Autofill PDF with LangChain and LangFlow
In this blog post, we will explore the usage of LangFlow, a Python library available on PyPI, to streamline the process of capturing ideas and conducting proof-of-concepts for our intended use case. Considering the current “trend” of tech layoffs, there might be a time (touch wood) where there is a need to go for interviews and fill-up various interview forms that require filling out personal information. Building upon the previous blog post on running GPT4All for PostgreSQL with LangChain (referenced here), we will now leverage LangFlow and OpenAI to automate the population of a sample employment form with our personal data stored in PostgreSQL.
Let’s dive into the details and explore how LangFlow and OpenAI can simplify the auto-filling of employment forms, making the process more efficient and time-saving.
Setup
To get started with auto-filling a sample employment form using LangFlow and OpenAI, follow these steps:
Step 1: Install LangFlow
You can install LangFlow from PyPI using pip. Open your terminal or command prompt and execute the following command:
pip install langflow
Step 2: Run LangFlow
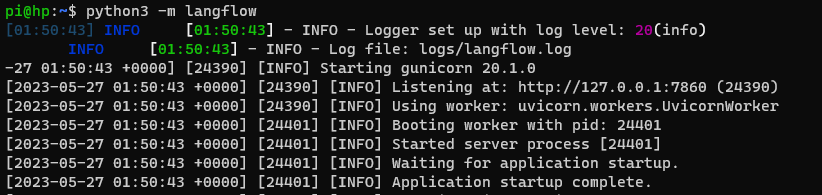
Next, run LangFlow by executing the following command in your terminal or command prompt:
python3 -m langflow
This will start the LangFlow application.
Step 3: Create the PostgreSQL Table
Create a simple table named “person” in your PostgreSQL database, where you will store all the required information for an employment application form. Use the following SQL query to create the table:
CREATE TABLE person (
id SERIAL PRIMARY KEY,
firstname VARCHAR(50),
lastname VARCHAR(50),
address VARCHAR(100),
email VARCHAR(100)
);
Step 4: Download the Sample Fillable PDF
