
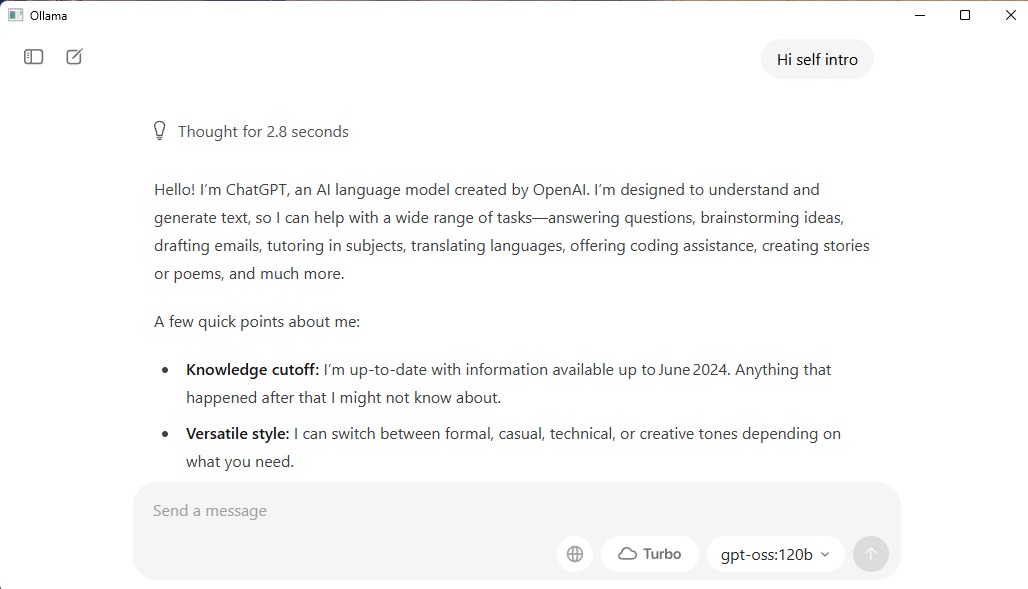
With the recent release of Introducing gpt-oss from OpenA, I decided to put it to the test on my newly purchased AMD Ryzen AI Max+ 395 mini PC. I allocated 96 GB of 128 GB RAM exclusively to the GPU to see how well it could handle the model.
My goal: build a simple chat application that sends a single query to multiple models (up to five) and displays all responses in one unified interface.
Prerequistes
The first step was setting up Cursor , an AI-powered code editor. After signing up for the free plan (which comes with limited completions and agents), I installed the Kilo Code plugin for extended coding assistance.
Running gpt-oss with Ollama
I used Ollama to download and run the gpt-oss 120B model.
To serve the model locally, I ran:
set OLLAMA_HOST=0.0.0.0
set OLLAMA_ORIGINS="*"
ollama serve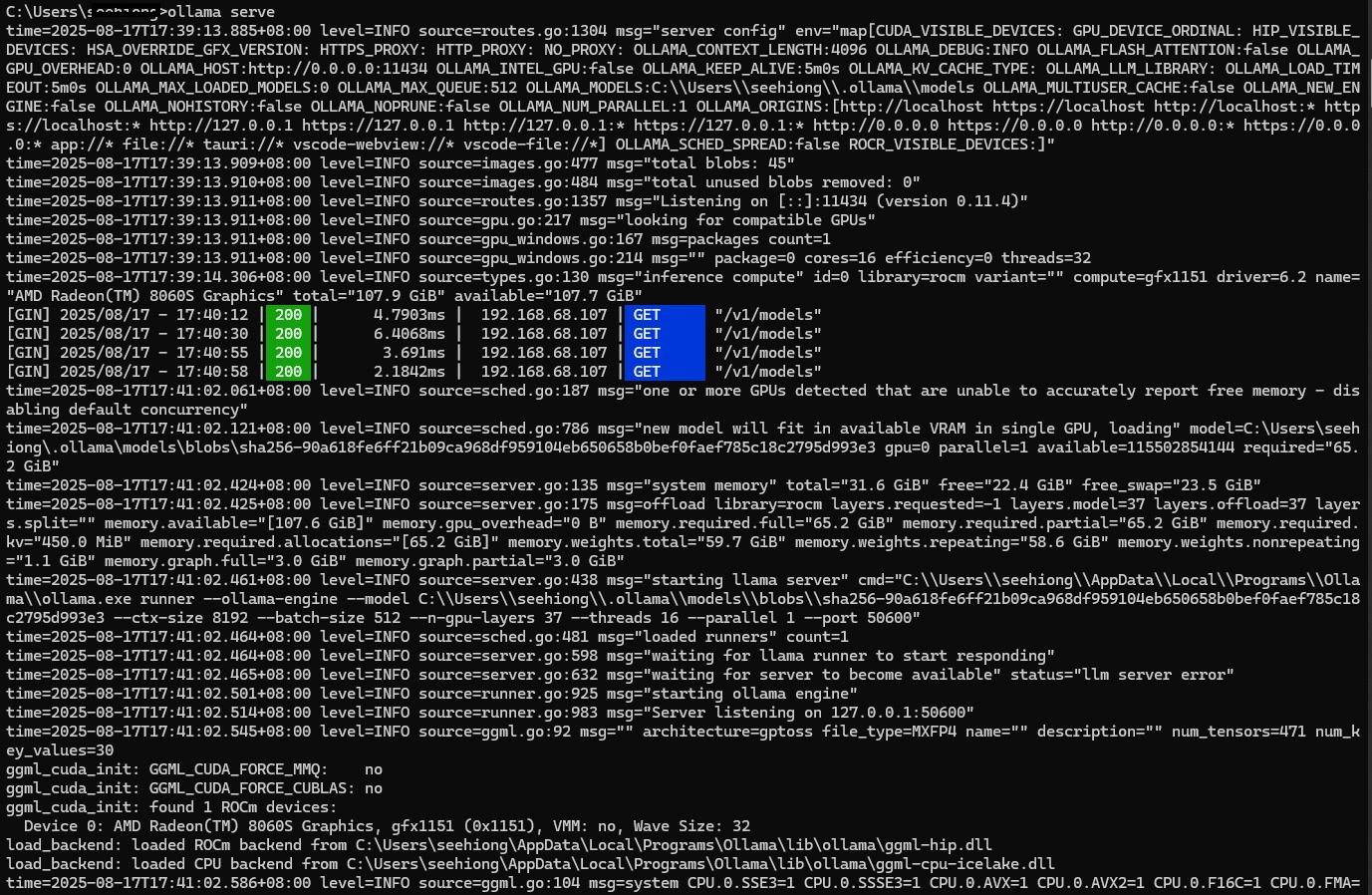
ollama serve.
Vibe Coding with Cursor
With Cursor’s free plan, I began with this vibe coding prompt:
Create a modern single-page web application (SPA) for a chat system with the following features:
1. **Frontend UI**
- Clean, minimalistic, and responsive chat interface
- Input box for user questions
- Display area for model responses, grouped by model name
- Option to select number of models to query (1 to 5)
- Loading indicators while waiting for responses
- Support for markdown rendering in model replies
2. **Backend Logic (Serverless Function)**
- Uses OpenRouter API to query multiple LLMs concurrently
- Accepts user input and number of models to query
- Sends the same prompt to selected models via OpenRouter
- Waits for responses and returns them as a structured JSON payload
- Handles timeouts and partial responses gracefully
3. **Model Selection**
- Default models include: GPT-3.5, Claude 2, Mistral, LLaMA 2, Gemini
- Models can be hardcoded or dynamically fetched from OpenRouter
4. **Tech Stack**
- Frontend: React + Tailwind CSS (or similar modern stack)
- Backend: Serverless function (e.g., Vercel, Netlify, or Supabase Edge Functions)
- API: OpenRouter with OpenAI-compatible endpoints
5. **Extensibility**
- Easy to add/remove models
- Modular architecture for future features like chat history, user auth, or feedback
Generate the full codebase including:
- React components for UI
- Serverless function to handle OpenRouter requests
- Utility functions for concurrent model querying
- Basic styling and layoutCursor + Kilo Code generated a decent foundation for the app with minimal effort.
Integrate Kilo Code with Ollama
Next, I attempted to pair Kilo Code with my local Ollama instance. Under Settings → Providers → API Provider, I selected OpenAI Compatible, entered my Mini PC’s IP as the Base URL, and used a placeholder API key:
http://192.168.68.120:11434/v1I then created a custom model gpt-oss:120b and tested with:
curl http://192.168.68.120:11434/api/generate -H "Content-Type: application/json" -d "{ \"model\": \"gpt-oss:120b\", \"prompt\": \"How are you today?\" }"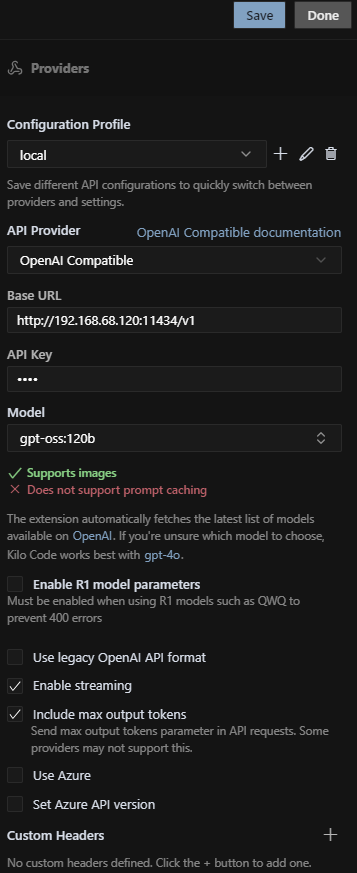
Integrate Kilo Code with OpenRouter
Switching to OpenRouter was smoother. This time, I selected OpenRouter as the provider, entered my API key, and chose from the available models (both free and paid).
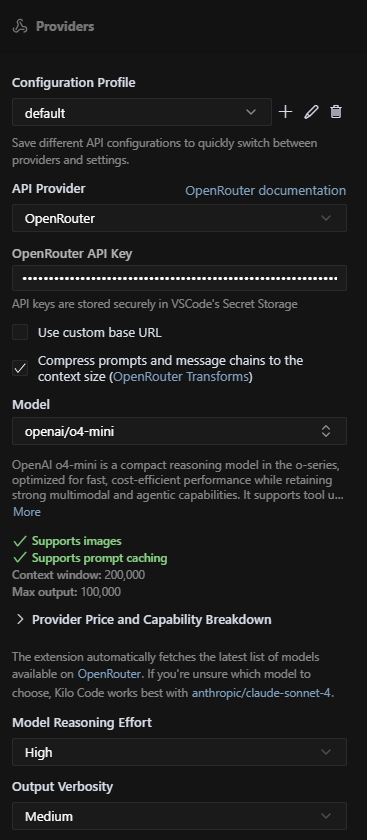
Kilo Code worked seamlessly with multiple models, editing files via both inline edits and diffs.
