AI Integration: LocalAI, Chroma, and Langchain4j
Referring to the Building an AI application with Langchaing4j guide, the deployment of necessary Docker images, LocalAI, and Chroma to our Home Lab is outlined.
Creating custom LocalAI image
Begin with pulling the latest image using the easy docker setup guide:
docker pull quay.io/go-skynet/local-ai:v2.2.0
Now, run LocalAI from the ~/localai folder and download a model:
docker run -p 8080:8080 -v $PWD/models:/models -ti --rm quay.io/go-skynet/local-ai:v2.2.0 --models-path /models --context-size 2000 --threads 4 --debug=true
# The model will be downloaded to ~/localai/models folder
curl http://127.0.0.1:8080/models/apply -H "Content-Type: application/json" -d '{"url": "github:go-skynet/model-gallery/gpt4all-j.yaml"}'

Next, create a Dockerfile and include the downloaded model under our custom image:
FROM quay.io/go-skynet/local-ai:v2.2.0
ENV HOST 0.0.0.0
RUN mkdir /models
COPY ./models /models
EXPOSE 8080
CMD ["/usr/bin/local-ai"]
Build it with:
docker build . -t localai:v2.2.0
# Test run the custom image
docker run -p 8080:8080 -ti --rm localai:v2.2.0 --models-path /models --context-size 2000 --threads 4 --debug=true
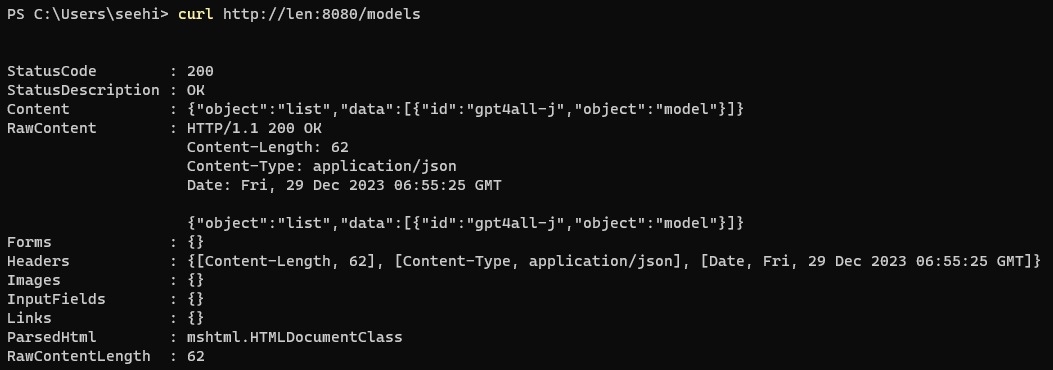
# Check the model
curl http://len:8080/models
# Tag the image
docker tag localai:v2.2.0 192.168.68.115:30500/localai:v2.2.0
# Push the image (refer "Docker Image Push and Deployment" of Deploying OpenAI-Compatible LLAMA CPP Server in Home Lab with K3S)
docker push 192.168.68.115:30500/localai:v2.2.0
Deploying Custom LocalAI to Home Lab
This is the localai-deploy.yaml file targeting to run from the len server:
apiVersion: apps/v1
kind: Deployment
metadata:
name: localai-server
namespace: llm
spec:
replicas: 1
selector:
matchLabels:
app: localai-server
template:
metadata:
labels:
app: localai-server
spec:
containers:
- name: localai-server
image: 192.168.68.115:30500/localai:v2.2.0
ports:
- containerPort: 8080
args:
- "--models-path"
- "/models"
nodeSelector:
kubernetes.io/hostname: len
This is the localai-svc.yaml file, exposing nodePort as 30808:
apiVersion: v1
kind: Service
metadata:
name: localai-server-svc
namespace: llm
spec:
selector:
app: localai-server
type: NodePort
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8080
nodePort: 30808
Deploy to the Home Lab:
kca localai-deploy.yaml
kca localai-svc.yaml

If you are unable to pull the image from the agent, please refer to my previous post and perform the following:
sudo vi /etc/systemd/system/k3s-agent.service
Add the following at the bottom of the existing file:
ExecStart=/usr/local/bin/k3s \
agent \
--docker
--insecure-registry=http://192.168.68.115:30500
Restart the k3s-agent:
sudo systemctl daemon-reload
sudo systemctl restart k3s-agent
Deploying Chroma to Home Lab
The HostPath /docker-data/chroma will be created in the HostName len. This is the chroma-deploy.yaml file to be deployed to our Home Lab:
apiVersion: apps/v1
kind: Deployment
metadata:
name: chroma-server
namespace: llm
spec:
replicas: 1
selector:
matchLabels:
app: chroma-server
template:
metadata:
labels:
app: chroma-server
name: chroma-server
spec:
containers:
- name: chroma-server
image: ghcr.io/chroma-core/chroma:0.4.21
ports:
- containerPort: 8000
volumeMounts:
- name: chroma-data
mountPath: /chroma/chroma
volumes:
- name: chroma-data
hostPath:
path: "/docker-data/chroma"
nodeSelector:
kubernetes.io/hostname: len
To expose this service for our usage, this is the chroma-svc.yaml:
apiVersion: v1
kind: Service
metadata:
name: chroma-server-svc
namespace: llm
spec:
selector:
app: chroma-server
type: NodePort
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8000
nodePort: 30800
As usual, we will deploy using our alias command:
kca chroma-deploy.yaml
kca chroma-svc.yaml
Integrating Langchain4j Application with Home Lab
Returning to the Langchain4j application codebase, certain changes are required to integrate our application into the Home Lab.
Embed Endpoint Modification
With the above setup, this is the URL change (http://len:30800) made to EmbeddingServer.java:
private EmbeddingStore<TextSegment> getEmbeddingStore() {
if (embeddingStore == null) {
embeddingStore = ChromaEmbeddingStore.builder().baseUrl("http://len:30800")
.collectionName(randomUUID()).build();
}
return embeddingStore;
}
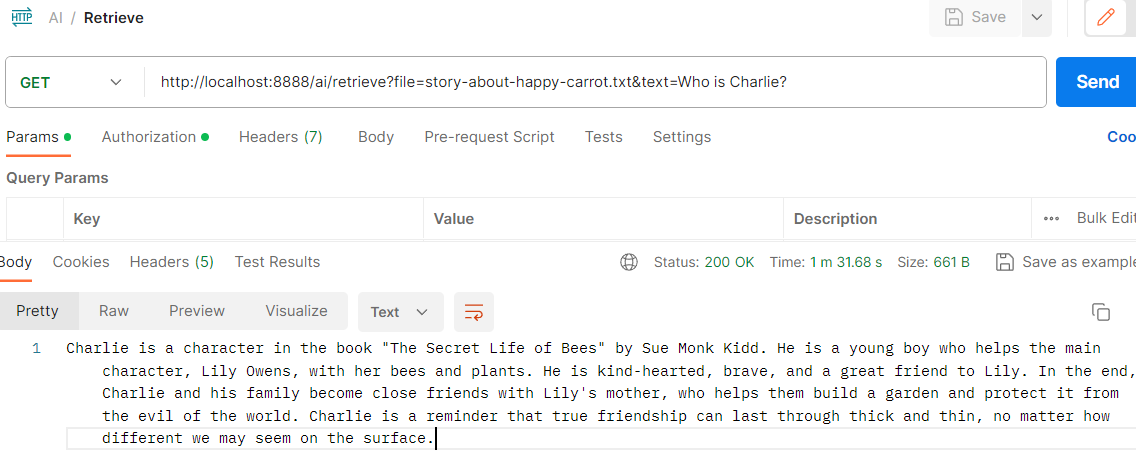
Retrieve Endpoint Modification
Based on our LocalAI setup, in the ModelService.java, the LOCAL_AI_URL is changed to:
private static final String LOCAL_AI_URL = "http://len:30808";