In this post, I’ll walk you through how I built HDB Agent, an Agentic AI system with tool orchestration for Singapore’s HDB market analysis.
Unlike my previous post on Deploying KServe on OKE , this time I reused the same custom XGBoost model — but deployed it to AWS Lambda for serverless resale price prediction.
Prerequisites
Start by installing the AWS Bedrock AgentCore Starter Toolkit :
pip install aws-bedrock-agentcore-starter-toolkitEnsure that AWS CLI and SAM CLI are installed and configured properly:
agentcore --help
# Usage: agentcore [OPTIONS] COMMAND [ARGS]...
# BedrockAgentCore CLI
aws --version
# aws-cli/2.30.5 Python/3.13.7 Windows/11 exe/AMD64
aws configure
# AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE
# AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
# Default region name [None]:
# Default output format [None]:
sam --version
# SAM CLI, version 1.144.0AWS Well-Architected Architecture
The following diagram illustrates the event-driven, serverless architecture integrating multiple AWS services.
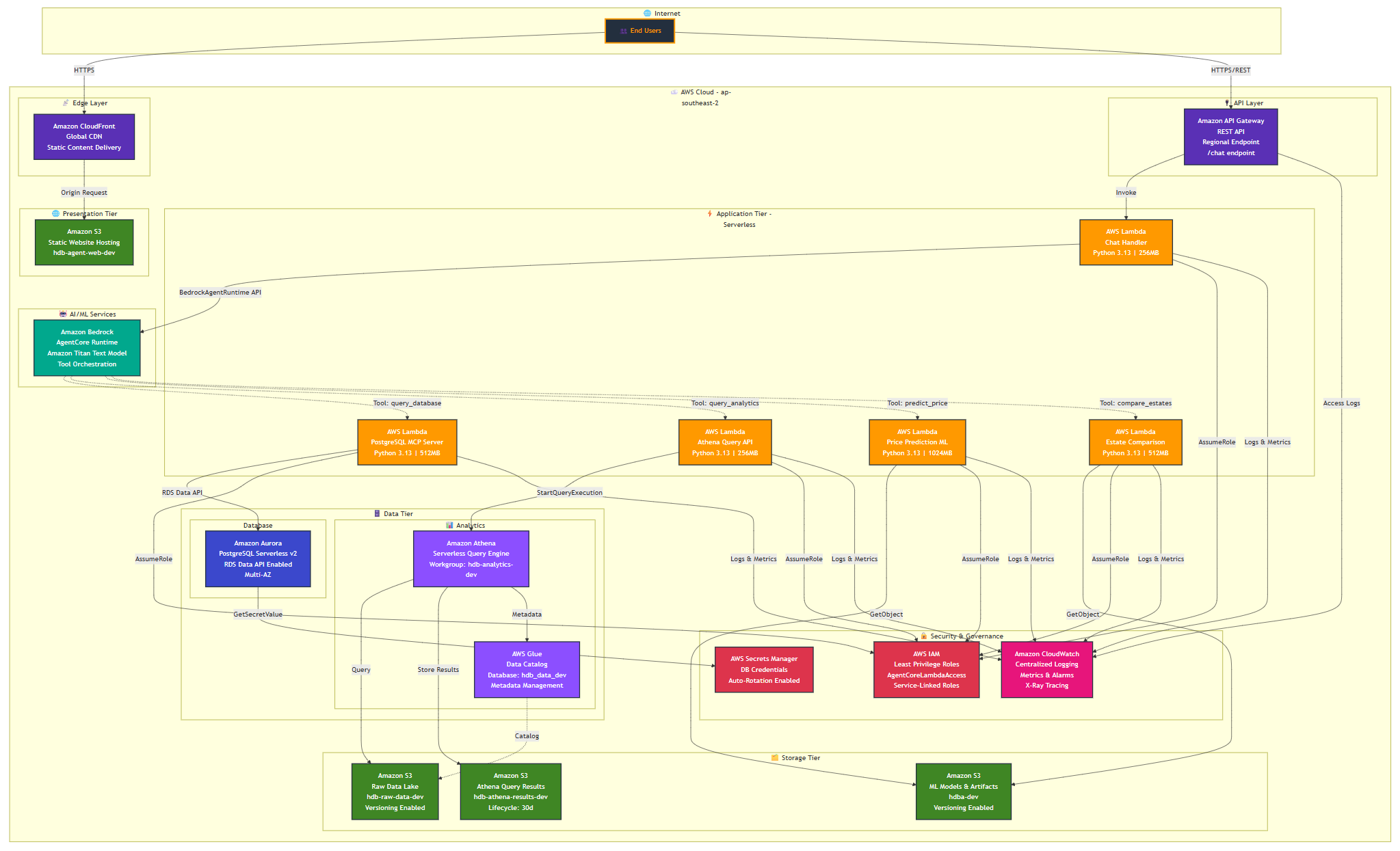
Infrastructure as Code Setup
The deployment leverages AWS CloudFormation using a modular, nested-stack approach. The root template acts as the orchestrator, deploying smaller, purpose-built nested stacks for individual services.