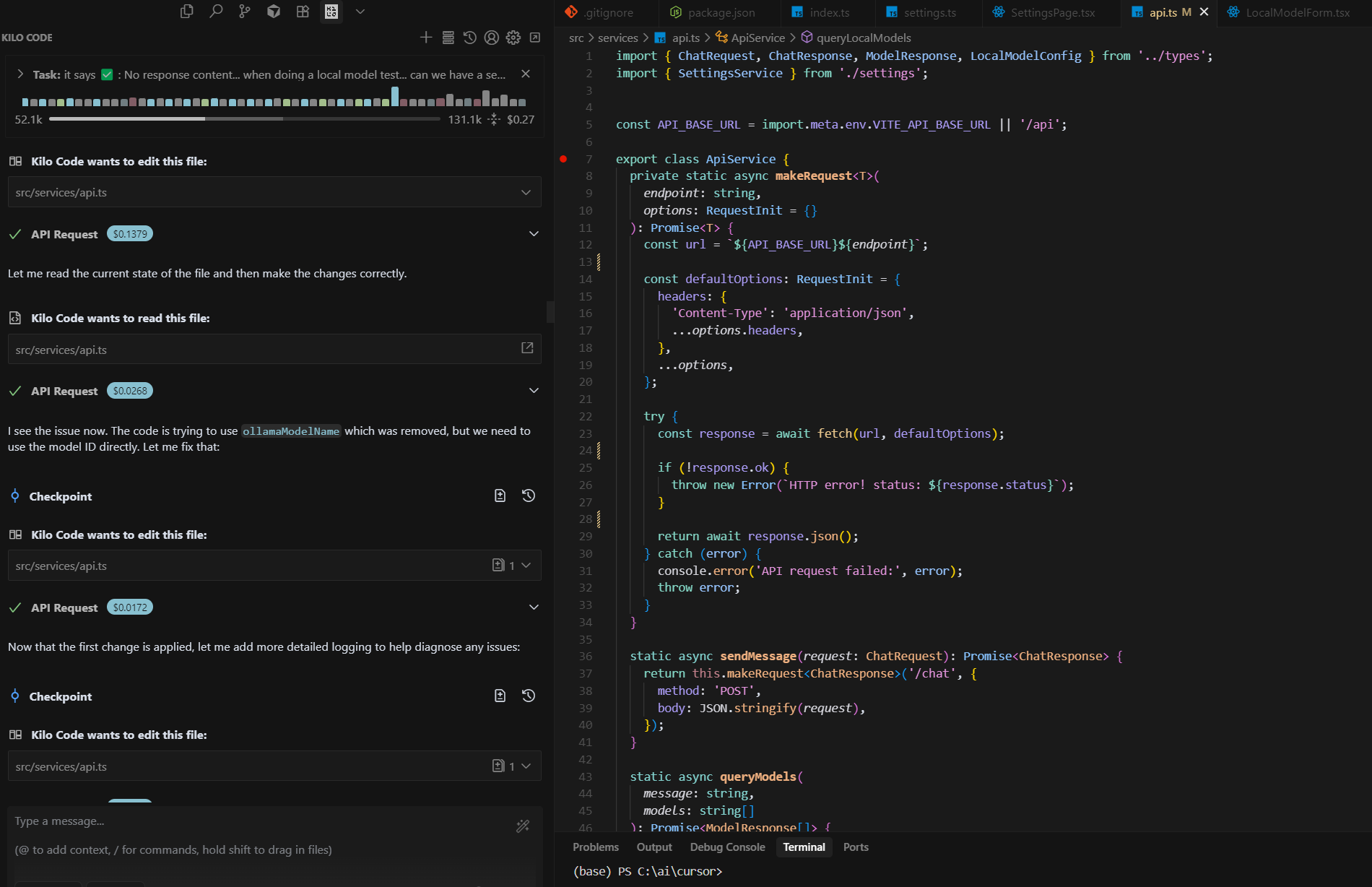
Example using the free DeepSeek model:
Multi-Model Chat Application
After some trial-and-error (and a few resets), I finally got the multi-model chat app working end-to-end.
