Boosting Inference Speed: SSD and GPU Acceleration
In the relentless pursuit of optimal disk space and lightning-fast inference speeds, I embarked on an exciting upgrade journey by integrating the formidable Lexar NM790 M.2 2280 PCIe SSD. This blog post unfolds in two parts: the first chronicles the meticulous migration of my Windows 11 to this powerhouse SSD, while the second unveils the secrets behind the enhanced inferencing speed for the Langchain4j application.
Part 1: Seamless OS Migration with Clonezilla
Amidst a sea of software promising seamless disk cloning, I found solace in the reliability of Clonezilla, a robust open-source tool for disk imaging and cloning.
After securely installing the Lexar SSD into slot 2 of my PC, I tapped into the power of Clonezilla. Following the Clone your SSD or Hard Drive guide, I navigated through the process, opting for the -k1 option to create a proportional partition table.
The result? A seamlessly cloned SSD, now the master boot, offering a tangible boost in inferencing speed as all my LLM models found their new home on this high-performance SSD.
Part 2: GPU Acceleration Unleashed
Step 1: Installing CUDA for Windows
My journey continued with the installation of CUDA for Microsoft Windows. Armed with the NVIDIA CUDA Toolkit, I confirmed the successful installation using two simple PowerShell commands: nvcc –version and nvidia-smi.
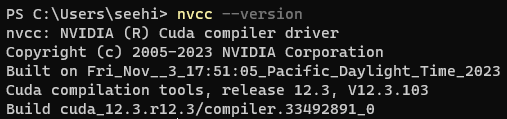
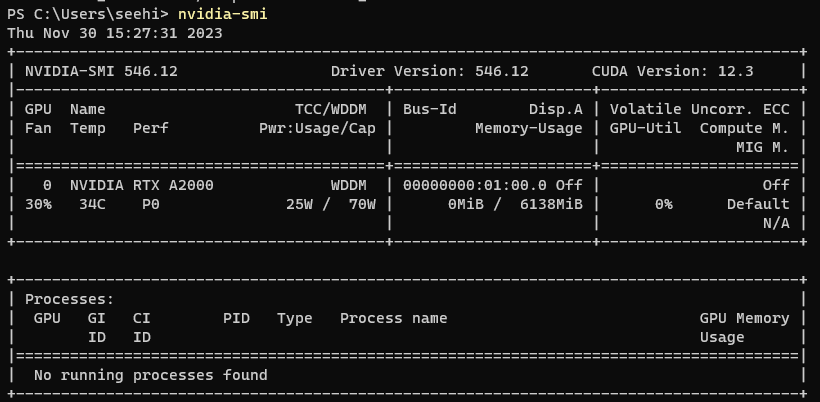
Step 2: NVIDIA Container Toolkit Magic
The next leg of this GPU odyssey involved the installation of the NVIDIA Container Toolkit. Delving into the realm of Windows Subsystem for Linux (WSL), I executed a series of commands to seamlessly integrate this toolkit into my environment.
# Setting up the APT repository and configuring it
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list \
&& \
sudo apt-get update
# install the NVIDIA container toolkit package
sudo apt-get install -y nvidia-container-toolkit
Configuring Docker for this newfound power involved a few more commands:
# Configuring containter runtime
sudo nvidia-ctk runtime configure --runtime=docker
# Restarting docker daemon
sudo systemctl restart docker
# If docker.service is not found, you may reinstall and reconfigure runtime
sudo apt-get --reinstall install docker.io
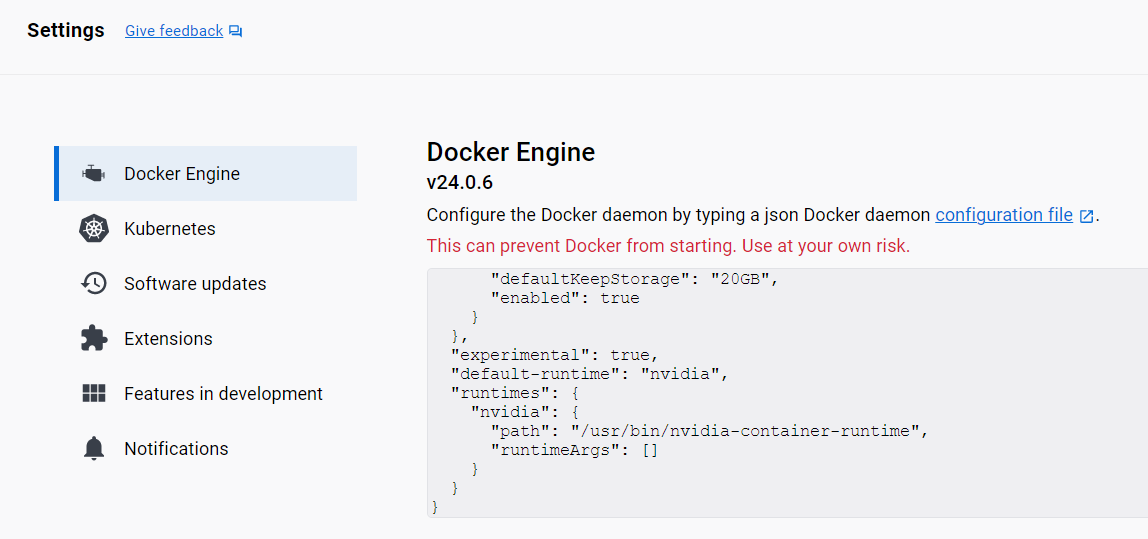
From the Docker Desktop settings, I ventured into extra configurations, applied the changes, and restarted:
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
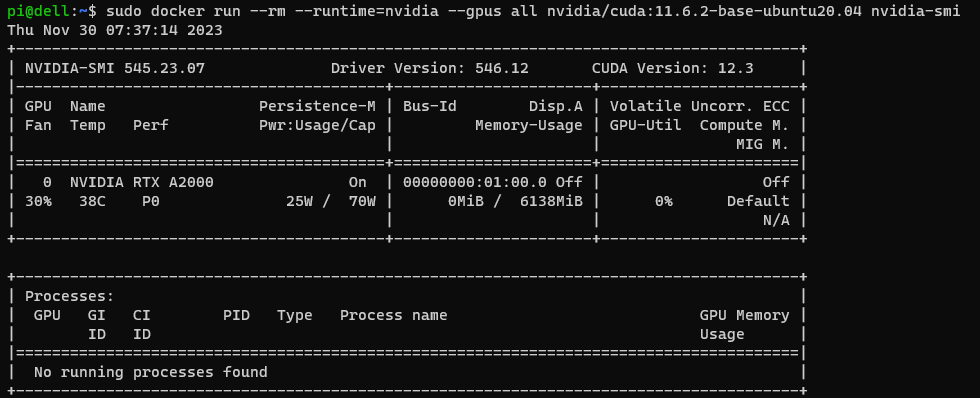
The grand test unfolded with a sample workload command:
sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
Be vigilant! Without the Docker Desktop setting, you might encounter the ominous error depicted below:

The Grand Finale
Bringing it all together, the magic command to launch the LocalAI image in a GPU Docker container was unveiled:
docker run -p 8080:8080 -v c:/local-ai-models:/models -ti --rm quay.io/go-skynet/local-ai:v1.40.0-cublas-cuda12 --models-path /models --context-size 2000 --threads 8 --debug=true
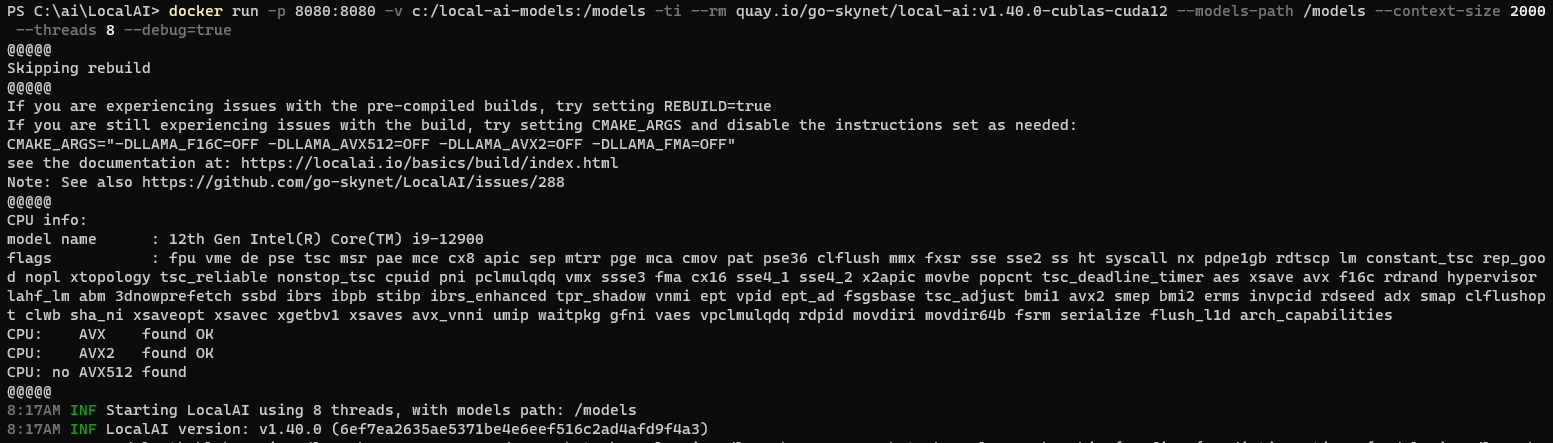
And behold, as we queried using the WizardLM model, the GPU acceleration became apparent, turning our tech realm into a high-speed universe.
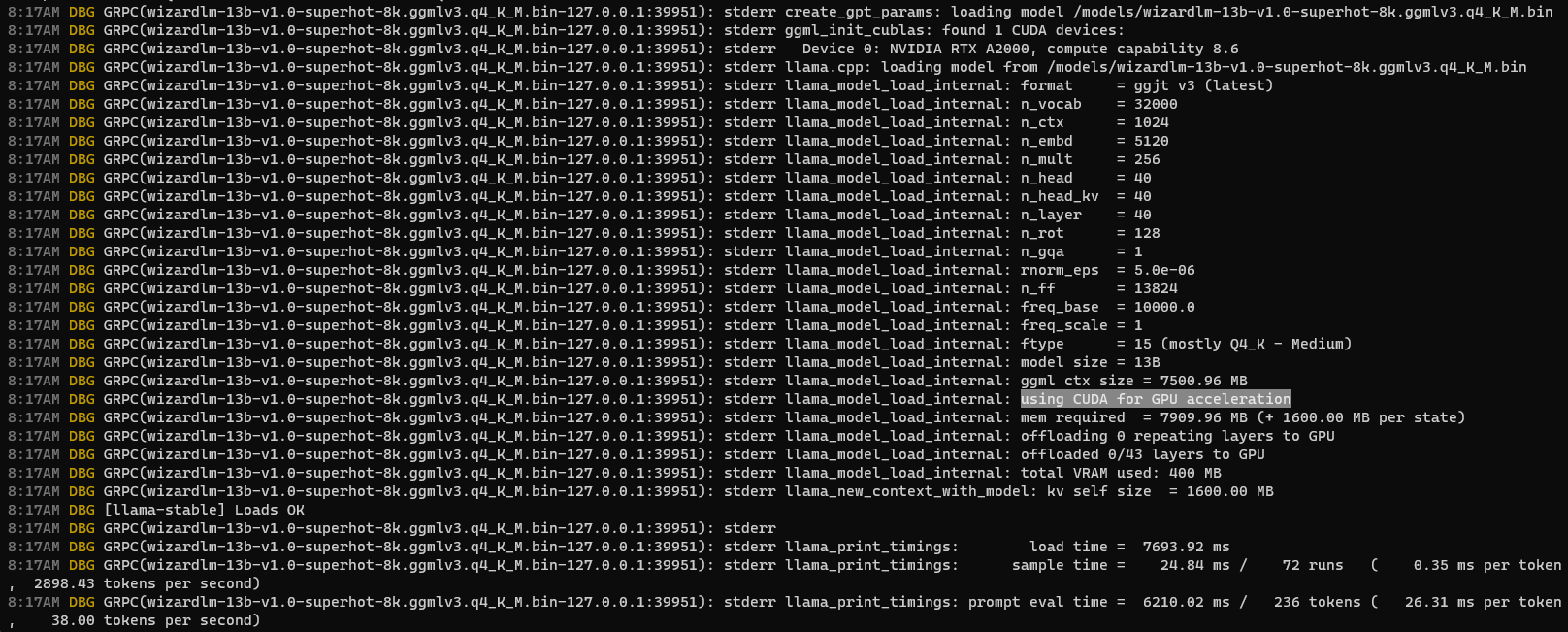
Comparing it to the past, the results spoke for themselves—our inference speed had ascended to new heights!
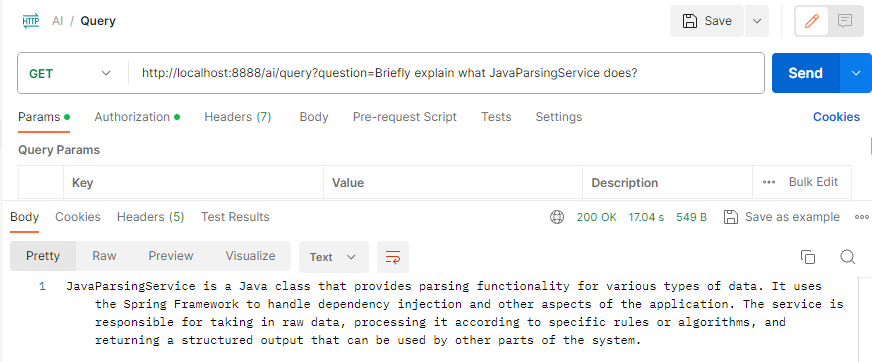
Parting Thoughts
In this journey, we’ve showcased the synergy of SSD storage and GPU acceleration, breathing life into the WizardLM model and witnessing a remarkable surge in inference speed. A testament to the relentless pursuit of tech optimization, this transformation opens new doors for Langchain4j enthusiasts, inviting you to explore the boundless possibilities of elevated performance. Elevate your tech game; dive into the future with Langchain4j and redefine what’s possible!