Deploying OpenAI-Compatible LLAMA CPP Server with K3S
Commencing my week-long Christmas break, I extend the concepts from my previous post to establish an OpenAI-compatible server in my Home Lab.
Technical Setup
After fine-tuning a sample Dockerfile, I reinstalled my Ubuntu server, incorporating necessary adjustments. The subsequent setup commands, reflecting my Home Lab’s new IP address (192.168.68.115), include:
sudo apt update & sudo apt upgrade -y
# Install docker
sudo apt install docker.io
sudo usermod -aG docker pi
# Install Anaconda
curl -O https://repo.anaconda.com/archive/Anaconda3-2023.09-0-Linux-x86_64.sh
chmod +x Anaconda3-2023.09-0-Linux-x86_64.sh
./Anaconda3-2023.09-0-Linux-x86_64.sh
# Init conda
source /home/pi/anaconda3/bin/activate
conda init
conda create -n docker-llama python
conda activate docker-llama
The corresponding Dockerfile features:
FROM python:3-slim-bullseye
# We need to set the host to 0.0.0.0 to allow outside access
ENV HOST 0.0.0.0
COPY ./phi-2.Q4_K_M.gguf .
# Install the package
RUN apt update && apt install -y libopenblas-dev ninja-build build-essential pkg-config
RUN pip install --upgrade pip
RUN python -m pip install --no-cache-dir --upgrade pip pytest cmake scikit-build setuptools fastapi uvicorn sse-starlette pydantic-settings starlette-context
RUN CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install --no-cache-dir --force-reinstall llama_cpp_python==0.2.24 --verbose
# Run the server
CMD ["python3", "-m", "llama_cpp.server", "--model", "/phi-2.Q4_K_M.gguf"]
For the Micorsoft’s Phi2 model, I downloaded the GGUF format via here:
wget https://huggingface.co/TheBloke/phi-2-GGUF/resolve/main/phi-2.Q4_K_M.gguf
Docker Image Build and Run
The image, packaged with Microsoft’s Phi2 model, is built using:

docker build . -t llama-microsoft-phi2:v0.2.24
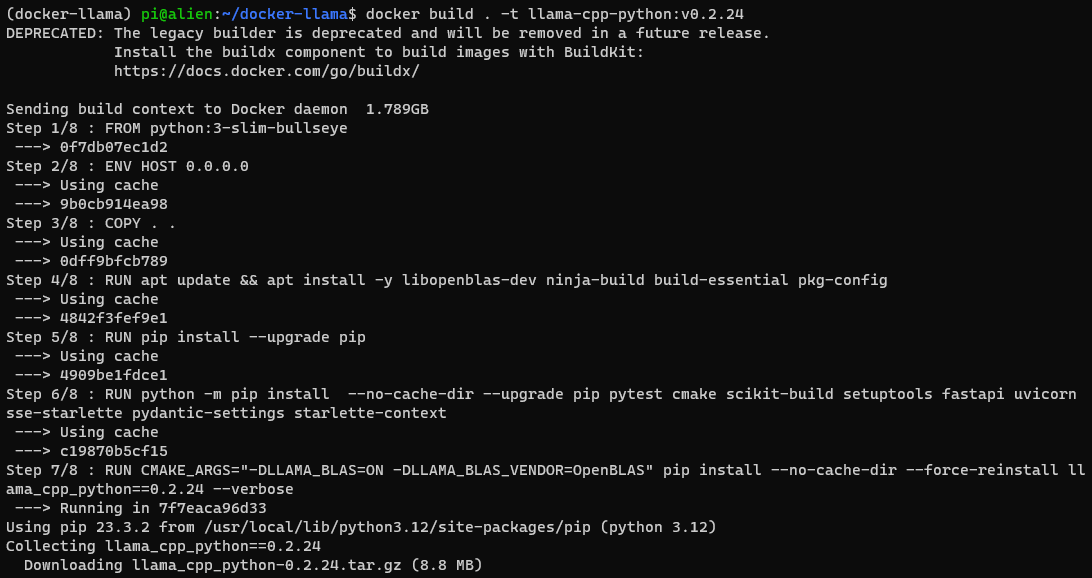
To run the image:
docker run -p 8000:8000 --rm -it llama-microsoft-phi2:v0.2.24
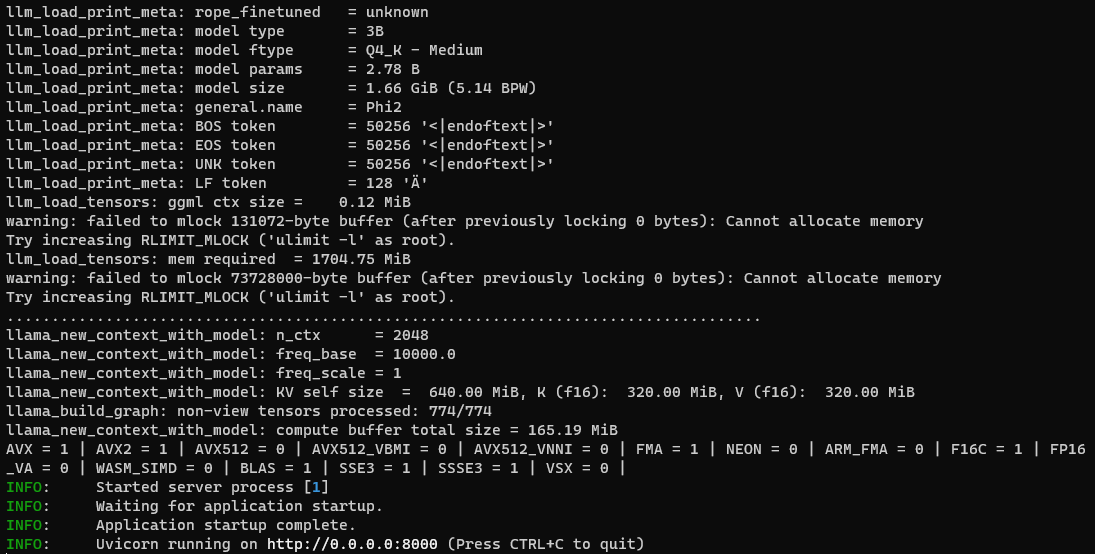
To resolve the “failed to mlock” warning, add –cap-add IPC_LOCK like so:
docker run --cap-add IPC_LOCK -p 8000:8000 --rm -it llama-microsoft-phi2:v0.2.24
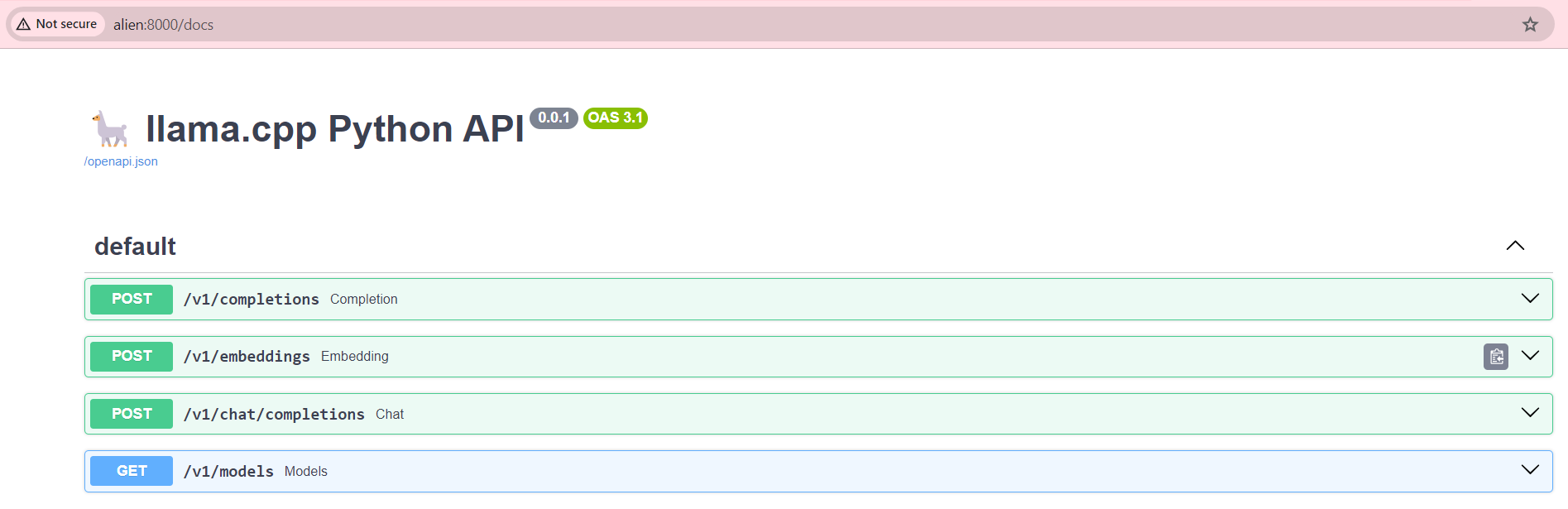
Docker Image Push and Deployment
Establishing a local registry on the new Ubuntu server is the first step:
sudo vi /etc/docker/daemon.json
Insert the following content into daemon.json:
{
"insecure-registries": [
"192.168.68.115:30500"
]
}
Configure Docker options:
sudo vi /etc/default/docker
Add the line:
DOCKER_OPTS="--config-file=/etc/docker/daemon.json"
Restart Docker:
sudo systemctl restart docker
Tag and push the image to the home lab:
docker image ls
docker tag llama-microsoft-phi2:v0.2.24 192.168.68.115:30500/llama-microsoft-phi2:v0.2.24
docker push 192.168.68.115:30500/llama-microsoft-phi2:v0.2.24
For larger image layers, bypass retry errors using:
sudo mkdir -p /etc/systemd/system/docker.service.d
sudo vi /etc/systemd/system/docker.service.d/http-proxy.conf
Add to http-proxy.conf:
[Service]
Environment="NO_PROXY=localhost,127.0.0.1,192.168.68.115"
Reload Docker:
sudo systemctl daemon-reload
sudo systemctl restart docker
Joining Home Lab as a K3S Node
Join as a node:
curl -sfL https://get.k3s.io | K3S_URL=https://192.168.68.115:6443 K3S_TOKEN=K10e848701b18977c63d7abfce920cf66c0f19bdd18a40862b2e7a14b89c4eb2742::server:ac92f2b7ccebbb46bf241bdaea3c99bf sh -
Configure the insecure registry for K3S agents:
sudo vi /etc/systemd/system/k3s-agent.service
# Restart k3s agent after the change
sudo systemctl daemon-reload
sudo systemctl restart k3s-agent
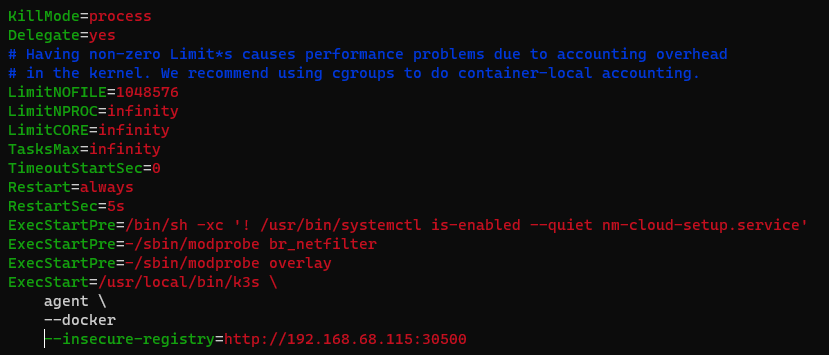
Change ExecStart of k3s-agent.service to:
ExecStart=/usr/local/bin/k3s \
agent \
--docker
--insecure-registry=http://192.168.68.115:30500
Deployment to K3S in Home Lab
Create a llama-phi2.yaml for deployment (IPC_LOCK setting for resolving “failed to mlock” warning):
apiVersion: apps/v1
kind: Deployment
metadata:
name: llama-phi2
namespace: llm
spec:
replicas: 1
selector:
matchLabels:
app: llama-phi2
template:
metadata:
labels:
app: llama-phi2
name: llama-phi2
spec:
containers:
- name: llama-phi2
image: 192.168.68.115:30500/llama-microsoft-phi2:v0.2.24
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "6Gi"
limits:
memory: "6Gi"
ports:
- containerPort: 8000
securityContext:
capabilities:
add:
- IPC_LOCK
imagePullSecrets:
- name: regcred
Deploy using:
kca llama-phi2.yaml
For service exposure, create llama-phi2-svc.yaml:
apiVersion: v1
kind: Service
metadata:
name: llama-phi2-svc
namespace: llm
spec:
selector:
app: llama-phi2
type: NodePort
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8000
nodePort: 30000
Apply to the K3S cluster:
kca llama-phi2-svc.yaml
Access the llama-phi2 server through nodePort 3000:
If you want a straight forward label-based match, you may use node selector to use a specific host to run the pod:
spec: nodeSelector: hostname: alien # Alternatively you may consider the default kubernetes.io/hostname: alien # By using the default value, we need not set the label
To label the node, you may use this:
kc label no alien hostname=alien
# Check current labels
kc get no --show-labels
# Re-deploy with the latest yaml change
kca llama-phi2-deploy.yaml
Troubleshooting
If k3s server tries to assign a brand new worker node, you may face similar “Illegal instruction (core dumped)” issue.
Add the folling command to your yaml file:
spec:
containers:
- name: llama-phi2
image: 192.168.68.115:30500/llama-microsoft-phi2:v0.2.24
command: ["/bin/sh", "-c", "tail -f /dev/null"]
# ... rest of the container spec ...
Get into the console of the pod from portainer:
# python3 -m llama_cpp.server --model /phi-2.Q4_K_M.gguf
Illegal instruction (core dumped)
From within the console, you may debug the python code:
# Use GDB to anaylze the core dump
apt-get install gdb
gdb python3
# Within GNU gdb, issue command; type quit to exit gdb
(gdb) run -m llama_cpp.server --verbose
This is the error which I faced:
warning: Error disabling address space randomization: Operation not permitted
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7f5e5b9a7700 (LWP 305)]
[New Thread 0x7f5e5b1a6700 (LWP 306)]
[New Thread 0x7f5e529a5700 (LWP 307)]
Thread 1 "python3" received signal SIGILL, Illegal instruction.
0x00007f5e5e21d34c in std::vector<std::pair<unsigned int, unsigned int>, std::allocator<std::pair<unsigned int, unsigned int> > >::vector(std::initializer_list<std::pair<unsigned int, unsigned int> >, std::allocator<std::pair<unsigned int, unsigned int> > const&) ()
from /usr/local/lib/python3.12/site-packages/llama_cpp/libllama.so
What I found out was that the image built from the Ubuntu server caused the above issue. After switching to my Windows machine and re-build, the error was resolved!