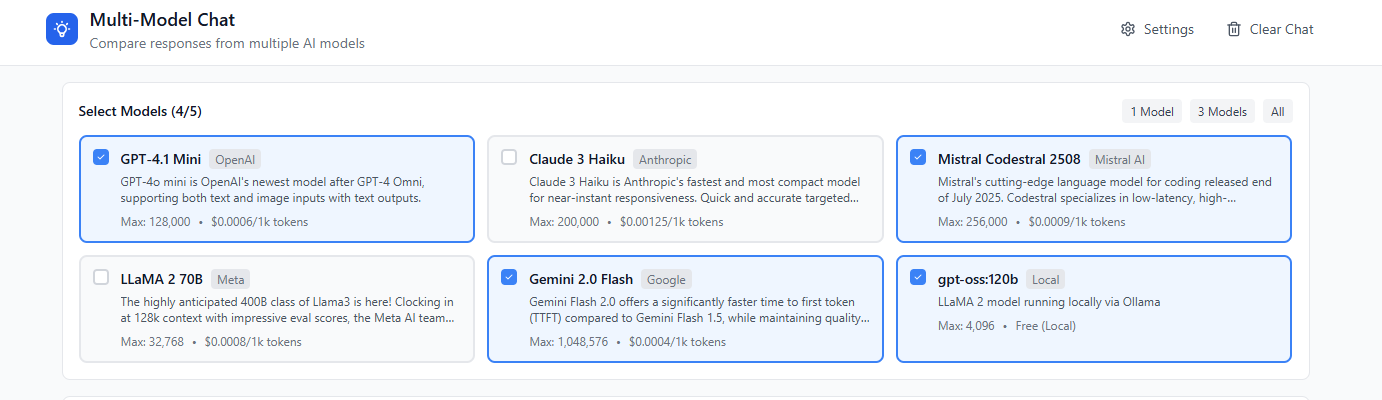
Here’s an example query sent to 4 models in parallel:
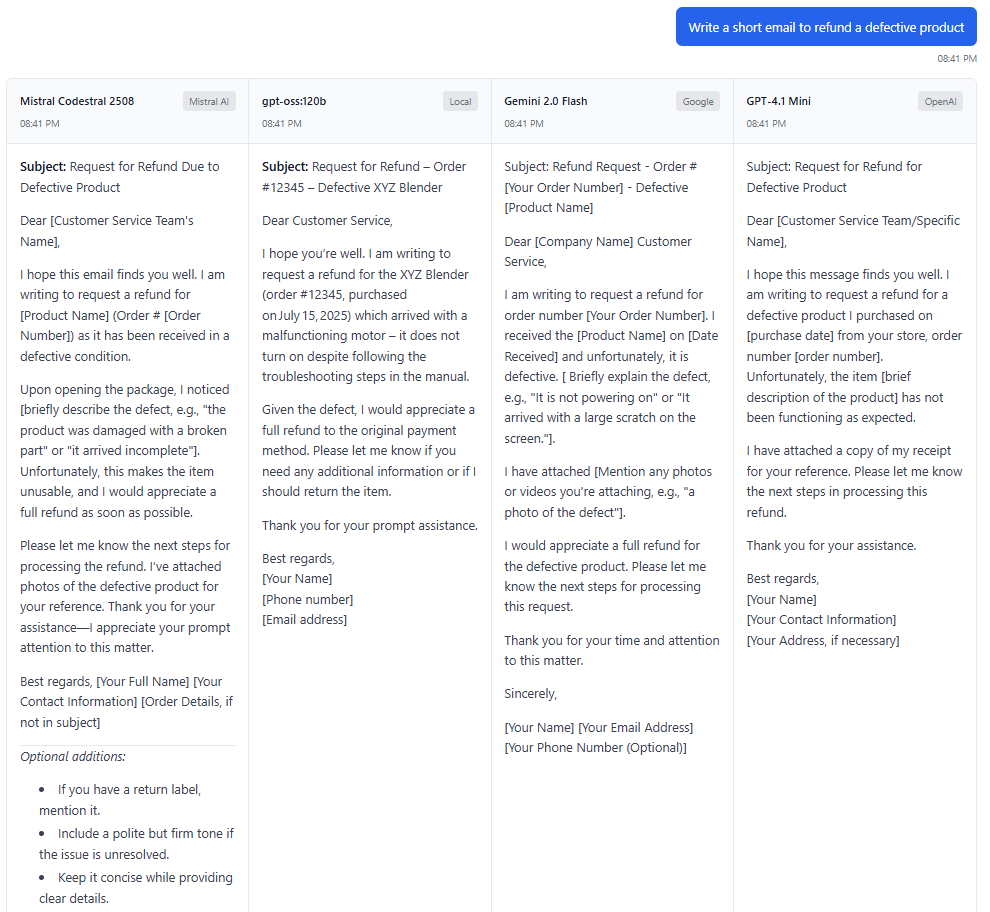
With this setup, I no longer need to open multiple browser tabs and paste the same prompt repeatedly—one query fans out to all selected models instantly.
That said, local gpt-oss is still significantly slower compared to cloud-hosted commercial models.
What’s Next
I’ll continue experimenting with ways to optimize performance (especially for local inference).
👉 Repo link: https://github.com/seehiong/multi-model-chat
Have fun exploring, and feel free to fork and customize!