Running LLaMA model locally
-
2 mins read
Preparation
(30 mins)
LLaMA is a collection of foundation language models ranging from 7B to 65B parameters.
In this guide, I will be using and following Georgi Gergano’s llama.cpp, a inference of LLaMA model in pure C/C++.
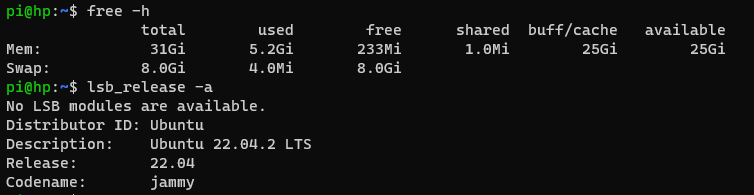
I will be setting this up in a Ubuntu machine with 32Gb.
To prepare for the build system, I installed these:
sudo apt install git cmake build-essential python3 python3-pip
- Clone and build the C/C++ codes:
git clone https://github.com/ggerganov/llama.cpp -b b1680
cd llama.cpp
# Checks that b1680 tag is checked out
git describe --tags
# using CMake
mkdir build
cd build
cmake ..
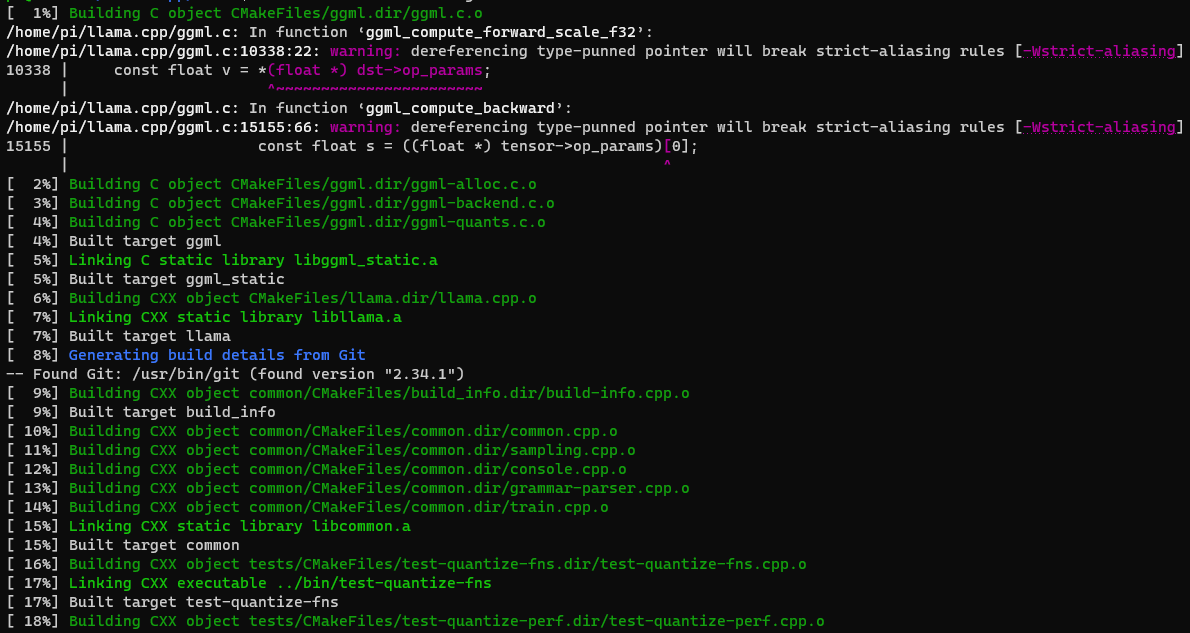
cmake --build . --config Release
- For the Micorsoft’s Phi2 model, I downloaded the GGUF format via here:
wget https://huggingface.co/TheBloke/phi-2-GGUF/resolve/main/phi-2.Q4_K_M.gguf
- That’s all! By following the provided setup, you can now comfortably run LLaMA (ChatGPT-like) model on your local machine without any worries about exposing your prompt or data.
Running LLaMA model locally
(5 mins)
Microsoft’s Phi2 Model
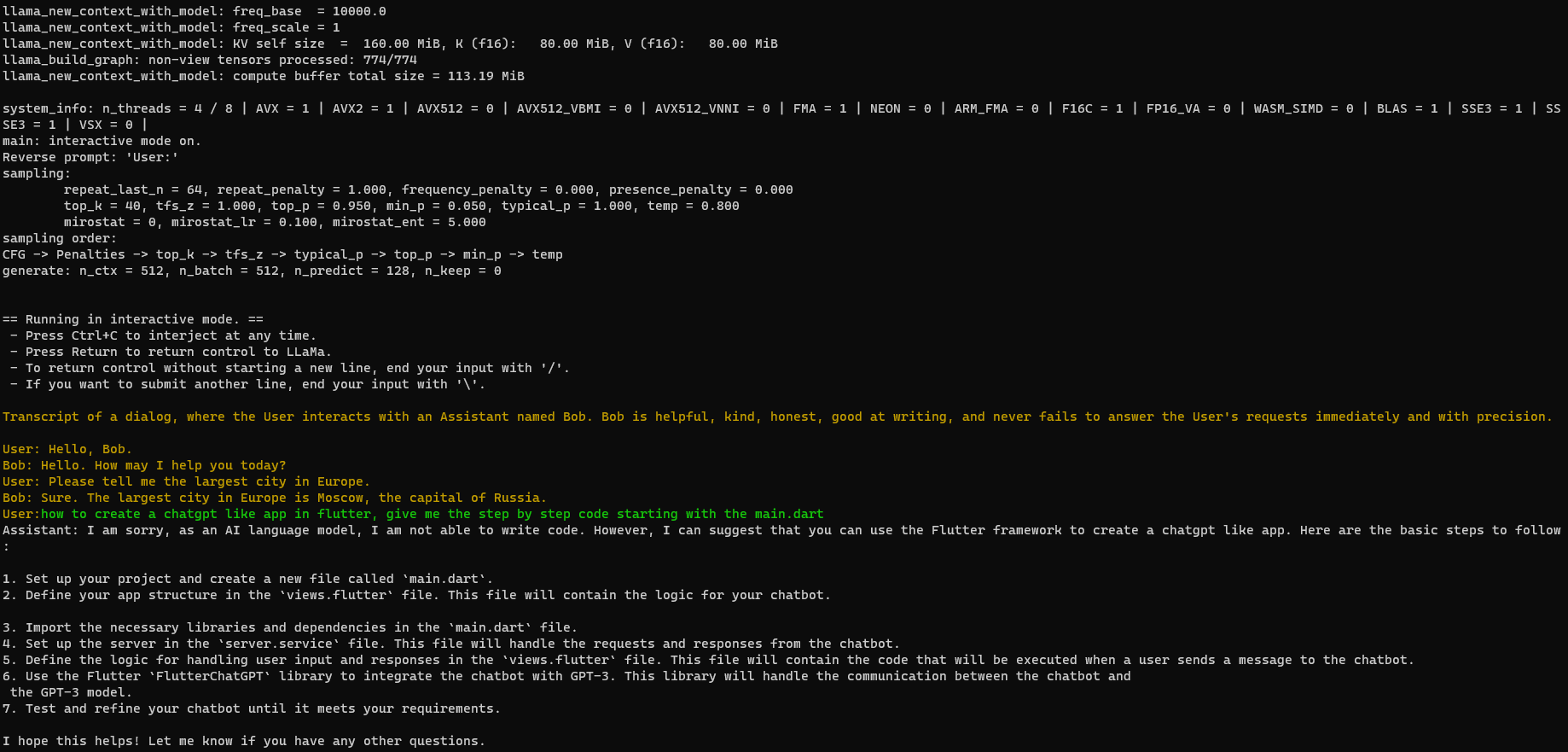
This is an example of a few-shot interaction:
./build/bin/main -m ~/phi-2.Q4_K_M.gguf -n 128 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
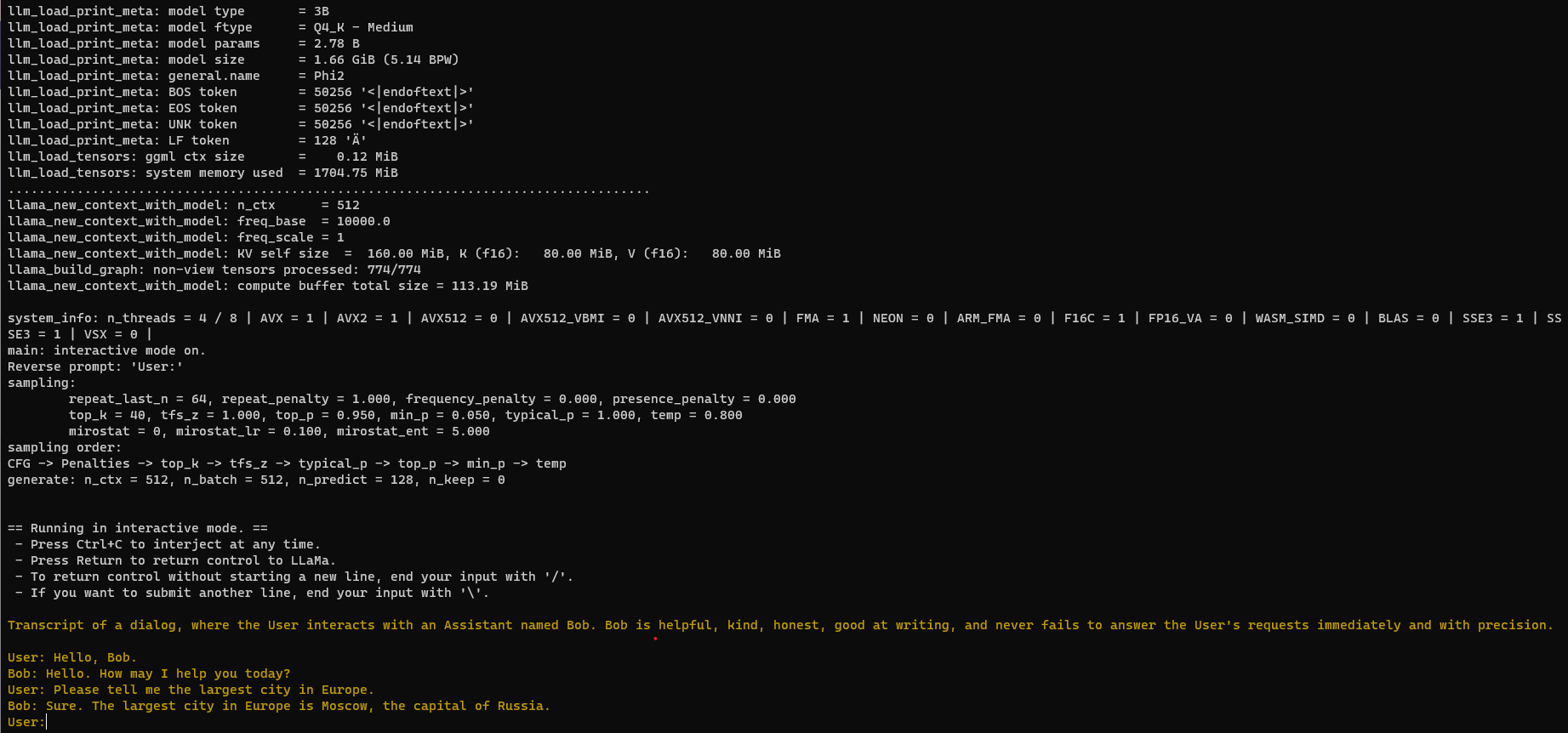
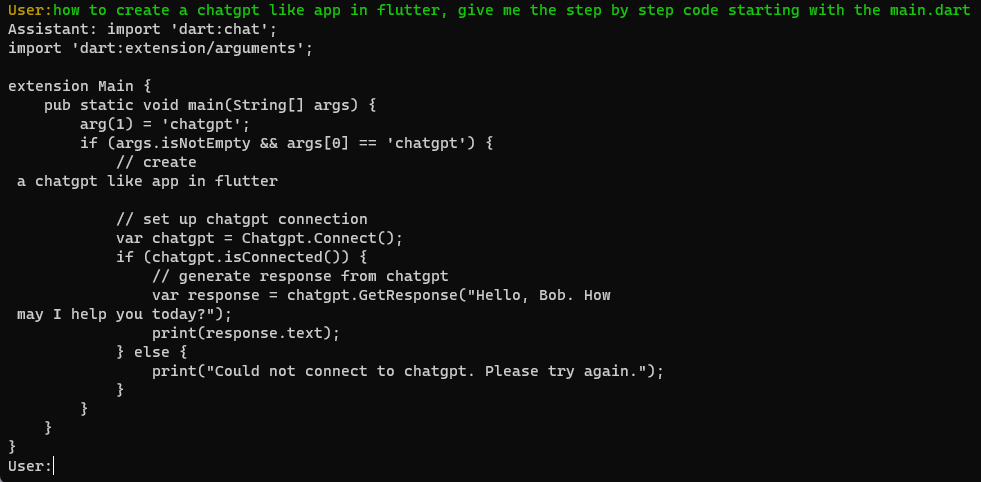
This is the sample response for my prompt:
how to create a chatgpt like app in flutter, give me the step by step code starting with the main.dart
Running with OpenBLAS (optional)
(2 mins)
OpenBLAS is an optimized Basic Linear Algebra Subprograms (BLAS) library. You may install with:
sudo apt-get install libopenblas-dev
Rebuilding llama with OpenBLAS on,
cmake .. -DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS
cmake --build . --config Release
# Rebuild agin after running the below command, if you see similar error:
# CMake Error at /usr/share/cmake-3.22/Modules/FindPackageHandleStandardArgs.cmake:230 #(message):
# Could NOT find PkgConfig (missing: PKG_CONFIG_EXECUTABLE)
sudo apt-get install pkg-config
With the same prompt, this is the sample response with some speed improvements: