How to summarize YouTube Videos in Minutes (II)
In continuation with the previous post, we will explore the power of AI by leveraging the whisper.cpp library to convert audio to text, extracting audio from YouTube videos using yt-dlp, and demonstrating how to utilize AI models like GPT4All and OpenAI for summarization.
Setting Up the Environment
To get started, we need to set up the necessary tools and libraries. Follow the steps below:
- Installing whisper.cpp: Begin by cloning the whisper.cpp repository from GitHub and downloading the base.en model.
git clone https://github.com/ggerganov/whisper.cpp.git
cd ~/whisper.cpp/models
./download-ggml-model.sh base.en
- Verifying the Installation: Once the model is downloaded, you can test the installation by running a sample command:
Downloading ggml model base.en from 'https://huggingface.co/ggerganov/whisper.cpp' ...
ggml-base.en.bin 100%[========================>] 141.11M 10.9MB/s in 14s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
- Installing OpenBLAS: Ensure that OpenBLAS, a mathematical library, is installed on your system. This step is necessary for building whisper.cpp with OpenBLAS support.
cd ~/whisper.cpp
make clean
WHISPER_OPENBLAS=1 make -j
This is the sample output (with BLAS = 1):
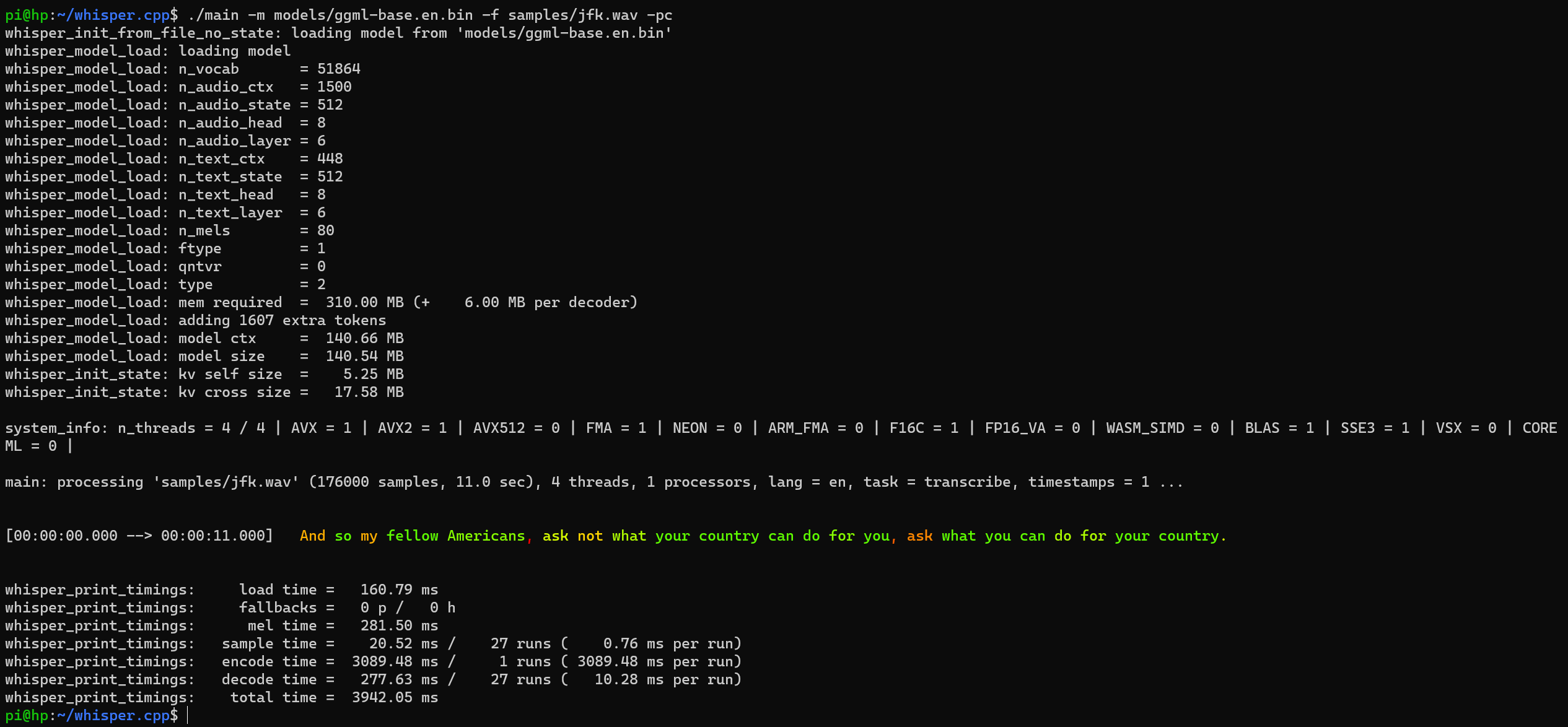
- Installing FFmpeg: FFmpeg is required for audio conversion. Install it using the appropriate package manager for your system.
