Unleashing the Power of LLaMA Server in Docker Container
Having recently completed the enlightening Generative AI with Large Language Models course, where we gained invaluable knowledge and hands-on skills, we are now excited to share an exhilarating experience of running the LLaMA model in a Dockerized container.
In this guide, we’ll walk you through the setup and demonstrate how to unleash the full potential of running LLaMA Server within a Docker container.
The Setup
Before we delve into the magic of LLaMA, let’s set up our application structure. To ensure smooth execution, we’ve structured our project as follows:
|── main.py
├── Dockerfile
├── requirements.txt
|── WizardLM-7B-uncensored.ggmlv3.q5_0.bin
The main.py file contains the heart of our application, while the Dockerfile and requirements.txt facilitate the containerization process and handle dependencies. The WizardLM-7B-uncensored.ggmlv3.q5_0.bin model can be obtained from here.
Starting Simple
Let’s begin with a simple setup of our FastAPI application in the main.py file:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def index():
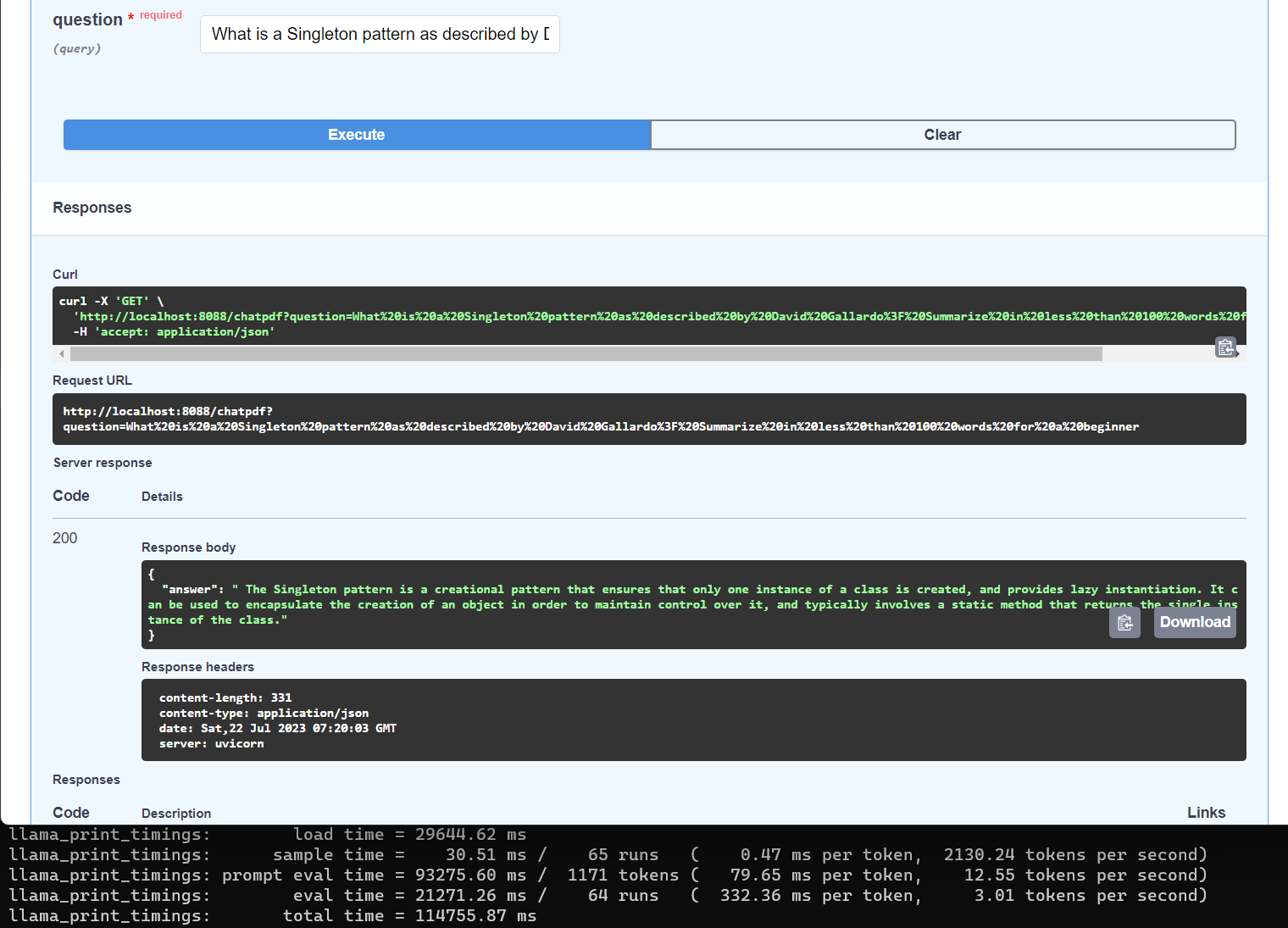
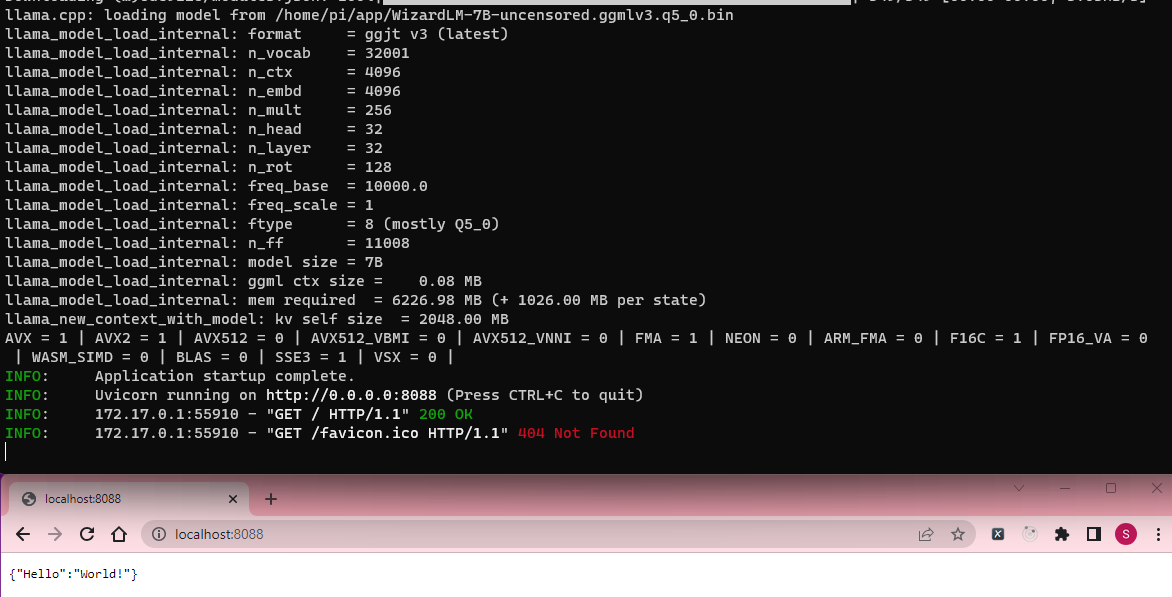
return {"Hello": "World!"}
Next, we’ll tackle the Dockerfile to ensure smooth containerization:
FROM python:3.11
WORKDIR /app
COPY ./requirements.txt /app/requirements.txt
RUN pip install --no-cache-dir -r /app/requirements.txt
RUN useradd -m -u 1000 pi
USER pi
ENV HOME=/home/pi
WORKDIR $HOME/app
COPY --chown=pi . $HOME/app
EXPOSE 8088
CMD python -m uvicorn main:app --host 0.0.0.0 --port 8088
Our requirements.txt file lists the necessary dependencies for our LLaMA Server:
fastapi==0.85.1
requests==2.28
uvicorn==0.18.3
langchain==0.0.234
chromadb==0.3.29
pypdf==3.12.2
llama-cpp-python==0.1.72
sentence_transformers==2.2.2