Download the sample fillable PDF form template that you want to auto-fill. You can find a sample fillable PDF form template here.
With these setup steps completed, you are now ready to proceed with auto-filling the sample employment form using LangFlow and OpenAI.
LangFlow Prototype and Potential Issues
During the process of prototyping my use case using LangFlow, I encountered some challenges that I believe are worth highlighting. Since there were no existing examples available for SQLDatabaseChain in the LangFlow documentation, I had to explore different combinations and configurations to make it work. However, despite my efforts, I encountered the following error:
Error: too many values to unpack (expected 2)
This error message indicates that there might be an issue related to the number of values being unpacked in the workflow. It took some time and investigation to identify the root cause of this error.
To tackle the problem, I carefully examined the LangFlow repository and made sure that the input data provided to each step was in the correct format. I also verified the number of output values produced by each step to ensure they matched the expected number of values for the subsequent steps. However, the error persisted.
The LangFlow diagram shown in the provided screenshot represents the flow I created to auto-fill the PDF form. Although it didn’t work as intended, it served as a starting point for my exploration:
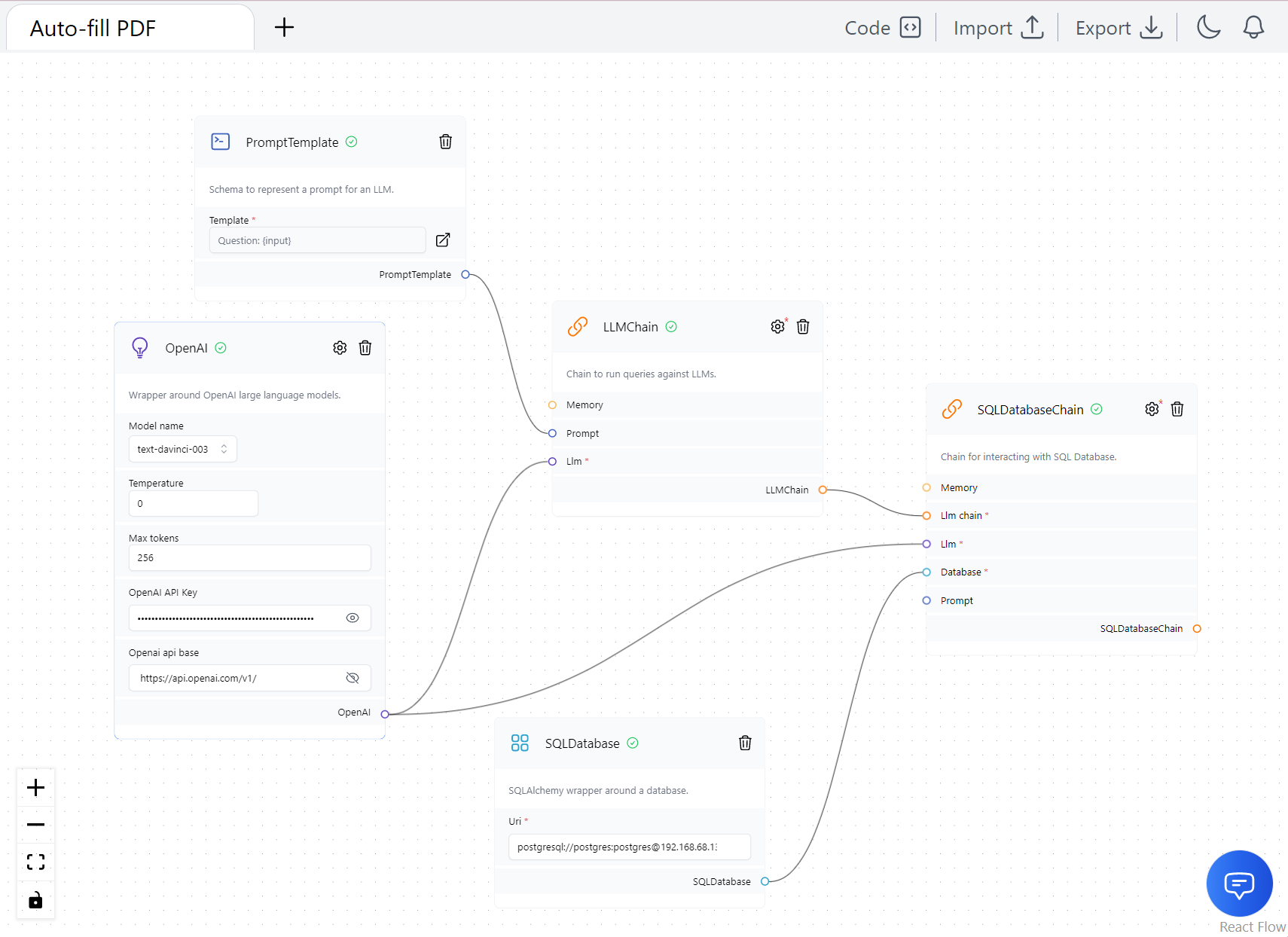
From the next section, I will proceed with the auto-filling proof-of-concepts using llama.cpp, langchain and postgreSQL.
Preparation
Before we proceed with auto-filling the sample employment form, we need to extract the form fields from the fillable PDF. Follow the steps below:
- Import the necessary libraries, PyPDF2 and json:
import PyPDF2, json
- Open the fillable PDF file using the open() function, and create a PDF reader object:
pdf_file = open('fill-in-pdf-form-template.pdf', 'rb')
pdf_reader = PyPDF2.PdfReader(pdf_file)
- Retrieve the form text fields from the PDF using the get_form_text_fields() method:
form_text_fields = pdf_reader.get_form_text_fields()
- Create a dictionary to store the form field names as keys and placeholder values as values:
json_data = {}
for form_text_field in form_text_fields:
json_data[form_text_field] = f"<{form_text_field.lower()}>"
- Convert the dictionary to a JSON string using the json.dumps() function:
json_string = json.dumps(json_data)
print(json_string)
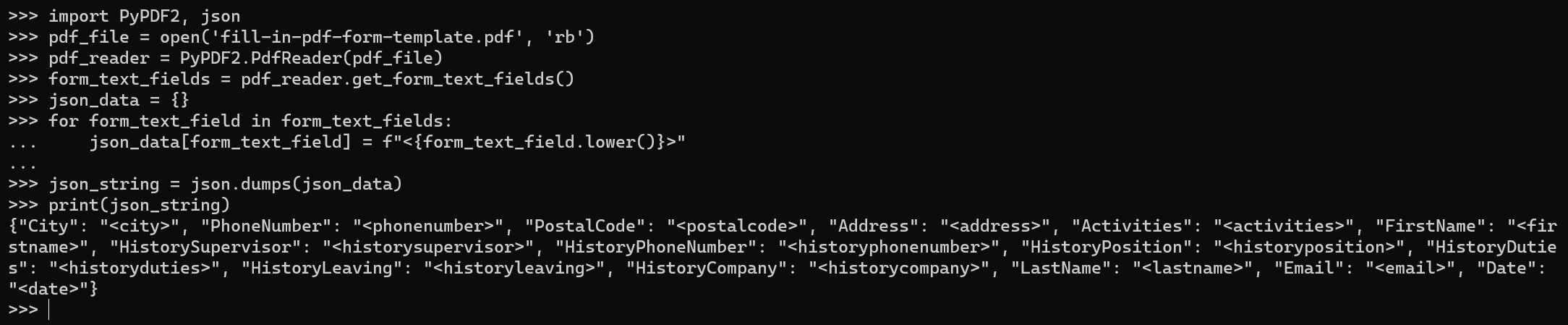
The generated JSON, using JSON Pretty Print, will look like this:
{
"City": "<city>",
"PhoneNumber": "<phonenumber>",
"PostalCode": "<postalcode>",
"Address": "<address>",
"Activities": "<activities>",
"FirstName": "<firstname>",
"HistorySupervisor": "<historysupervisor>",
"HistoryPhoneNumber": "<historyphonenumber>",
"HistoryPosition": "<historyposition>",
"HistoryDuties": "<historyduties>",
"HistoryLeaving": "<historyleaving>",
"HistoryCompany": "<historycompany>",
"LastName": "<lastname>",
"Email": "<email>",
"Date": "<date>"
}
This JSON data will be used to map the form field names to the corresponding placeholder values when auto-filling the employment form.
The LLaMA Way: Retrieving PostgreSQL Data with LangChain
In my previous post, I discussed on how to go about in building a basic chain with LangChain to ensure the privacy of sensitive data, despite the trade-off of longer processing time. Since then, there has been a recent breaking change in the quantisation method of llama.cpp, as highlighted in a recent pull request. To adapt to this change, I rebuilt the latest code from the llama.cpp repository and obtained the updated model from this source.
To begin, let’s set up the LLM model using LangChain:
from langchain.llms import LlamaCpp
from langchain import PromptTemplate, LLMChain
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
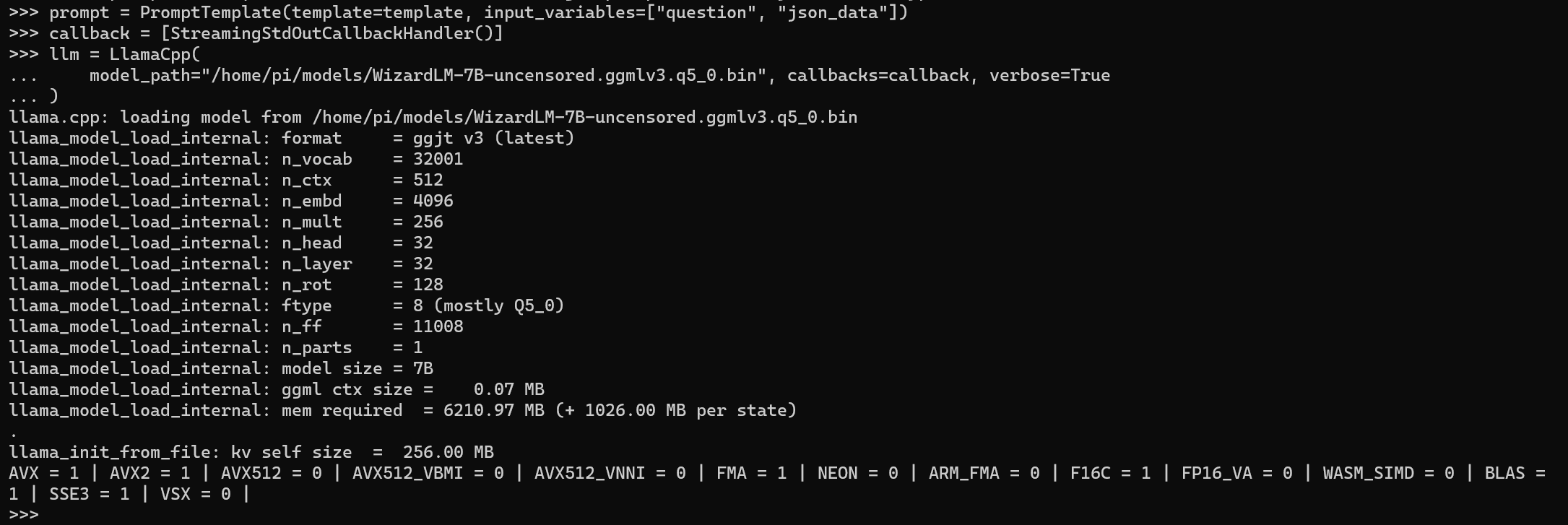
llm = LlamaCpp(
model_path="/home/pi/models/WizardLM-7B-uncensored.ggmlv3.q5_0.bin", n_ctx=2048, verbose=True
)
It’s important to note that the model format we are using is ggjt v3 (latest). Here’s an image of the running model:
Now, let’s move on to setting up the PostgreSQL database using LangChain:
from langchain import SQLDatabase, SQLDatabaseChain
db = SQLDatabase.from_uri("postgresql://postgres:postgres@192.168.68.132:5432/postgres", include_tables=["person"])
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
default_template = """
Given an input question, first create a syntactically correct postgresql query to run, then look at the results of the query and return the answer.
Use the following format:
Question: Question here
SQLQuery: SQL Query to run
SQLResult: Result of the SQLQuery
Answer: Final answer here
{question}
"""
query = "Get details of each person in the person table and store the result in json format, with the key as the database column name and value as the raw value retrieved from DB"
question = default_template.format(question=query)
result = db_chain.run(query=query)
print(result)
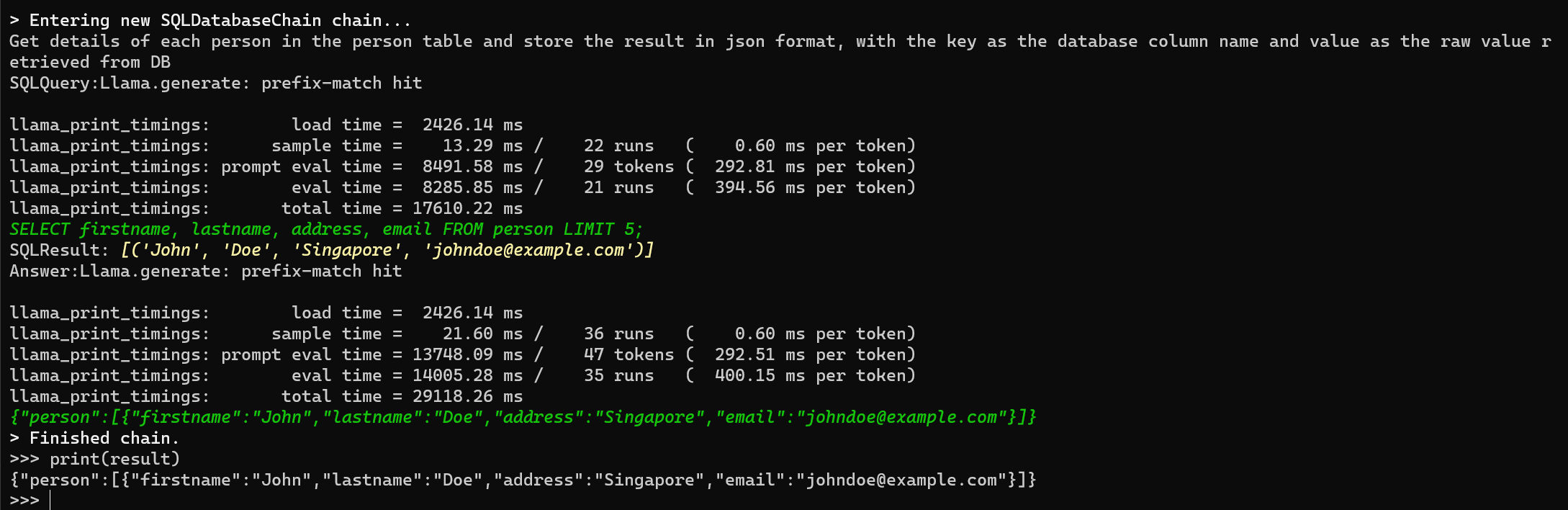
With this setup, LangChain intelligently retrieves data from the PostgreSQL database using the LLM model and allows you to store the result in a specified format for further processing or analysis.
Auto-filling PDF
In the final step of the process, we focus on manipulating the data in Python to interpolate the result into the json_string (obtained in previous section) and generate the final auto-filled PDF. Let’s go through the process:
First, we extract the necessary data from the result string and interpolate it into the json_string using string formatting:
result_dict = json.loads(result)
person_data = result_dict["person"][0]
interpolated_json_string = json_string
for key, value in person_data.items():
interpolated_json_string = interpolated_json_string.replace(f"<{key}>", str(value))
print(interpolated_json_string)
This is how the interpolated_json_string looks like:
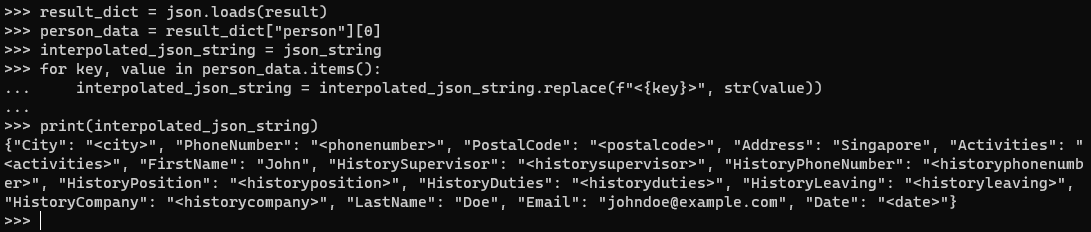
Next, we use regular expressions to replace all occurrences of <XXX> (where XXX represents any arbitrary value) with “N/A” in the interpolated_json
import re
pattern = r"<[^>]+>"
interpolated_string = re.sub(pattern, "N/A", interpolated_json_string)
print(interpolated_string)
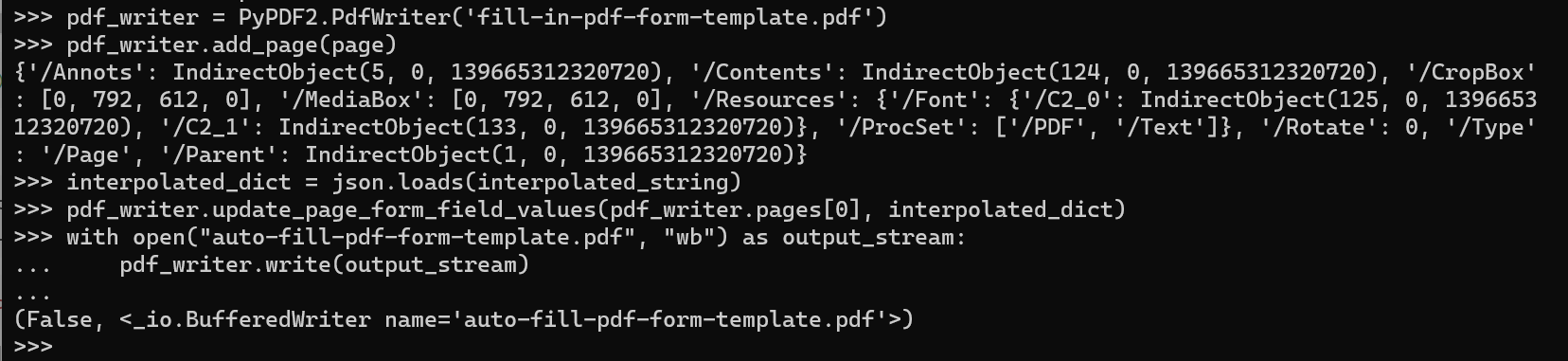
Finally, we rewrite the PDF by updating the form field values with the interpolated data:
page = pdf_reader.pages[0]
pdf_writer = PyPDF2.PdfWriter('fill-in-pdf-form-template.pdf')
pdf_writer.add_page(page)
interpolated_dict = json.loads(interpolated_string)
pdf_writer.update_page_form_field_values(pdf_writer.pages[0], interpolated_dict)
with open("auto-fill-pdf-form-template.pdf", "wb") as output_stream:
pdf_writer.write(output_stream)
Here’s how the pdf_writer.write output and the final auto-fill PDF:
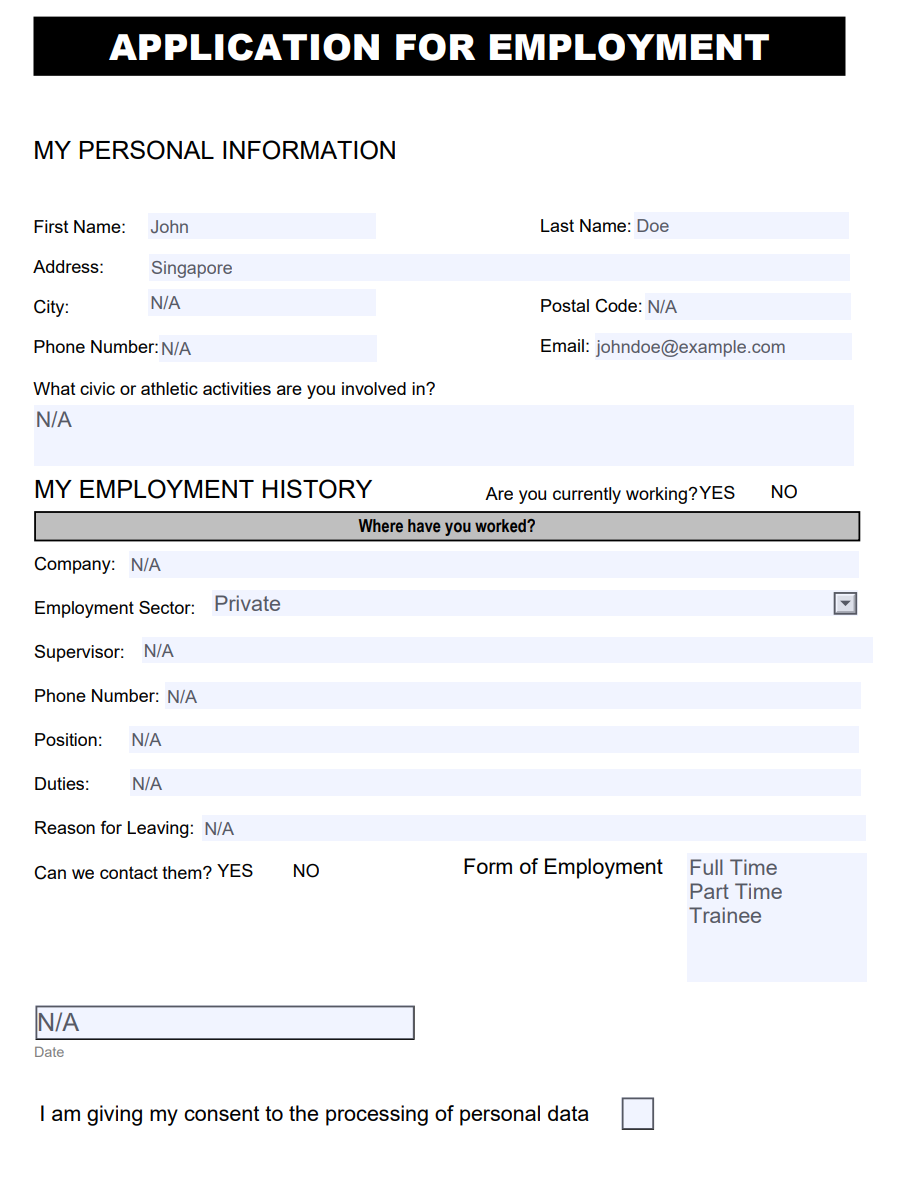
Following these steps, you can successfully auto-fill the PDF form with the data retrieved from the database query.