sudo apt install ffmpeg
- Installing yt-dlp and whispercpp: Use pip to install yt-dlp, a YouTube downloader, and the Python binding for whisper.cpp.
python3 -m pip install -U yt-dlp
pip install whispercpp ffmpeg-python
Extracting Audio from YouTube Videos
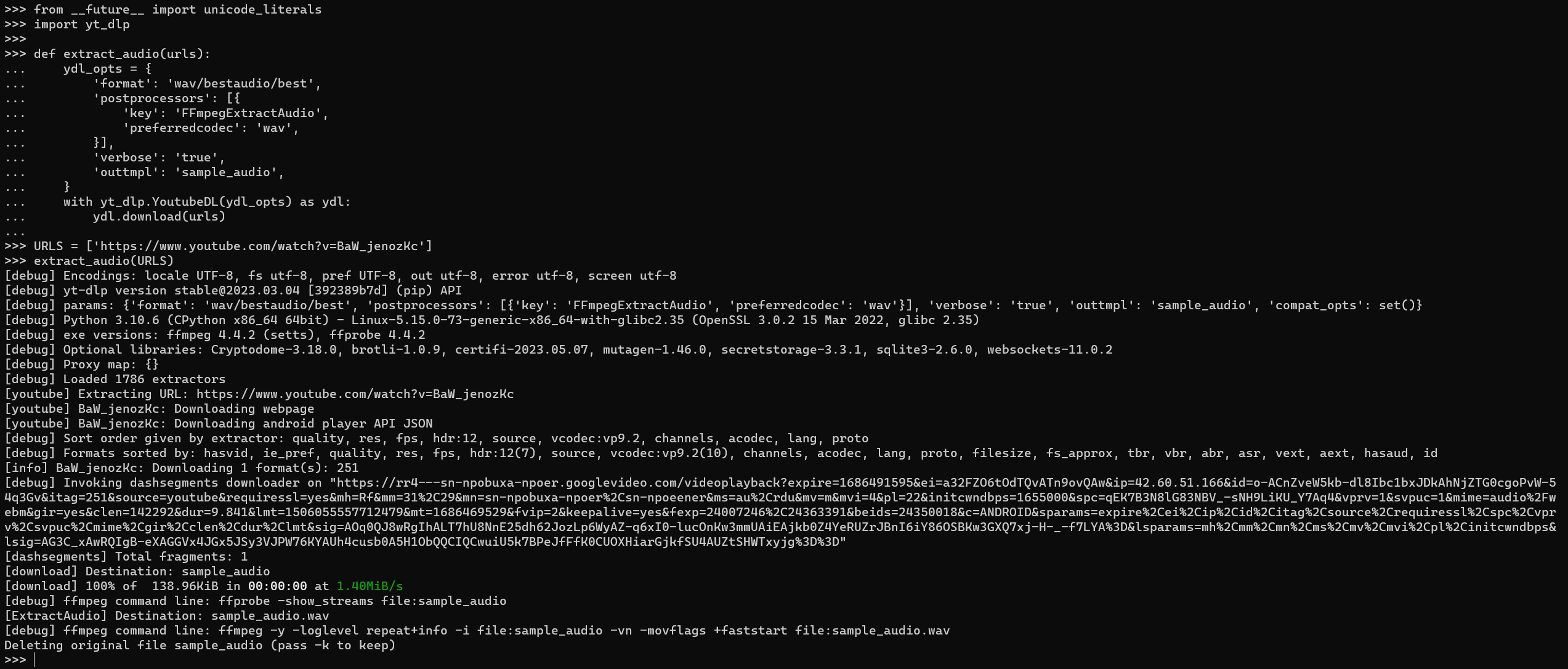
In this section, we will demonstrate how to extract audio from YouTube videos using the yt-dlp library. Here’s the code snippet:
from __future__ import unicode_literals
import yt_dlp
def extract_audio(urls):
ydl_opts = {
'format': 'wav/bestaudio/best',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'wav',
}],
'verbose': 'true',
'outtmpl': 'sample_audio',
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download(urls)
URLS = ['https://www.youtube.com/watch?v=BaW_jenozKc']
extract_audio(URLS)
Utilizing Whisper to Transcribe Audio
With the audio extracted, we can now utilize the whisper.cpp library to transcribe the audio into text. Follow the code snippet below:
from whispercpp import Whisper
w = Whisper.from_pretrained("base.en")
import ffmpeg
import numpy as np
def transcribe_audio(filename):
try:
y, _ = (
ffmpeg.input(filename, threads=0)
.output("-", format="s16le", acodec="pcm_s16le", ac=1, ar=16000)
.run(cmd=["ffmpeg", "-nostdin"], capture_stdout=True, capture_stderr=True)
)
except ffmpeg.Error as e:
raise RuntimeError(f"Failed to load audio: {e.stderr.decode()}") from e
arr = np.frombuffer(y, np.int16).flatten().astype(np.float32) / 32768.0
return w.transcribe(arr)
filename = "sample_audio.wav"
transcribe_audio(filename)
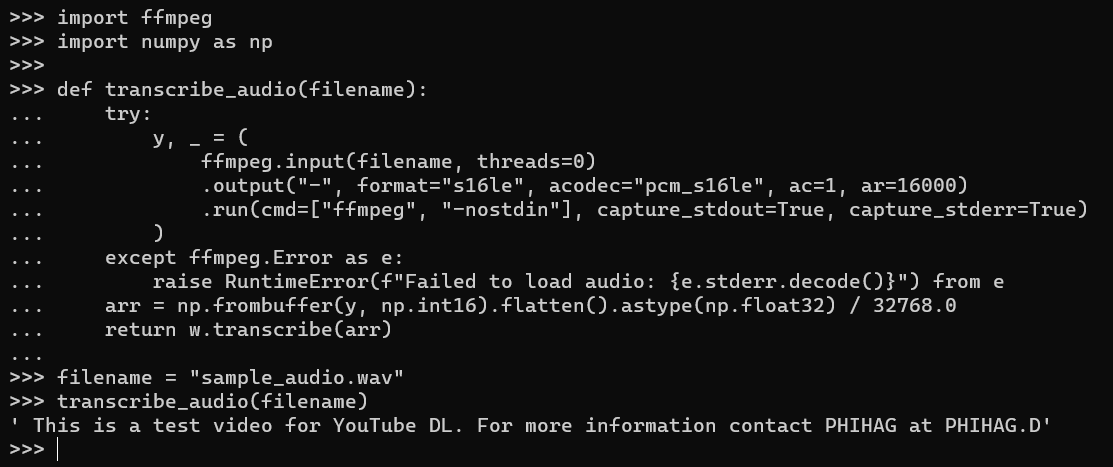
This code snippet uses the Whisper library to transcribe the audio stored in the “sample_audio.wav” file. The audio is processed using ffmpeg to convert it into a format suitable for transcription. The resulting transcription is stored in the transcripted variable and printed to the console:
Putting it Together: Extracting and Summarizing YouTube Videos
Now let’s bring everything together by extracting audio from a YouTube video and using AI models for summarization.
First, we’ll download audio from a YouTube video. In this example, we’ll use the video LangChain Explained in 13 Minutes as an example. The downloaded audio will be saved as “sample_audio.wav”. Here’s the code snippet to download the audio:
URLS = ['https://www.youtube.com/watch?v=aywZrzNaKjs']
extract_audio(URLS)
filename = "sample_audio.wav"
Next, we’ll transcribe the audio using the Whisper library as shown earlier:
transcripted = transcribe_audio(filename)
print(transcripted)

Now, let’s summarize the transcribed text using an AI model like GPT4All:
from langchain.llms import GPT4All
llm = GPT4All(model="/home/pi/models/ggml-gpt4all-j-v1.3-groovy.bin", n_ctx=2048)
from langchain.chains.summarize import load_summarize_chain
from langchain.chains import AnalyzeDocumentChain
summary_chain = load_summarize_chain(llm, chain_type="map_reduce")
summarize_document_chain = AnalyzeDocumentChain(combine_docs_chain=summary_chain)
summarize_document_chain.run(transcripted)
The code above demonstrates the utilization of the GPT4All model for summarizing the transcribed text. It involves loading the required chains and initiating the summarization process.
However, it appears that the generated results from the AI model are not accurate, as shown in the provided example output:
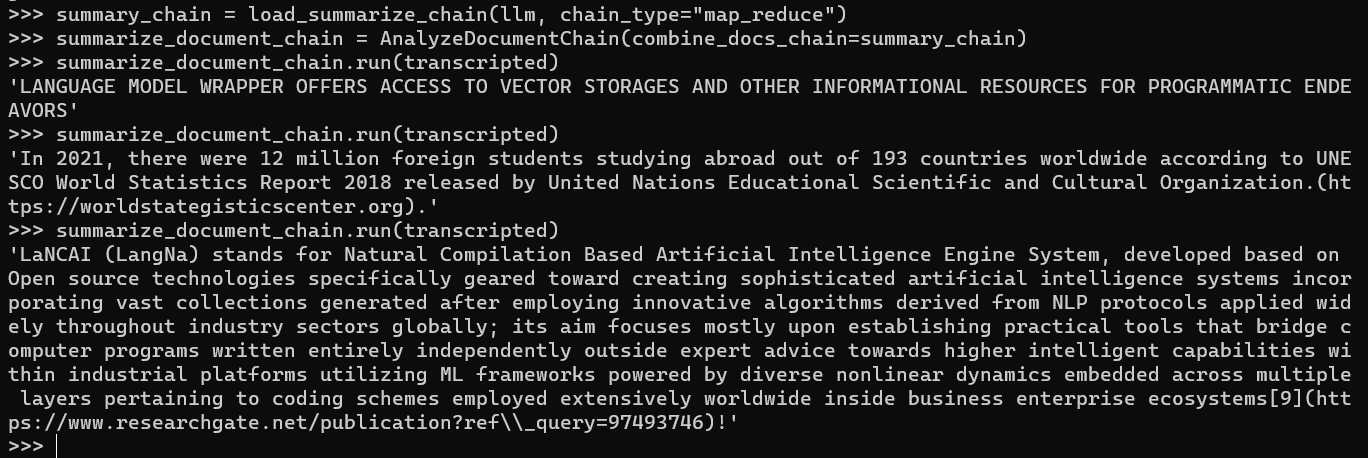
This generated output seems to be unrelated and doesn’t provide the expected summarization.
It’s important to note that the quality and accuracy of AI-generated summaries can vary depending on the model and the specific use case. In this instance, the GPT4All model did not produce the desired results.
By combining the steps of audio extraction, transcription, and alternative summarization techniques, you can still leverage AI-powered tools to extract and summarize YouTube videos effectively.
Utilizing LLaMA.cpp for Summarization (Optional)
An alternative approach is to employ LLaMA.cpp for the summarization task. For the setup process, you can refer to my previous post.
Here’s an example code snippet showcasing the usage of LLaMA.cpp:
from langchain.llms import LlamaCpp
llm = LlamaCpp(model_path="/home/pi/models/WizardLM-7B-uncensored.ggmlv3.q5_0.bin", n_ctx=2048, verbose=True)
summary_chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=True)
summarize_document_chain = AnalyzeDocumentChain(combine_docs_chain=summary_chain)
summarize_document_chain.run(transcripted)
The image below displays the generated output from this summarization process:
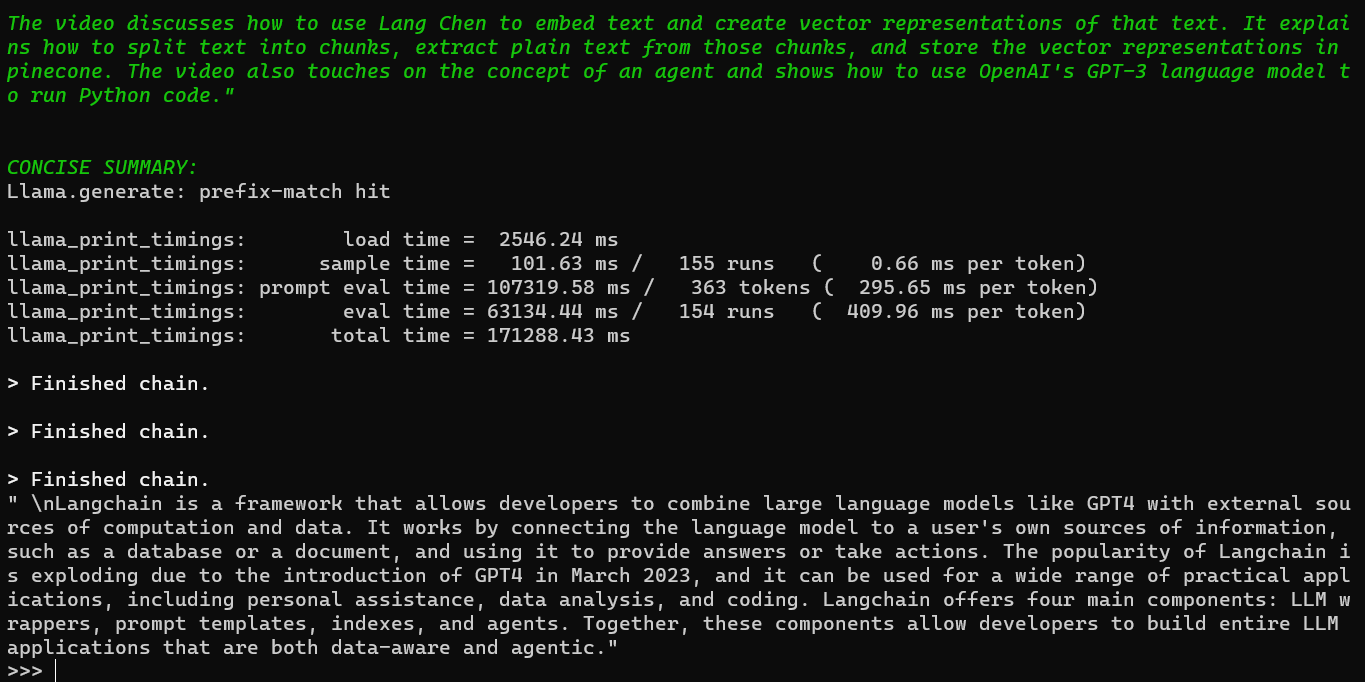
By employing LLaMA.cpp, you can explore an alternative approach to summarizing the transcribed text. Remember to follow the setup instructions provided in the mentioned previous post to utilize LLaMA.cpp effectively.
Utilizing OpenAI for Summarization (Optional)
For an alternative approach, you can leverage OpenAI models for the summarization task. Take a look at the following code snippet:
import os
os.environ["OPENAI_API_KEY"] = "sk-...2o"
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.0)
from langchain.chains.summarize import load_summarize_chain
from langchain.chains import AnalyzeDocumentChain
summary_chain = load_summarize_chain(llm, chain_type="map_reduce", verbose=True)
summarize_document_chain = AnalyzeDocumentChain(combine_docs_chain=summary_chain)
summarize_document_chain.run(transcripted)
This code snippet demonstrates the utilization of OpenAI’s Chat models for the summarization process. It involves setting the OpenAI API key, loading the required chains, and executing the summarization.
The resulting output can be seen in the image below:
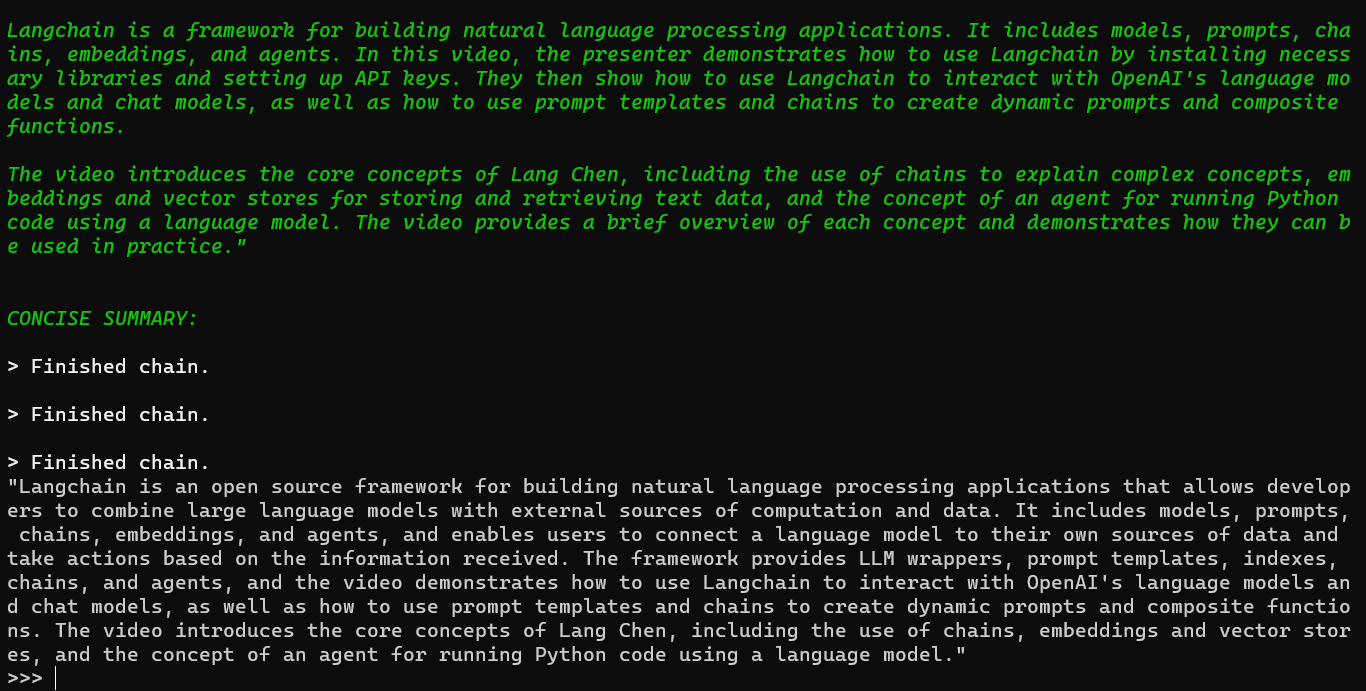
By incorporating OpenAI models into your workflow, you can obtain alternative summarization outcomes. The provided code snippet showcases how to seamlessly integrate OpenAI models for this purpose.
That concludes our exploration of utilizing AI techniques to extract and summarize information from YouTube videos. By employing tools like Whisper.cpp, GPT4ALL, LLaMA.cpp, and OpenAI models, you can leverage the power of AI to extract audio, transcribe it, and generate concise summaries. These techniques offer valuable applications for tasks such as content analysis, research, and information retrieval.
By incorporating these AI-powered approaches into your workflows, you can streamline the process of extracting key insights from video content. Whether you’re a researcher, content creator, or information enthusiast, these tools provide efficient and effective means of analyzing and summarizing YouTube videos.