Let’s harness the true power of LLaMA by containerizing it with Docker. Follow these simple steps to get started:
- Change directory into your project folder (e.g., c:\ai\docker)
cd c:\ai\docker
- Build the Docker image for our FastAPI application and tag it as fastapi
docker build . -t fastapi
- Run the Docker container, exposing port 8088 to access our LLaMA server
docker run --rm -it -p 8088:8088/tcp fastapi
Building the AI Chatbot: From PDF Loading to FastAPI Integration
In our previous post, we explored the exciting world of building a chatbot tailored specifically to interact with PDF files. From here on, we will repackage it, by importing all the essential dependencies that make this magic possible:
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.llms import LlamaCpp
from langchain.chains.question_answering import load_qa_chain
- We’ll kick things off by loading the Java Design Patterns 101 PDF using our handy PDF loader:
def load():
loader = PyPDFLoader("/home/pi/app/java-design-patterns-101.pdf")
return loader.load()
- To ensure seamless processing, we’ll split the texts into manageable chunks:
def split():
text_splitter = CharacterTextSplitter(chunk_size=1500, separator="\n")
return text_splitter.split_documents(app.document)
- Next, we’ll leverage the power of Chroma to persist the index for faster retrieval:
def persist():
vectordb = Chroma.from_documents(app.texts, persist_directory="/home/pi/app/chroma")
vectordb.persist()
return vectordb
- Now comes the exciting part! We’ll put our AI chatbot to work and answer your queries:
def query(question):
docs = app.retriever.get_relevant_documents(query)
answer = app.chain.run(input_documents=docs, question=question)
return answer
- With FastAPI as our backbone, we’ll orchestrate the entire process by executing the following code on startup:
@app.on_event("startup")
