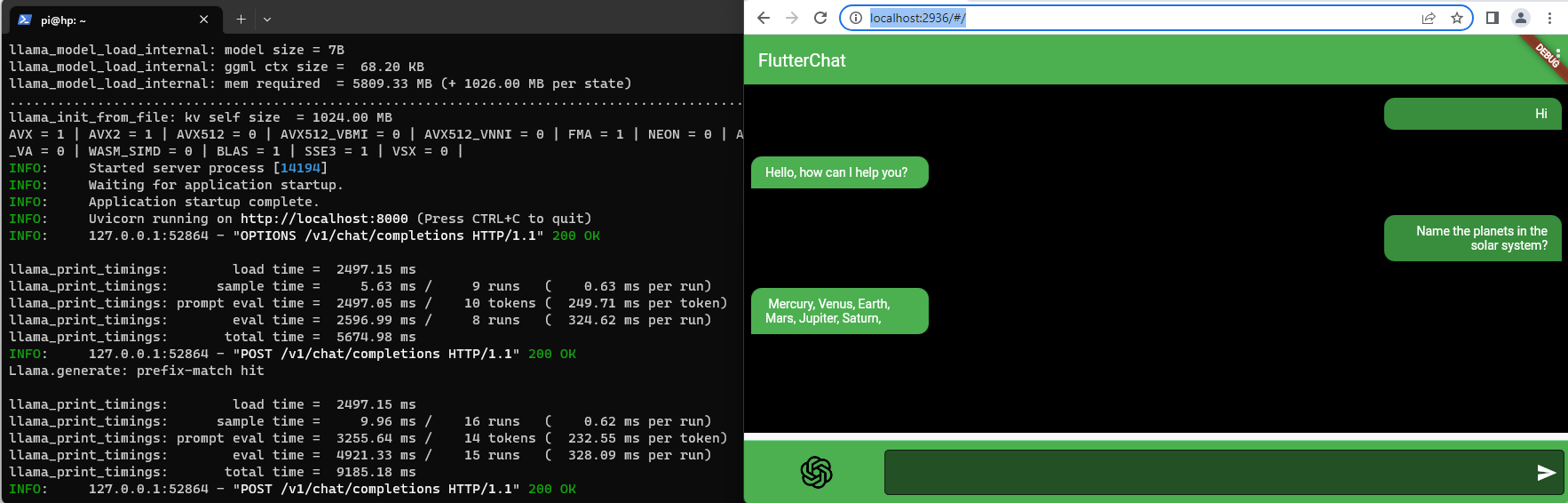
Running LLaMA server in local machine
Referencing the previous post, we will run a web server which aims to act as a drop-in replacement for the OpenAI API, which can in turn be used by byogpt.
Preparation
(3 mins)
Pipenv aims to help users manage environments, dependencies and imported packages and I will be using it in this guide.
pip install pipenv uvicorn fastapi sse_starlette
pipenv shell
This is the command to install the server:
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python==0.2.24 --upgrade --force-reinstall --no-cache-dir
To run the server:
python3 -m llama_cpp.server --model ~/phi-2.Q4_K_M.gguf
Tunnel to Server
(2 mins)
Since I am working from a windows PC, download and install PuTTY, an SSH and telnet client for Windows platform.
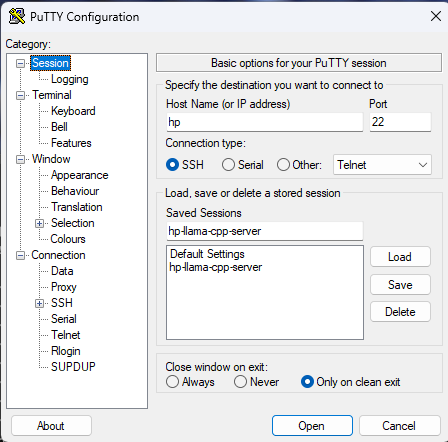
- Open PuTTY and enter the IP addresses of my remote Ubuntu machine in the “Host Name” field, save the session.
-
Under the “Connection” section, click on the “SSH” to expand the options and click on “Tunnels”.
-
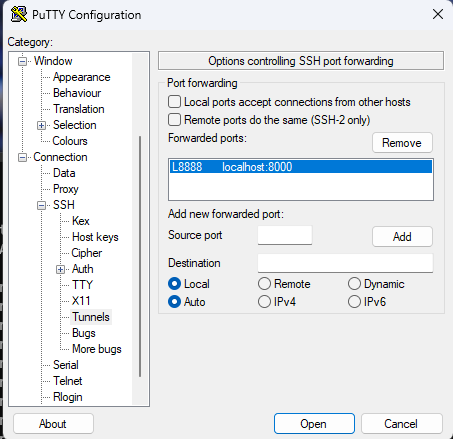
In the “Source port” field, enter 8888 (or any other port number of your choice) and in the “Destination” field, enter ’localhost:8000'.
-
Select the “Local” option and click on the “Add” button. The “Forwarded ports” section should now display the following entry:
-
Go back to the “Session” section and save the session again.
-
Click on the “Open button” to establish the SSH connection to the remote Ubuntu machine.
-
Enter the username and password for the remote Ubuntu machine when prompted.
-
That’s it! You have successfully set up PuTTY in Windows to tunnel Ubuntu port 8000 to a local Windows port.
-
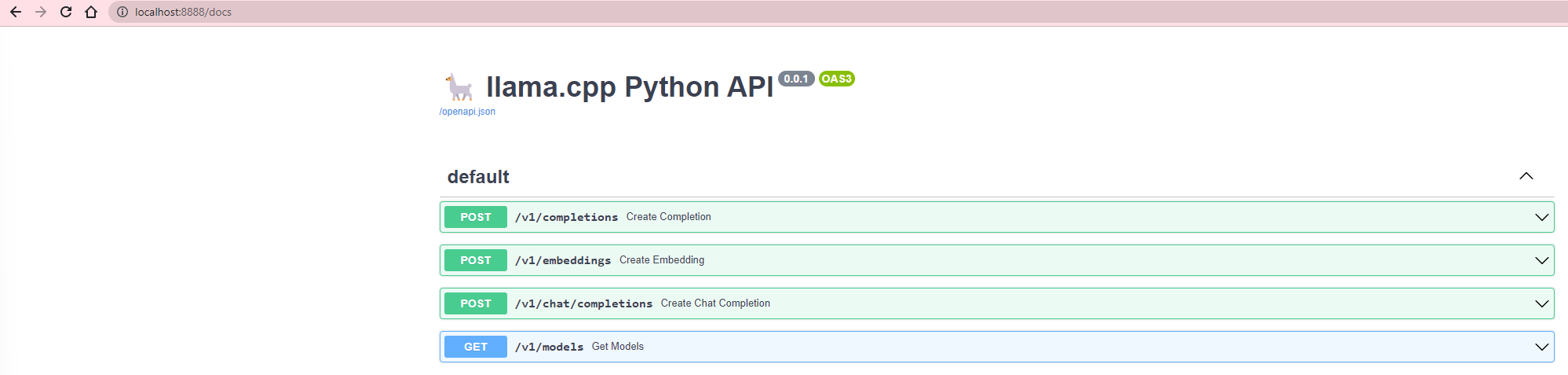
Navigate to the following to access the Open API:
http://localhost:8888/docs

Connecting from BYO-GPT
(2 mins)
By changing the gpt_constant.dart, we can easily swap and connect to the above server. The change is as such:
const openaiChatCompletionEndpoint = 'http://localhost:8888/v1/chat/completions';
const openaiCompletionEndpoint = 'http://localhost:8888/v1/completions';