This modular approach promotes reusability, maintainability, and scalability — a best practice for managing complex cloud systems.
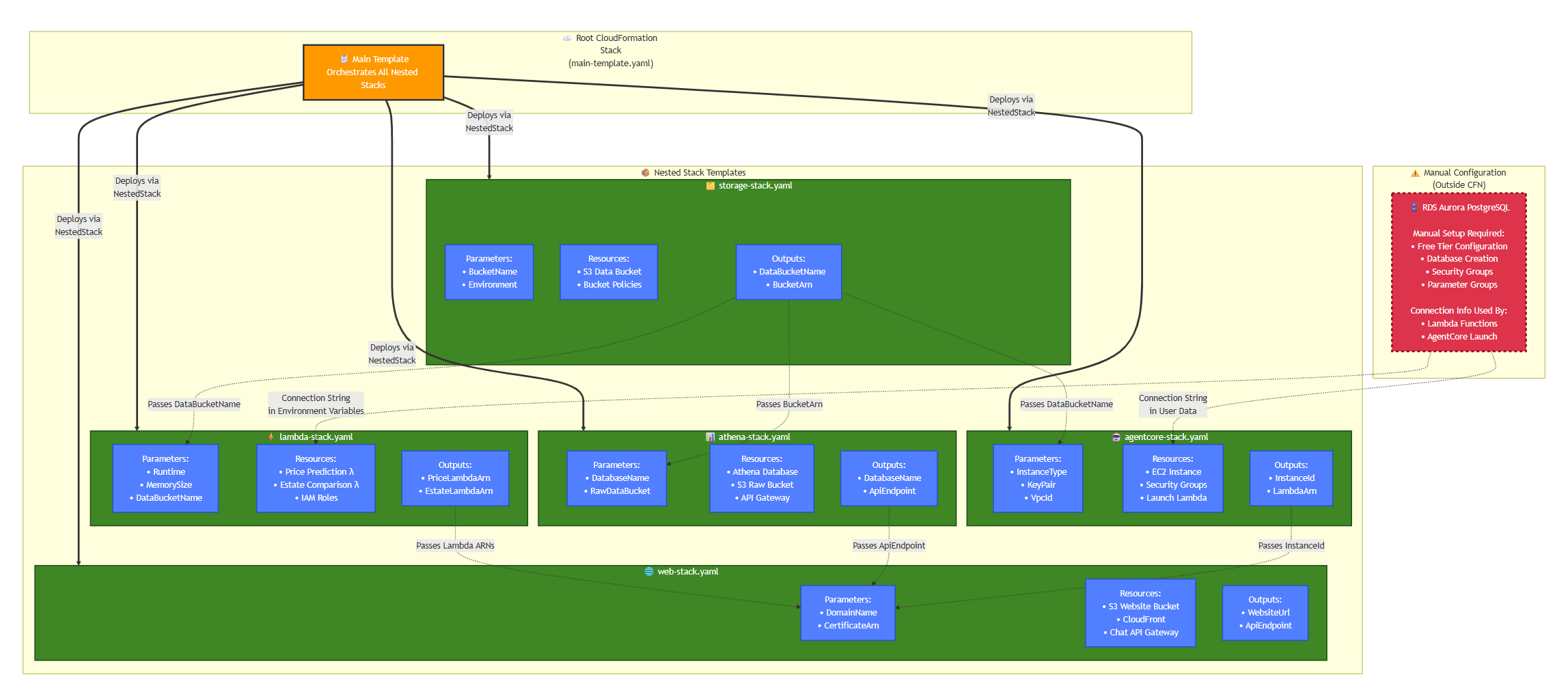
1. The Orchestrator: Root Stack
The root template defines environment parameters and delegates deployment to sub-stacks.
