Building ChatBot for your PDF files with LangChain
-
2 mins read
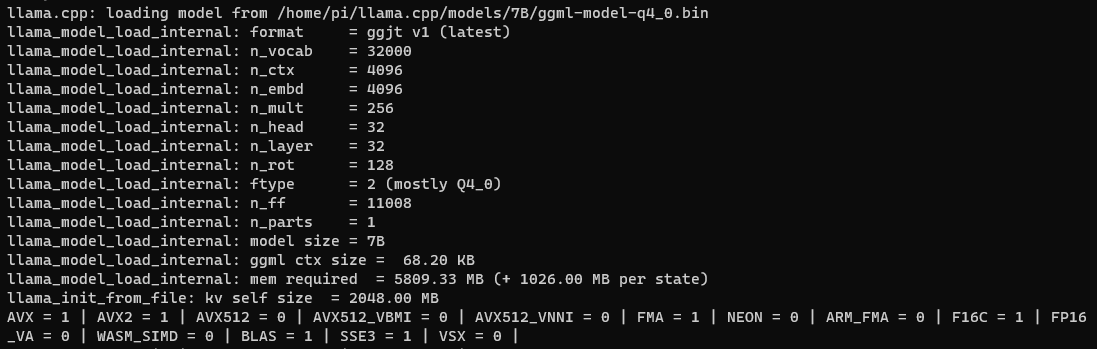
Extending the use case on the previous post, I will demostrate how you could ingest your own PDF file to your own LLaMa model in local machine.
Preparation
(2 mins)
Let’s start off by installing Chroma, the open-source embedding database:
pip install chromadb pypdf
Ingesting your PDF
(5 mins)
- For a start, I will ingest this Java-Design-Patterns file:
python3
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/home/pi/java-design-patterns-101.pdf")
document = loader.load()

- Next, I will split the document into chunks. Please change the chunk_size attributes based on your source contents and requirements.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1500, separator="\n")
texts = text_splitter.split_documents(document)
- We will be using the default Chroma’s embeddings. By default, Chroma uses all-MiniLM-L6-v2.
from langchain.vectorstores import Chroma
vectordb = Chroma.from_documents(texts, persist_directory=".", metadatas=[{"source": f"{i}-jdp"} for i in range(len(texts))])
vectordb.persist()
The chroma DB will be stored in the current directory, stored as chroma-collections.parquet, chroma-embeddings.parquest and index folder

It seems like the current codebase does not use default embedding function anymore. If you face this issue, you may provide the embeddings as such:
from langchain.embeddings import HuggingFaceEmbeddings embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") vectordb = Chroma.from_documents(texts, embeddings, persist_directory=".", metadatas=[{"source": f"{i}-jdp"} for i in range(len(texts))]) vectordb.persist()
To load from the persisted DB, you can use this instead:
from langchain.vectorstores import Chroma
vectordb = Chroma(persist_directory="/home/pi")
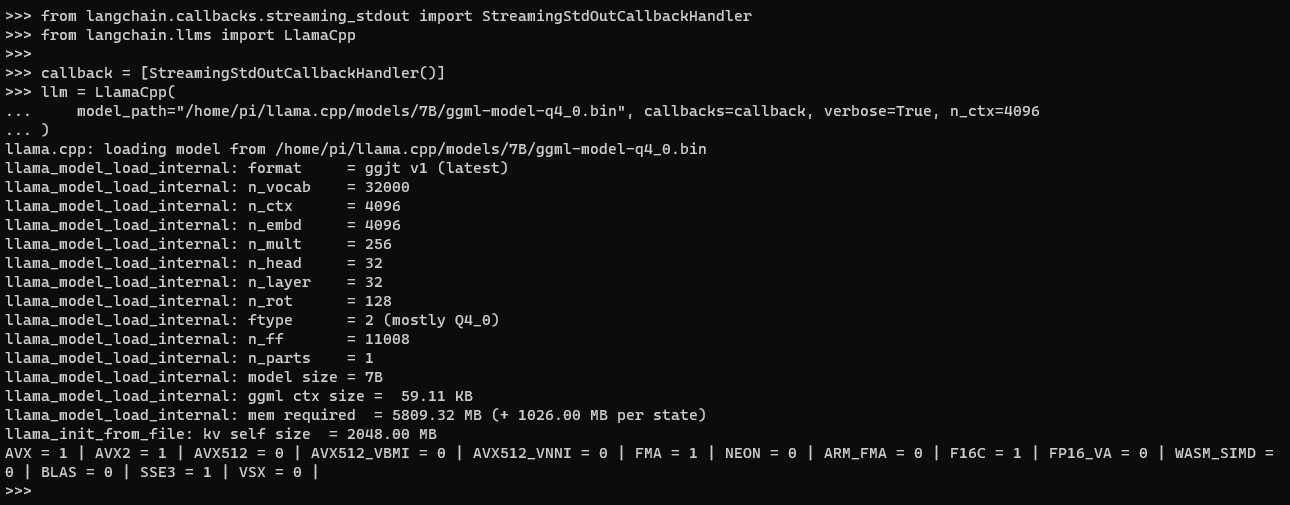
- To load our local llama model on the local machine:
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain.llms import LlamaCpp
callback = [StreamingStdOutCallbackHandler()]
llm = LlamaCpp(
model_path="/home/pi/llama.cpp/models/7B/ggml-model-q4_0.bin", callbacks=callback, verbose=True, n_ctx=4096
)
Question and Answering
(10 mins)
- Let’s do a question-answering with the PDF source over the vector database, with RetrievalQAWithSourcesChain
retriever = vectordb.as_retriever()
query="What is a Singleton pattern as described by David Gallardo? Summarize in less than 100 words for a beginner"
docs=retriever.get_relevant_documents(query)
from langchain.chains.question_answering import load_qa_chain
chain = load_qa_chain(llm, chain_type="stuff")
chain.run(input_documents=docs, question=query)

- You may learn about Index-related chains for combing your own data and start exploring question ansewering over your own documents! Happy chaining!
Running with OpenBLAS (optional)
(2 mins)
Referencing to issues#32, I manage to get it run with BLAS by re-installating llama-cpp-python:
LLAMA_OPENBLAS=on pip install --force-reinstall --ignore-installed --no-cache-dir llama-cpp-python
This is the run with BLAS=1: