Receipt OCR with LangChain, OpenAI and PyTesseract
Recently, I embarked on an exhilarating journey into the realm of receipt OCR using LangChain and OpenAI, inspired by the captivating course on LangChain for LLM Application Development. This exploration allowed me to unlock the full potential of PyTesseract, an extraordinary Python tool that serves as my guiding light for optical character recognition (OCR). By harnessing the power of OpenCV and seamlessly integrating OpenAI into the workflow, I aimed to compile the most optimal OCR results and validate them using LangChain’s impressive llm-math tool. Join me on this exciting adventure as we unravel the intricacies of receipt OCR and discover the true potential of LangChain, OpenAI, and PyTesseract.
PyTesseract: Harnessing Optical Character Recognition Power
To begin my exploration, I first ensured I had all the necessary tools at my disposal. Depending on the operating system, the Tesseract installer for Windows can be downloaded from here. With the installation complete, I equipped myself with essential Python packages by executing the following command:
pip install pytesseract pillow opencv-python
Now that everything was set, I put PyTesseract to the test using a sample receipt. Here’s a glimpse of the image we’ll be working with:

To witness the capabilities of PyTesseract firsthand, I present you with the following code snippet:
from PIL import Image
import pytesseract
# Defines the abosulate path to the executable
pytesseract.pytesseract.tesseract_cmd = r'C:/Program Files/Tesseract-OCR/tesseract.exe'
file = 'C:/ocr/sample-receipt-ocr.jpeg'
img = Image.open(file)
print(pytesseract.image_to_string(img))
Running this code for the first time, I eagerly awaited the results:
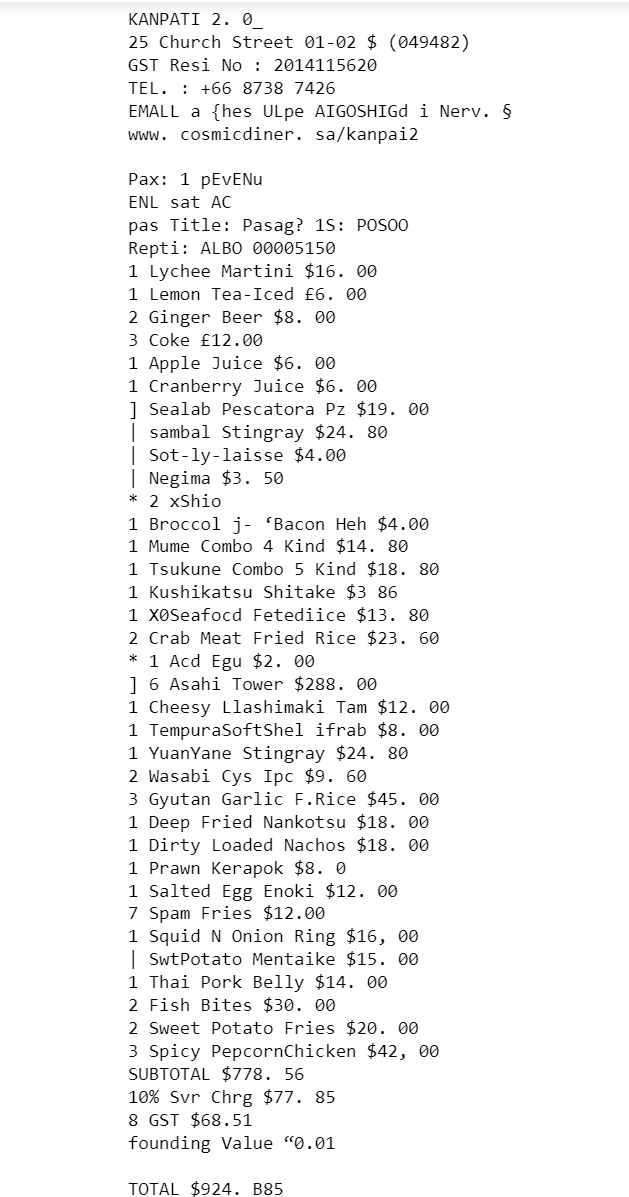
Join me on this exciting journey as we delve deeper into the remarkable capabilities of PyTesseract, uncovering its potential to extract text from images with unparalleled precision and accuracy.
Pytesseract and OpenCV: Unleashing Combined Power
As I continued my exploration with the sample receipt, I refined my code to generate a comprehensive dictionary containing the OCR results obtained through various methods. Let me share with you the code responsible for this accomplishment:
from PIL import Image
import pytesseract
import cv2
# Set Tesseract executable path
pytesseract.pytesseract.tesseract_cmd = r'C:/Program Files/Tesseract-OCR/tesseract.exe'
file = 'C:/ocr/sample-receipt-ocr.jpeg'
def perform_ocr(image, name):
text = pytesseract.image_to_string(image)
ocr_results.append({'name': name, 'text': text})
# Read the image using OpenCV
cvImage = cv2.imread(file)
# Initialize OCR results list
ocr_results = []
# Perform OCR on the original image
fileImage = Image.open(file)
perform_ocr(fileImage, 'FILE')
# Perform OCR on the OpenCV image
perform_ocr(cvImage, 'CV')
# Perform OCR on the grayscale image
gray = cv2.cvtColor(cvImage, cv2.COLOR_BGR2GRAY)
perform_ocr(gray, 'GRAY')
# Perform OCR on the thresholded image
_, threshold = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
perform_ocr(threshold, 'THRESHOLD')
# Perform OCR on the denoised image
denoised = cv2.medianBlur(cvImage, 3)
perform_ocr(denoised, 'DENOISED')
Throughout this process, I meticulously experimented with different methods to extract the text from the receipt. With each method, I added the results to a dictionary, capturing both the name of the method and the corresponding OCR output.
OpenAI: Unleashing Language Model Power
Allow me to introduce the next phase of our exploration: OpenAI. We have carefully crafted a prompt that will guide us through the integration of OpenAI into our OCR (Optical Character Recognition) use case:
template_string = """The ocr_result variable stores a list of results obtained from the OCR (Optical Character Recognition) process. \
Each item in the list represents a specific configuration or variation of the OCR process, along with the corresponding extracted text.
Please compare and merge the OCR results only when you are confident and avoid making assumptions.
Provide the following mandatory items in the given order if they exist in the OCR results:
Company
Invoice number
Date
Sub-total
Any extra charges
Rounding adjustment
Total amount
Itemised result (if any)
If possible, please provide the best effort list of itemized results with the pricing for each item.
Please format the result as a string.
OCR Text: {ocr_text}
"""
By seamlessly configuring OpenAI into our workflow, we gain the ability to extract vital information from the OCR results with remarkable precision and clarity. Here’s how we set up OpenAI:
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
from langchain.chat_models import ChatOpenAI
# To control the randomness and creativity of the generated
# text by an LLM, use temperature = 0.0
chat = ChatOpenAI(temperature=0.0)
chat
To leverage the power of OpenAI, we can now request it to merge the OCR data and generate the desired response based on our template string. Here’s how we can accomplish this:
from langchain.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_template(template_string)
ocr_inputs = prompt_template.format_messages(ocr_text=ocr_results)
ocr_response = chat(ocr_inputs)
print(ocr_response.content)
Here’s a sample response generated by OpenAI, demonstrating the merged and formatted output.

With OpenAI’s assistance, we are able to seamlessly merge and format the OCR results, providing us with the desired output that encompasses the essential information extracted from the receipts. This integration allows us to optimize our data processing workflow and enhance the accuracy and clarity of the extracted data.
For your convenience, this is the formatted output:
ocr_response_content = '''Company: KANPAI
Invoice number: A23000006 160
Date: 12/05/2023
Sub-total: $778.60
Any extra charges: 10% Svr Chrg $77.85, 8% GST $68.51
Rounding adjustment: Rounding Value 0.01
Total amount: $924.85
Itemised result:
1 Lychee Martini $16.00
1 Lemon Tea-Iced $6.00
2 Ginger Beer $8.00
3 Coke $12.00
1 Apple Juice $6.00
1 Cranberry Juice $6.00
1 Seafood Pescatora Pz $19.00
1 Sambal Stingray $24.80
1 Sot-ly-laisse $4.00
1 Negima $3.50
2 *Shio
1 Broccoli-fiacon Maki $4.00
1 Mume Combo 4 Kind $14.80
1 Tsukune Combo 5 Kind $18.80
1 Kushikatsu Shitake $3.80
1 XOSeafood FriedRice $13.80
2 Crab Meat Fried Rice $23.60
1 Acid Egu $2.00
6 Asahi Tower $288.00
1 Cheesy Dashimaki Tam $12.00
1 TempuraSoftShellCrab $8.00
1 YuanYane Stingray $24.80
2 Wasabi Cys Ipc $9.60
3 Gyutan Garlic F.Rice $45.00
1 Deep Fried Nankotsu $18.00
1 Dirty Loaded Nachos $18.00
1 Prawn Keropok $8.00
1 Salted Egg Enoki $12.00
1 Span Fries $12.00
1 Squid N Onion Ring $16.00
1 SwtPotato Mentaika $15.00
1 Thai Pork Belly $14.00
2 Fish Bites $30.00
2 Sweet Potato Fries $20.00
3 Spicy Pepcornthicken $42.00```
LangChain: Enhancing Verification with LLM-Math
In this section, we will leverage the power of LangChain by utilizing its LLM-Math tool. This tool will assist us in verifying the receipt by calculating the amount and comparing it to the OCR results obtained in the earlier section.
Let’s start by loading the necessary tools:
from langchain.agents import load_tools, initialize_agent
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
and initializing the agent:
llm = ChatOpenAI(temperature=0)
tools = load_tools(['llm-math'], llm=llm)
agent = initialize_agent(
tools,
llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose = True)
With the agent initialized, we can now use LangChain to verify the results:
agent.run(f"""Given data ```{ocr_response.content}``` is in the form of key-value pair, eg [KEY]: value
Ignore the quantity component of each of the given itemized results.
Calculate with these formulas:
(1) Sub-total (to calculate) = Sum of all itemized results
(2) Total amount (to calculate) = Sub-total (1) + Extra Chages - Rounding Value
Reply in this format:
Sub-total (given)
Sub-total (calculated)
Total amount (given)
Total amount (calculated)
""")
With the LangChain agent in action, we perform a comprehensive evaluation of the receipt OCR, summarizing the thought process, calculations, and evaluation results. Finally, we compare the original and calculated Total Amount values.
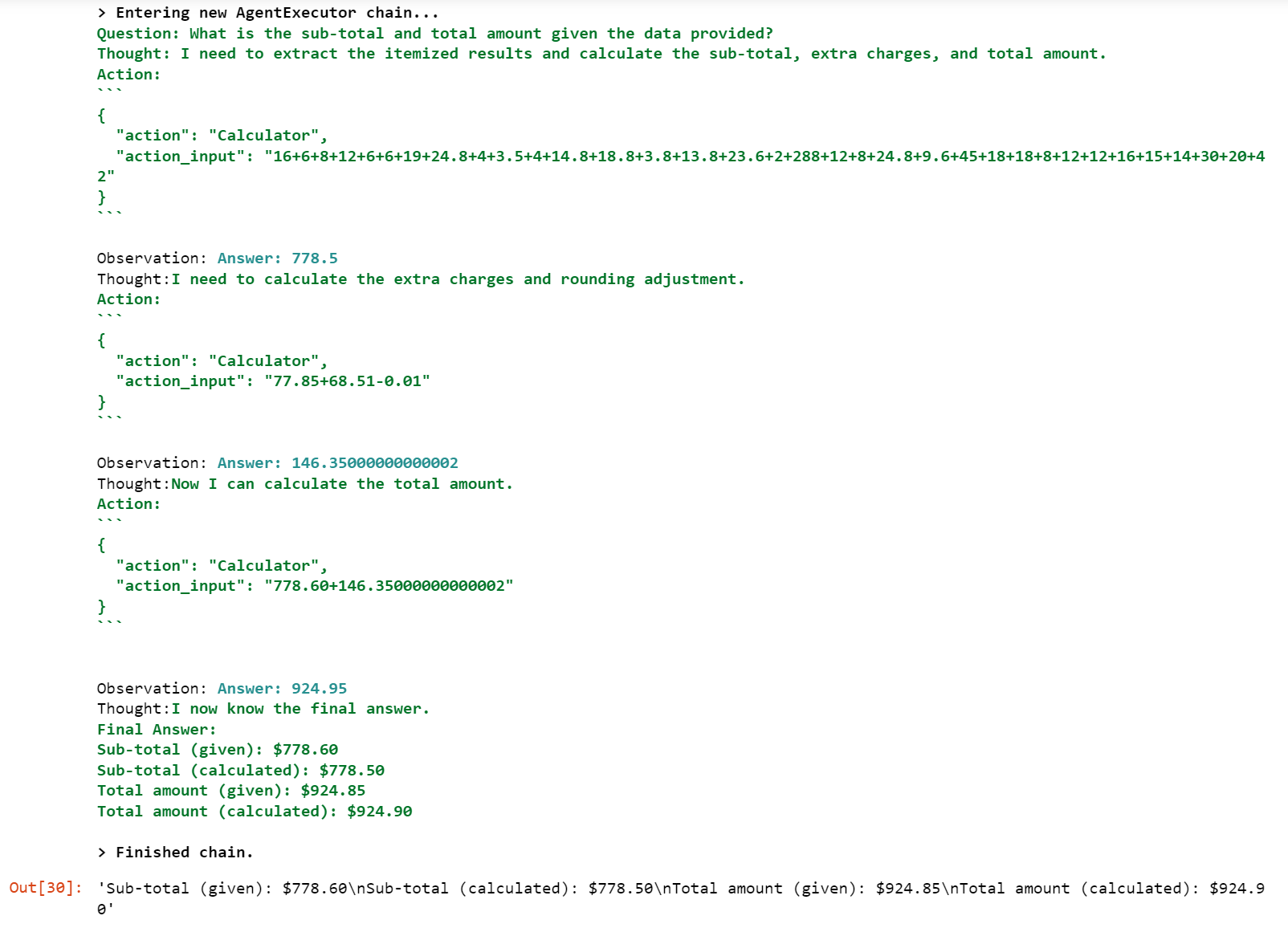
By incorporating LangChain into our workflow, we can confidently verify the accuracy of the OCR results by performing precise calculations. This integration adds another layer of validation, ensuring the reliability and integrity of the extracted data.
Congratulations on completing this exploration of receipt OCR using LangChain and OpenAI! You have witnessed the seamless integration of various tools and technologies, leveraging their combined power to achieve remarkable results. From PyTesseract and OpenCV for OCR to OpenAI for language modeling and LangChain for mathematical verification, this journey has exemplified the potential of these tools in data processing and analysis.
I hope this journey has been enlightening and inspiring. Feel free to explore further and apply these techniques to other exciting projects. If you have any more questions or need assistance, please don’t hesitate to ask.
Happy exploring!