Environment Configuration Example:
Parameters:
Environment:
Type: String
Default: dev
AllowedValues:
- dev
- staging
- prodA single Environment parameter is passed down across all stacks, ensuring consistency and flexibility between dev, staging, and prod environments.
Nested Stack Example:
Resources:
StorageStack:
Type: AWS::CloudFormation::Stack
Properties:
TemplateURL: template-storage.yaml
Parameters:
Environment: !Ref Environment2. The Foundation: Storage Stack
- Purpose: Creates the core S3 bucket for data storage — including raw uploads, processed datasets, and ML model artifacts.
- Significance: Centralized, durable, and cost-efficient data management with lifecycle and access policies decoupled from compute layers.
3. The Hybrid Core: AgentCore Stack
- Purpose: Deploys infrastructure for the AWS Bedrock AgentCore — IAM roles, CloudWatch logging, and security configurations.
Configuration Example:
AgentCoreStack:
Type: AWS::CloudFormation::Stack
Properties:
TemplateURL: template-agentcore.yaml
Parameters:
Environment: !Ref Environment
AgentName: hdb-strands-agent
FastAPIEndpoint: https://15pp6zg4ua.execute-api.ap-southeast-2.amazonaws.com/ProdThe hybrid deployment approach combines:
- CloudFormation for stable AWS resources (IAM, S3, VPC)
- AgentCore CLI for agile deployment of evolving agent logic
This separation ensures fast iteration cycles while maintaining infrastructure stability.
4. The Data Brain: Athena Stack
- Purpose: Provides serverless querying over S3 data using AWS Athena and Glue Catalog for schema management.
- Significance: Enables SQL analytics without provisioning servers — ideal for exploratory and ad-hoc data analysis.
5. The Intelligence: Lambda Stack
Purpose: Hosts serverless machine learning functions for price prediction and estate comparison.
Dependency Example:
LambdaStack:
Type: AWS::CloudFormation::Stack
DependsOn: StorageStack
Properties:
TemplateURL: template-lambda.yamlThe dependency ensures S3 is available before Lambda creation, maintaining data consistency.
- Benefit: Lambda provides on-demand scaling and cost efficiency, paying only for compute time.
6. The User Interface: Web Stack
- Purpose: Delivers the user-facing static site (React/Vue.js) via S3 + CloudFront, with API Gateway integration for the chat interface.
- Benefit: Cleanly separates front-end UX from backend intelligence, promoting modular development and CI/CD efficiency.
7. The Integration Glue: Stack Outputs
- Purpose: Enables cross-stack communication through exports and imports.
Outputs:
DataBucketName:
Description: Name of the S3 bucket
Value: !GetAtt StorageStack.Outputs.DataBucketName
Export:
Name: !Sub "${AWS::StackName}-DataBucket"This pattern ensures loose coupling between components while maintaining interoperability.
8. The Hybrid Database Layer: RDS Aurora PostgreSQL
-
Purpose: Manually configured RDS Aurora PostgreSQL instance for transactional and sessional data.
-
Why Manual?
- Optimized for AWS Free Tier
- Faster schema iteration during early development
- Clear cost control
- Separation of persistent state from automated infrastructure
-
Integration:
- AgentCore uses RDS for agent state and conversation tracking
- Lambda uses RDS for transactional data
- Athena continues to handle large-scale analytical workloads
- This forms a multi-tiered data strategy:
- S3 + Athena: Analytical layer
- RDS Aurora: Transactional layer
- Lambda: Compute & inference layer
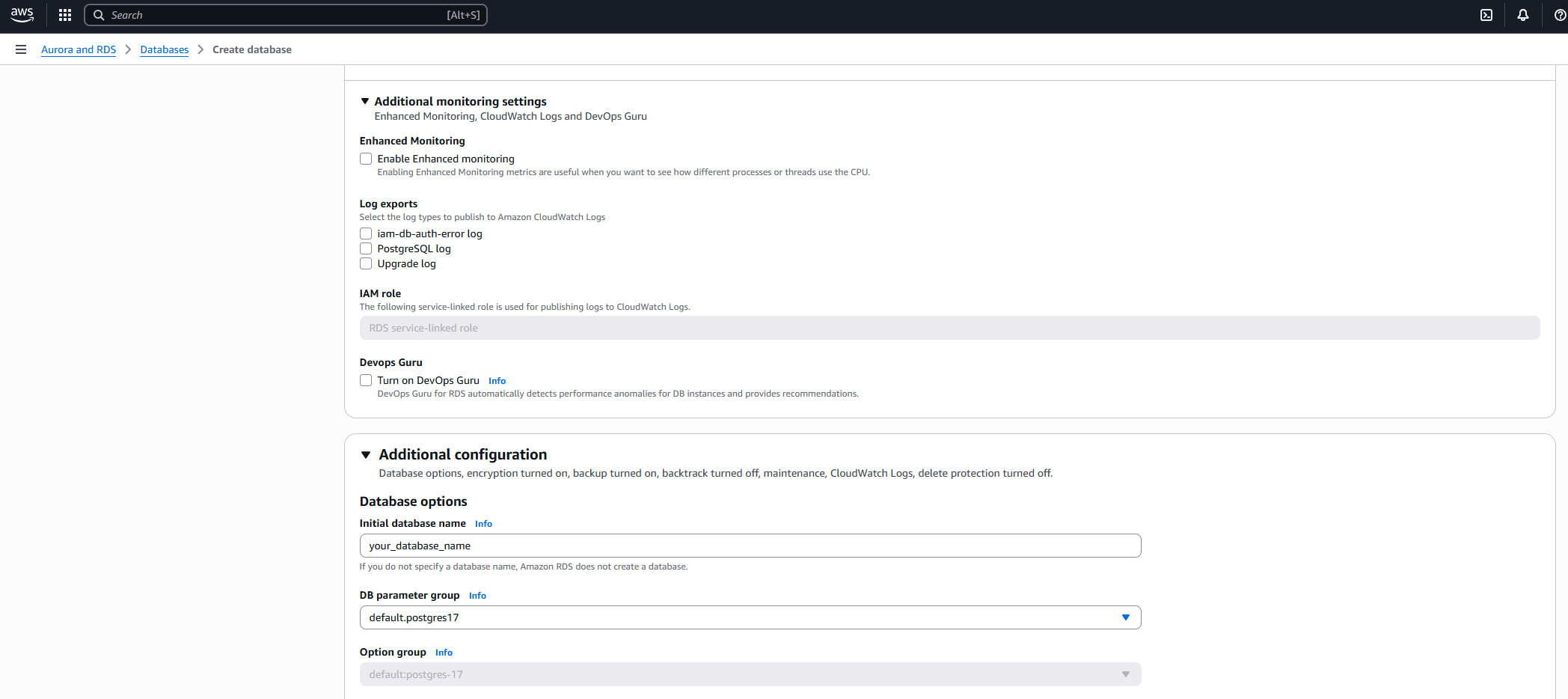
RDS Setup Gotcha: Don’t Skip the Database Name
While configuring the RDS instance manually, I discovered a subtle but important setup detail: if you don’t specify an initial database name during creation, AWS RDS won’t create one automatically — even though the setup completes successfully.
Although this behavior is noted in the AWS console under Database options, it’s easy to miss when moving quickly through the wizard. The result is an instance with no default database, requiring deletion and recreation to fix.
To avoid this, make sure to set the “Initial database name” field during RDS creation.
Deployment Command
To deploy the full stack:
cd infra
sam build
sam deploy --guided --stack-name hdb-agent --region ap-southeast-2ap-southeast-2 (Sydney).
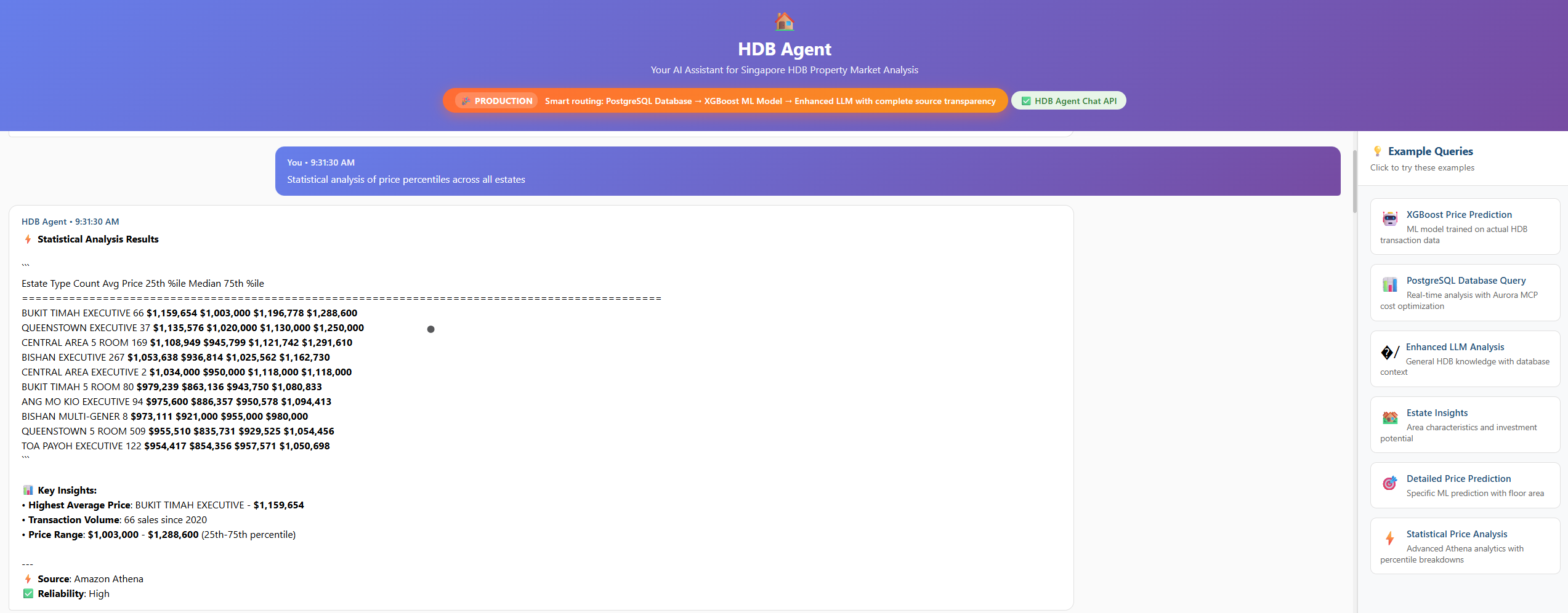
Intelligent Query Routing: The Brain Behind HDB Agent
The Intelligent Query Router dynamically directs user queries to the most suitable backend service based on intent, ensuring optimal performance and cost efficiency.
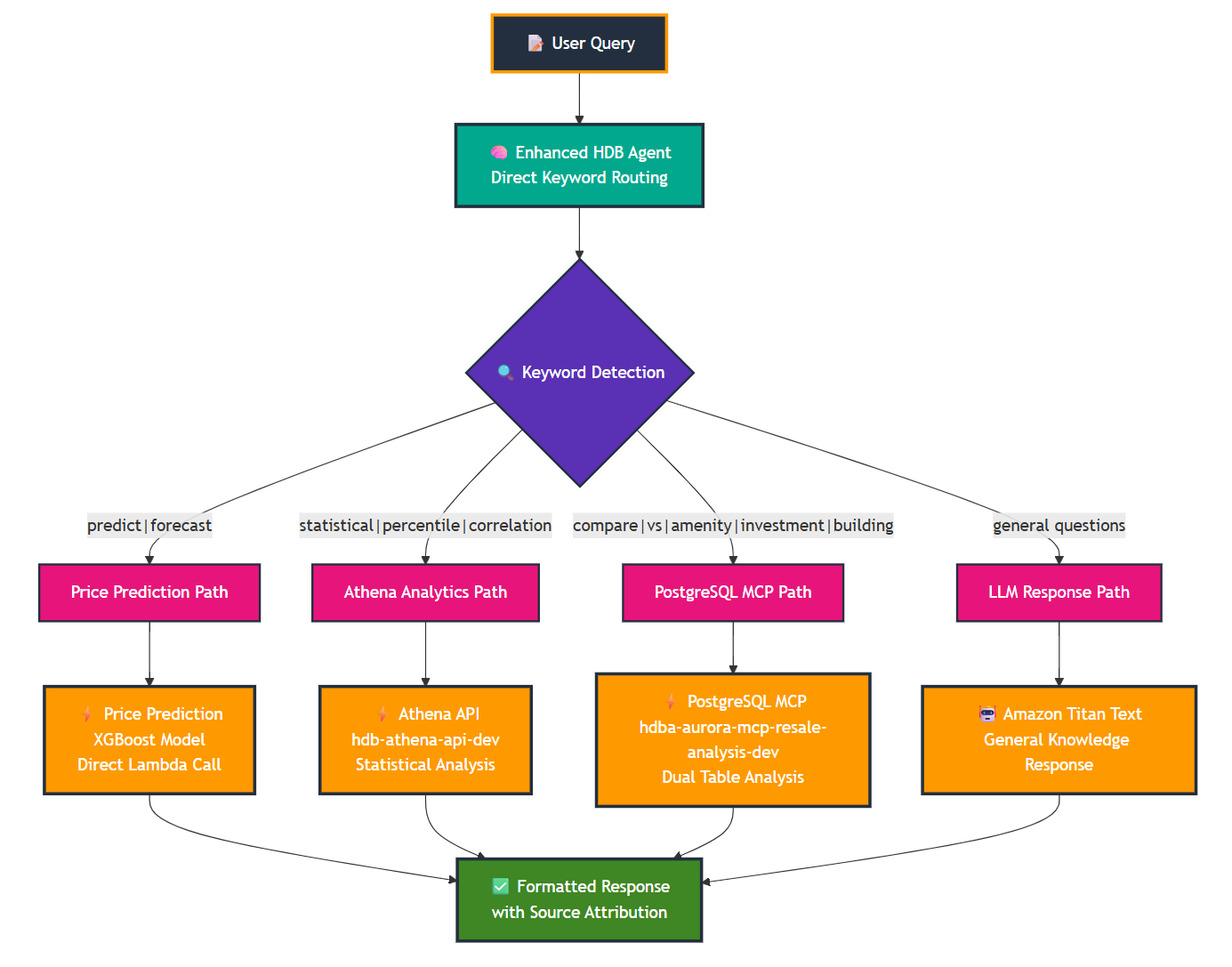
1. 🎯 Price Prediction Path
Triggers: predict, forecast, cost, future price
Routes to the XGBoost ML model for accurate resale price prediction.
Example: “Predict price for 4-room flat in Bishan”
2. 📊 Athena Analytics Path
Triggers: percentile, correlation, trend, statistics
Routes to Amazon Athena for large-scale analytical SQL queries.
Example: “Statistical analysis of price percentiles across all estates”
Estimated Cost: ~$0.59/query (complex analytics)
3. 🗄️ PostgreSQL MCP Path
Triggers: compare, vs, amenity, list, find
Routes to the PostgreSQL MCP server for estate comparisons and amenity scoring.
Example: “Compare Bishan vs Tampines”
Estimated Cost: ~$0.01/query (≈98% cost savings vs Athena)
4. 🤖 LLM Response Path
Triggers: General or unclassified queries
Routes to Amazon Bedrock’s Titan Text model for natural, contextual responses.
Example: “What makes Tampines a good estate?”
In Action
Live Demo: HDB Agent