RAG over Java code with Langchain4j
Expanding upon the concepts introduced in the previous post and drawing inspiration from RAG over code, this article dives into the integration of a Retrieval-Augmented Generation (RAG) service. The goal is to empower users to query their Java codebase effectively.
Getting Started
To embark on this journey, I’ve opted for Java Parser , a powerful tool for traversing Java source code. Let’s begin by incorporating the latest version of Java Parser into our build.gradle file:
...
dependencies {
// Ohter dependencies
implementation 'com.github.javaparser:javaparser-symbol-solver-core:3.25.6'
}
Creating new Services
In this section, we created the essential services to enhance the capabilities of our AI application. We introduce two key services, each serving a distinct purpose in our system architecture.
JavaParsingService
The JavaParsingService is introduced to facilitate codebase analysis using the Java Parser library. This service lays the foundation for code traversal and integrates with Langchain4j components for embedding and retrieval. Below is the detailed service implementation:
package com.seehiong.ai.service;
import static dev.langchain4j.data.document.Document.DOCUMENT_TYPE;
import static dev.langchain4j.model.openai.OpenAiModelName.GPT_3_5_TURBO;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.github.javaparser.ParseResult;
import com.github.javaparser.ast.CompilationUnit;
import com.github.javaparser.ast.PackageDeclaration;
import com.github.javaparser.ast.body.ClassOrInterfaceDeclaration;
import com.github.javaparser.ast.visitor.VoidVisitor;
import com.github.javaparser.ast.visitor.VoidVisitorAdapter;
import com.github.javaparser.utils.SourceRoot;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.Metadata;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiTokenizer;
import dev.langchain4j.retriever.EmbeddingStoreRetriever;
import dev.langchain4j.retriever.Retriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
@Service
public class JavaParsingService {
@Autowired
private EmbeddingStoreService embeddingStoreSvc;
interface JavaCodeAgent {
@SystemMessage({
"Imagine you are a highly experienced Java programmer tasked with explaining the structure and functionality of the provided Java code.",
"Your goal is to conduct a thorough analysis of the codebase, highlighting key aspects such as design patterns, architectural choices, and coding practices." })
String query(String userMessage);
}
static class ClassNameCollector extends VoidVisitorAdapter<List<String>> {
@Override
public void visit(ClassOrInterfaceDeclaration n, List<String> collector) {
super.visit(n, collector);
collector.add(n.getNameAsString());
}
}
static class JavaDocumentLoader {
public Document load(String javaCode, Optional<PackageDeclaration> packageName) {
Document document = Document.from(javaCode, Metadata.from(DOCUMENT_TYPE, "java"));
document.metadata().add("package name", packageName);
return document;
}
}
public String load(EmbeddingModel embeddingModel, String project) {
JavaDocumentLoader javaLoader = new JavaDocumentLoader();
EmbeddingStore<TextSegment> embeddingStore = embeddingStoreSvc.getEmbeddingStore();
EmbeddingStoreIngestor embeddingStoreIngestor = embeddingStoreSvc.getEmbeddingStoreIngestor(embeddingModel);
// Parse all source files
SourceRoot sourceRoot = new SourceRoot(Paths.get(project));
List<ParseResult<CompilationUnit>> parseResults;
List<String> className = new ArrayList<>();
try {
parseResults = sourceRoot.tryToParse();
for (ParseResult<CompilationUnit> parseResult : parseResults) {
if (parseResult.getResult().isPresent()) {
CompilationUnit unit = parseResult.getResult().get();
Document document = javaLoader.load(unit.toString(), unit.getPackageDeclaration());
DocumentSplitter splitter = DocumentSplitters.recursive(100, 0, new OpenAiTokenizer(GPT_3_5_TURBO));
List<TextSegment> segments = splitter.split(document);
List<Embedding> embeddings = embeddingModel.embedAll(segments).content();
embeddingStore.addAll(embeddings, segments);
embeddingStoreIngestor.ingest(document);
VoidVisitor<List<String>> classNameVisitor = new ClassNameCollector();
classNameVisitor.visit(unit, className);
}
}
StringBuilder sb = new StringBuilder("Class name loaded:");
className.forEach(classItem -> {
sb.append(System.lineSeparator());
sb.append(classItem);
});
return sb.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "Unable to load project: " + project;
}
public String query(ChatLanguageModel model, EmbeddingModel embeddingModel, String question) {
JavaCodeAgent agent = getJavaCodeAgent(model, getRetriever(embeddingModel));
return agent.query(question);
}
private Retriever<TextSegment> getRetriever(EmbeddingModel embeddingModel) {
int maxResultsRetrieved = 3;
double minScore = 0.6;
return EmbeddingStoreRetriever.from(embeddingStoreSvc.getEmbeddingStore(), embeddingModel, maxResultsRetrieved,
minScore);
}
private JavaCodeAgent getJavaCodeAgent(ChatLanguageModel model, Retriever<TextSegment> retriever) {
return AiServices.builder(JavaCodeAgent.class).chatLanguageModel(model)
.chatMemory(MessageWindowChatMemory.withMaxMessages(20)).retriever(retriever).build();
}
}
EmbeddingStoreService
To ensure reusability across multiple services, the EmbeddingStoreService has been refactored. This service handles the instantiation and management of the EmbeddingStore and EmbeddingStoreIngestor. Below is the refactored code:
package com.seehiong.ai.service;
import static dev.langchain4j.internal.Utils.randomUUID;
import java.util.HashMap;
import java.util.Map;
import org.springframework.stereotype.Service;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.chroma.ChromaEmbeddingStore;
@Service
public class EmbeddingStoreService {
private EmbeddingStore<TextSegment> embeddingStore;
private Map<Object, EmbeddingStoreIngestor> embeddingStoreIngestorMap = new HashMap<>();
public EmbeddingStore<TextSegment> getEmbeddingStore() {
if (embeddingStore == null) {
embeddingStore = ChromaEmbeddingStore.builder().baseUrl("http://127.0.0.1:8000")
.collectionName(randomUUID()).build();
}
return embeddingStore;
}
public EmbeddingStoreIngestor getEmbeddingStoreIngestor(EmbeddingModel embeddingModel) {
embeddingStoreIngestorMap.computeIfAbsent(embeddingModel,
key -> EmbeddingStoreIngestor.builder().documentSplitter(DocumentSplitters.recursive(500, 0))
.embeddingModel(embeddingModel).embeddingStore(getEmbeddingStore()).build());
return embeddingStoreIngestorMap.get(embeddingModel);
}
}
Enhancing Controller Functionality
In this section, we expand the capabilities of the controller by introducing two new endpoints tailored for interacting with the Java codebase.
public class AiController {
...
@Autowired
private JavaParsingService javaParsingSvc;
@GetMapping("/load")
public ResponseEntity<String> load(@RequestParam("project") String project) {
String response = javaParsingSvc.load(modelSvc.getEmbeddingModel(), project);
return new ResponseEntity<>(response, HttpStatus.OK);
}
@GetMapping("/query")
public ResponseEntity<String> query(@RequestParam("question") String question) {
String response = javaParsingSvc.query(modelSvc.getLocalModel(), modelSvc.getEmbeddingModel(), question);
return new ResponseEntity<>(response, HttpStatus.OK);
}
}
With these enhancements, users can seamlessly load Java projects into the application and query them to gain valuable insights. The controller acts as a bridge, orchestrating interactions between the user and the underlying services, creating a more dynamic and user-friendly AI application.
Witnessing it in Action
Continuing the journey from the previous post, we’ll now observe the Retrieval-Augmented Generation (RAG) application in action. Before proceeding, ensure that both the Chroma and LocalAI Docker images are up and running.
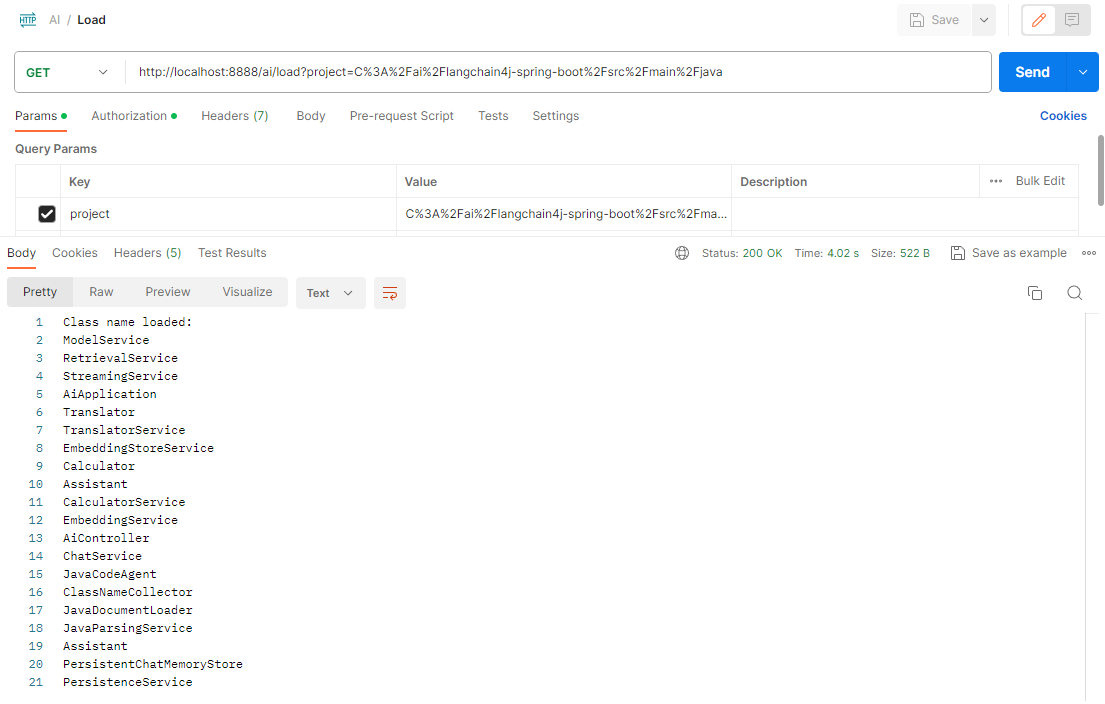
Codebase Ingestion
Let’s begin by ingesting the codebase for this RAG application. To achieve this, simply provide the folder path of the project root to the API.
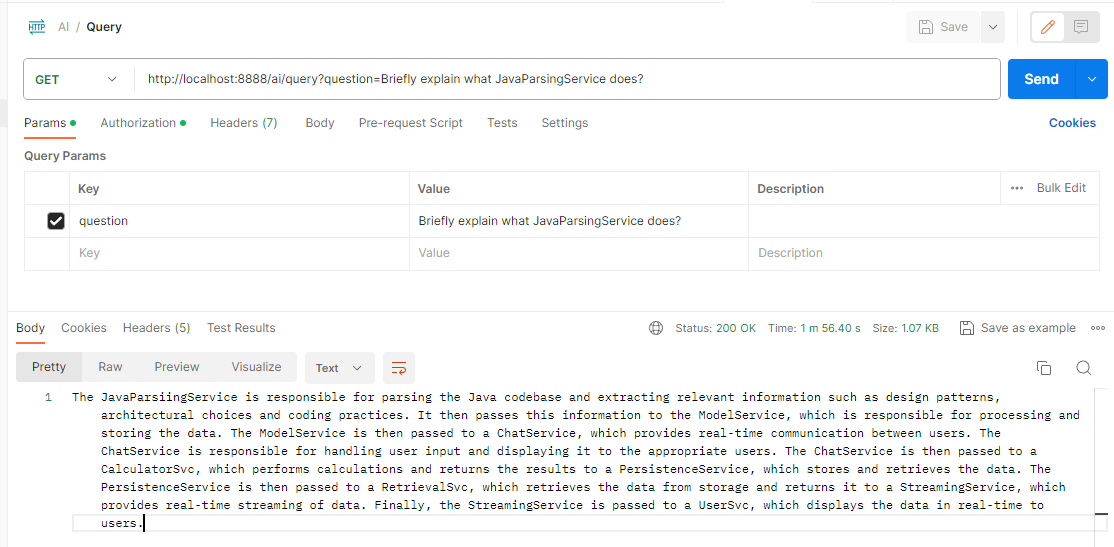
Querying the Codebase with gpt4all-j
Now, let’s proceed to query the ingested codebase using the gpt4all-j model.
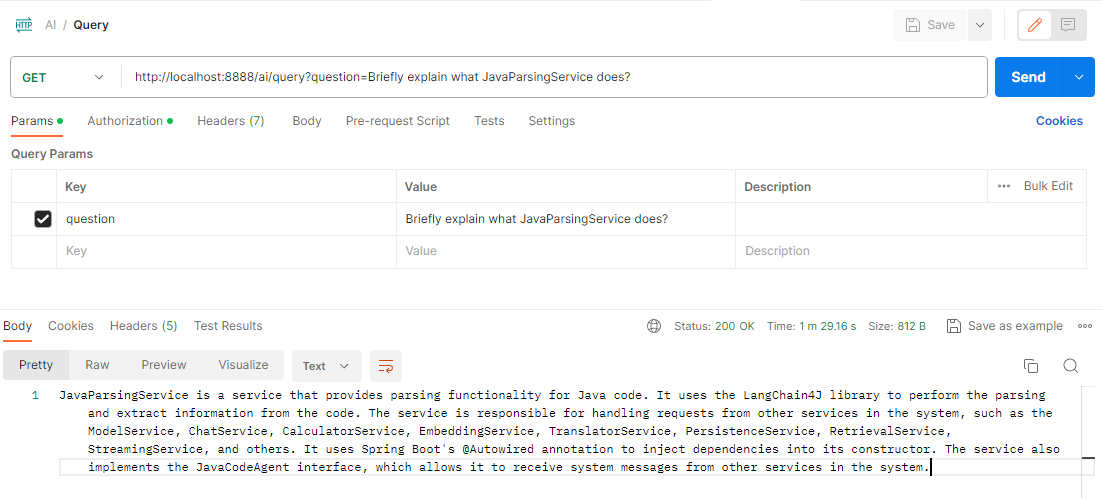
Comparison with WizardLM
Let’s compare the results with WizardLM:
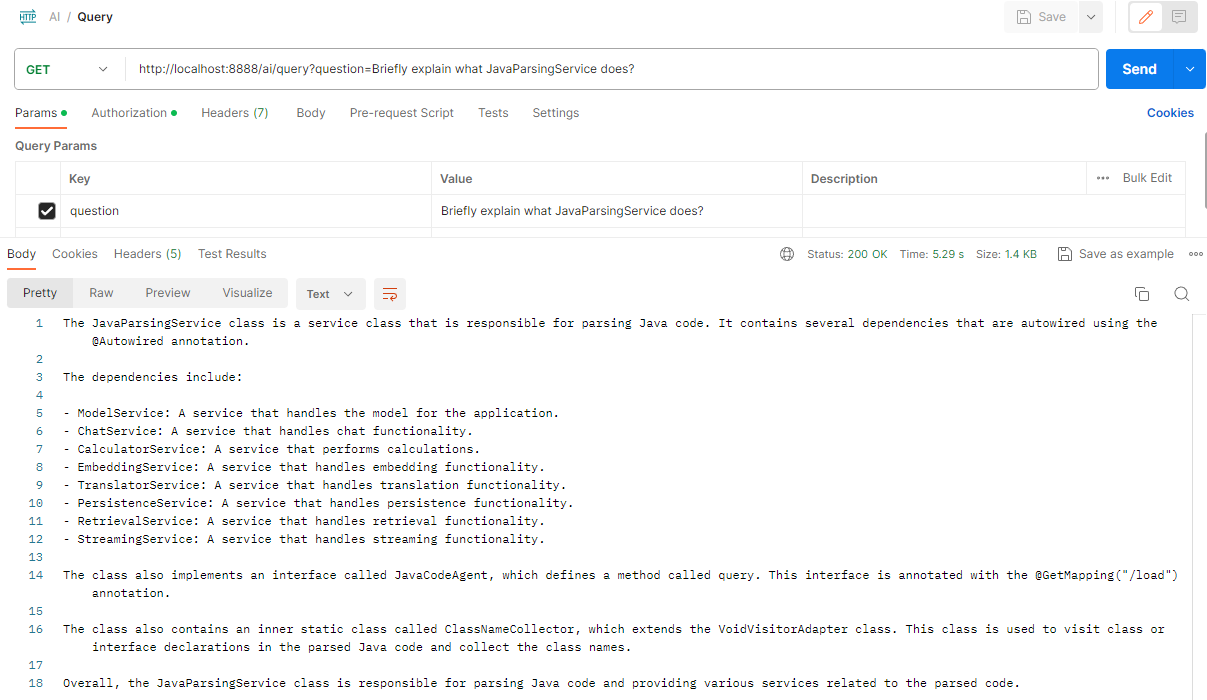
Comparison with OpenAI
Now, let’s compare the results with OpenAI:
Summary
In this section, we observed the RAG application in action, ingested the codebase, and compared the results with other language models such as WizardLM and OpenAI.
This post provides a comprehensive walkthrough of ingesting an entire codebase and setting up endpoints to query a Java codebase using Retrieval-Augmented Generation (RAG) with Langchain4j. The inclusion of comparisons with other language models enhances the understanding of the application’s capabilities.