async def startup_event():
app.document = load()
app.texts = split()
app.embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
app.vectordb = persist()
app.retriever = app.vectordb.as_retriever()
app.llm = LlamaCpp(model_path="/home/pi/app/WizardLM-7B-uncensored.ggmlv3.q5_0.bin", verbose=True, n_ctx=4096)
app.chain = load_qa_chain(app.llm, chain_type="stuff")
- It’s time to experience the power of our AI chatbot firsthand! Our new endpoint, “/chatpdf,” is all you need to interact with your Java Design Patterns 101 PDF:
@app.get("/chatpdf")
async def chat_pdf(question):
answer = query(question)
return {"answer": answer}
Our Docker environment loads the LLM and downloads the required model, setting the stage for seamless interactions with your PDFs.
Chatbot for pdf in docker
In this final segment, we unveil the full potential of our AI chatbot for PDFs, now fully Dockerized for seamless deployment. The main.py file is where the magic happens, integrating the power of FastAPI, HuggingFace embeddings, and the remarkable LLaMA model. Let’s take a closer look at the finalized code:
from fastapi import FastAPI
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.llms import LlamaCpp
from langchain.chains.question_answering import load_qa_chain
app = FastAPI()
@app.get("/")
async def default():
return {"Hello": "World!"}
@app.get("/chatpdf")
async def chat_pdf(question):
answer = query(question)
return {"answer": answer}
@app.on_event("startup")
async def startup_event():
app.document = load()
app.texts = split()
app.embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
app.vectordb = persist()
app.retriever = app.vectordb.as_retriever()
app.llm = LlamaCpp(model_path="/home/pi/app/WizardLM-7B-uncensored.ggmlv3.q5_0.bin", verbose=True, n_ctx=4096)
app.chain = load_qa_chain(app.llm, chain_type="stuff")
def load():
loader = PyPDFLoader("/home/pi/app/java-design-patterns-101.pdf")
return loader.load()
def split():
text_splitter = CharacterTextSplitter(chunk_size=1500, separator="\n")
return text_splitter.split_documents(app.document)
def persist():
vectordb = Chroma.from_documents(app.texts, app.embeddings, persist_directory="/home/pi/app/chroma")
vectordb.persist()
return vectordb
def query(question):
docs = app.retriever.get_relevant_documents(question)
answer = app.chain.run(input_documents=docs, question=question)
return answer
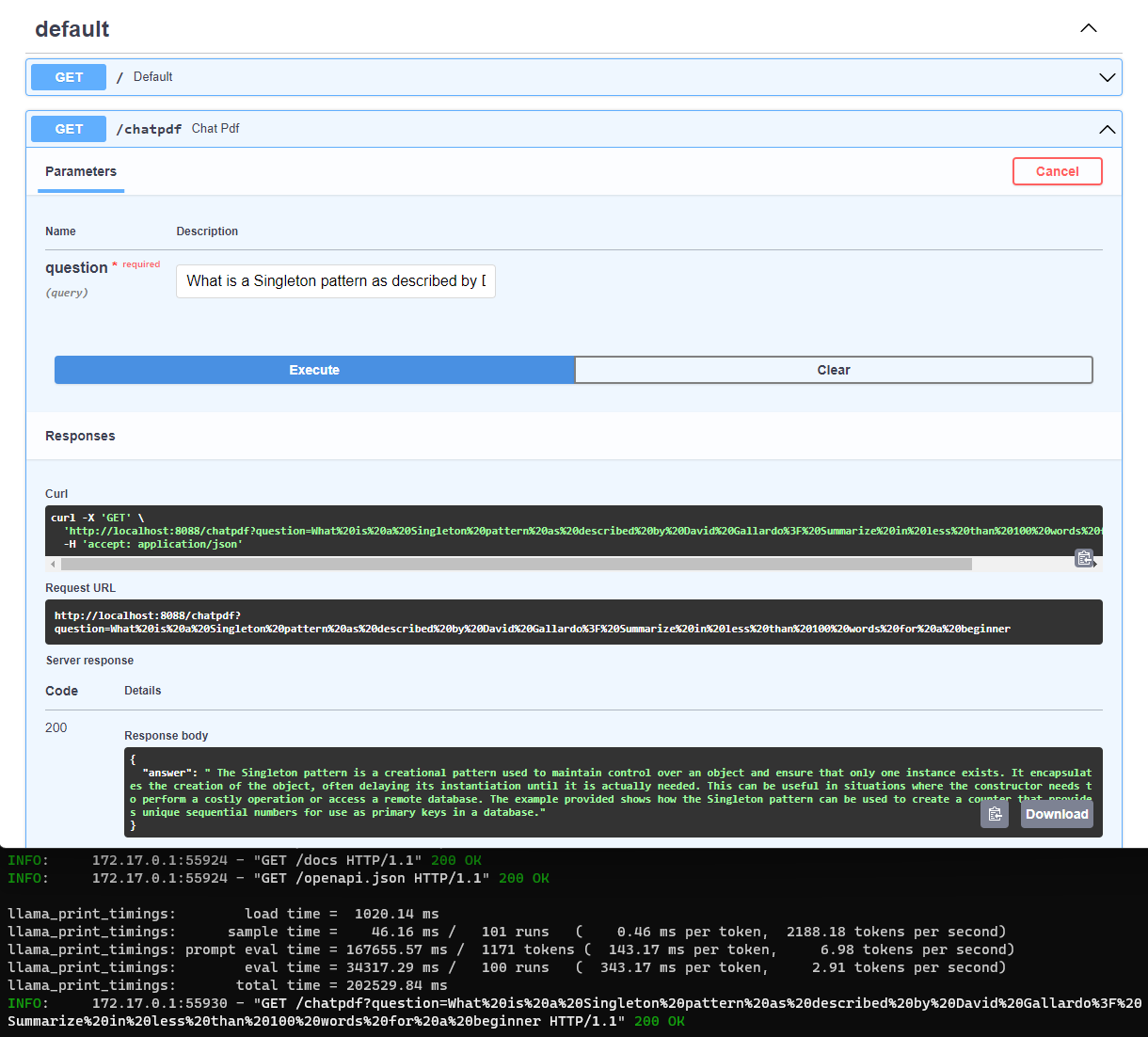
Now, it’s time to experience the AI chatbot in action! Navigate to http://localhost:8088/docs (or your host’s IP address) and enter the sample query we used in the previous post:
What is a Singleton pattern as described by David Gallardo? Summarize in less than 100 words for a beginner
The result is quite good in that the inferencing time is around 3 minutes!
Boosting Performance with OpenBLAS (optional)
To enhance the performance of your LLaMA Server even further, you can take advantage of OpenBLAS, a highly optimized library for numerical computations. By making a few tweaks to your Dockerfile and removing llama-cpp-python==0.1.72 from requirements.txt, you can unlock the power of OpenBLAS for accelerated inferencing.
Let’s incorporate the necessary changes in your Dockerfile:
FROM python:3.11
RUN python -m pip install --upgrade pip
RUN apt-get update && apt-get install -y libopenblas-dev
RUN CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" FORCE_CMAKE=1 pip install llama-cpp-python
# ... (Other steps in the Dockerfile) ...
With OpenBLAS enabled (-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS), the LLaMA Server’s inferencing time experiences a significant reduction, taking around 1 minute to produce results.
Witness the difference in performance for yourself: