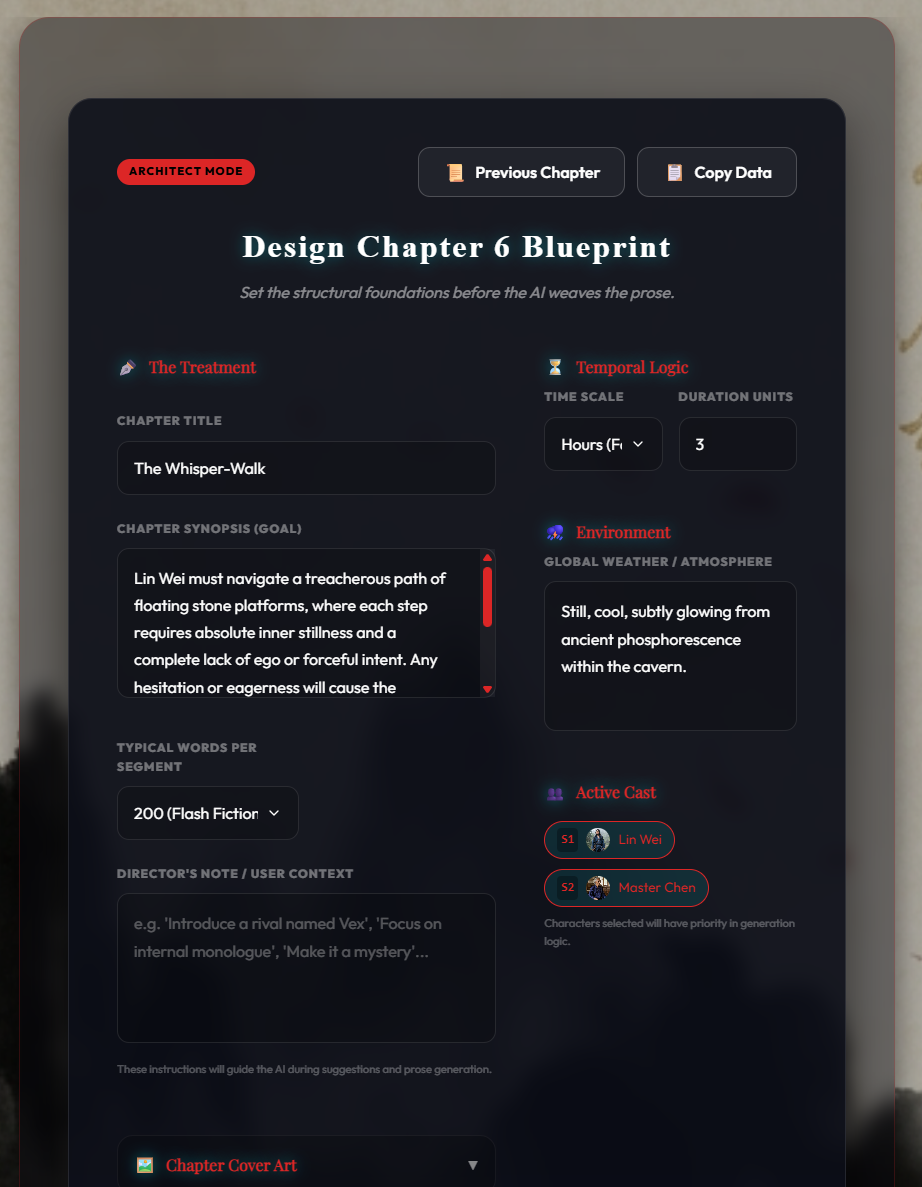 Caption: Collaborating with the Gemini 3 Oracle to draft a Chapter Blueprint.
Caption: Collaborating with the Gemini 3 Oracle to draft a Chapter Blueprint.
3. The Chronicler’s Loom
In the main editor, the Chronicler generates prose that adheres to your established style guide, while the Intelligence agent updates character vitals and emotional arcs in the background.
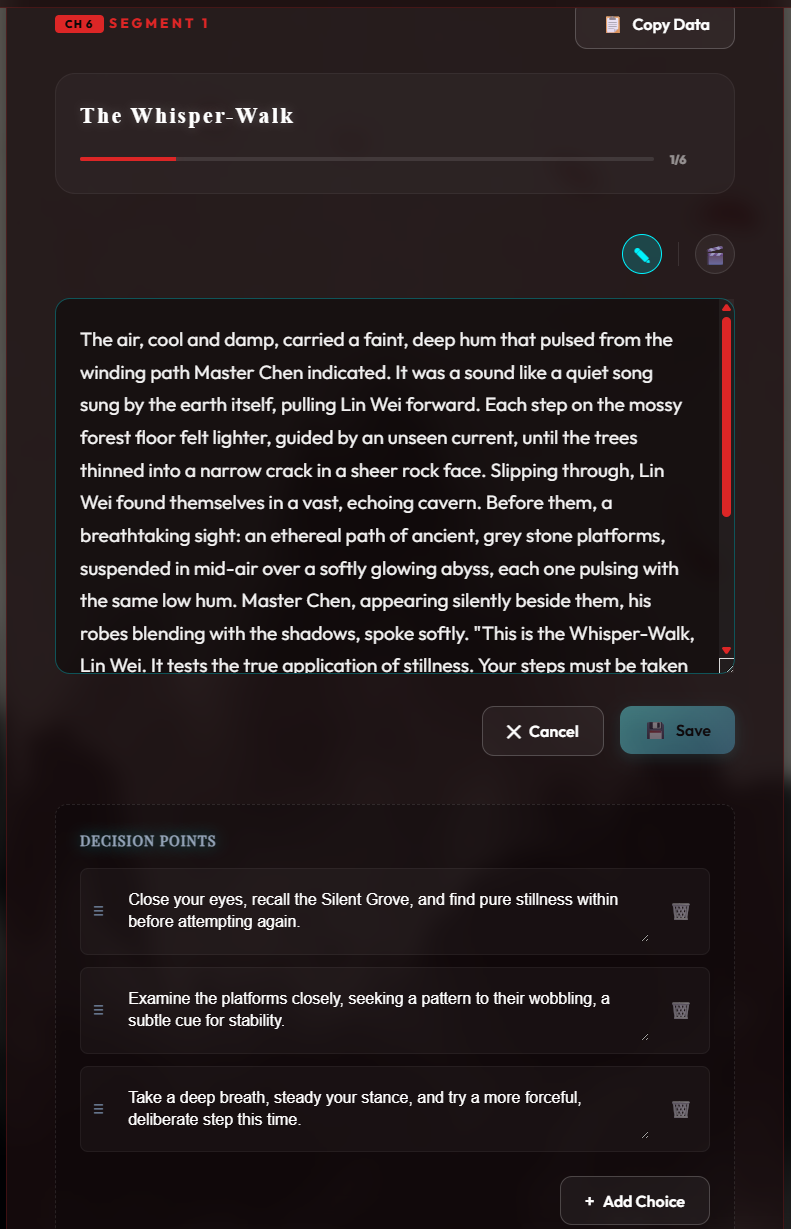 Caption: The main writing interface where prose, choices, and character vitals converge.
Caption: The main writing interface where prose, choices, and character vitals converge.
4. Forking the Narrative
The true power of the multiverse lies in its ability to handle divergent canons. If a reader—or the original author—wants to explore a “What If?” scenario from a published chapter, they can initiate a Fork.
- Timeline Settings (RHP): Located in the Right-Hand Panel, the Timeline Settings include a toggle to “Allow Forking.” Enabling this unlocks the current segment for divergence.
- Lineage Tracking: When a story is forked, the system records the
originalAuthorIdandforkedFromstory ID. This ensures that even as the narrative spirals into new directions, the credit and causal history trace back to the source.
 Caption: The “Forked From” indicator in the header, preserving credit to the original author while allowing new divergence.
Caption: The “Forked From” indicator in the header, preserving credit to the original author while allowing new divergence.
Limitations & Future Work
While functional, Living Storybook is an evolving system with known boundaries:
- Multi-User Conflicts: Currently follows a “Last-Writer-Wins” model; future iterations will include real-time collaboration markers.
- Context Limits: Long-term memory is currently bounded by a sliding-window summarization; I’m exploring Vector Embeddings for more permanent thematic memory.
- Deterministic vs. Creative: The
Guardiansometimes over-regulates prose. Finding the perfect balance between “Canon Safety” and “Creative Flair” remains a primary tuning focus.
Terminology Glossary
To help navigate the multiverse, here are the key concepts used throughout this deep dive:
- Edition: A published, immutable snapshot of a specific timeline.
- Chronicle: A user-facing reading experience derived from a canonical path.
- Temporally Locked: A node that cannot be edited because it is part of a published edition (preserving the past).
- Narrative DNA: The set of world-rules, style guides, and character profiles that define a story’s “Soul.”
- Backward-Linked: The \( O(depth) \) pathing model where segments reference their parent, not their children.
Conclusion
Living Storybook isn’t just a writing tool; it’s an experiment in persistent digital existence. By combining Gemini’s reasoning with LangGraph’s stateful orchestration, I’ve moved from “AI Text Generators” to “AI Narrative Universes.”