Pi Cluster with Longhorn

By running Raspberry PI Cluster with Longhorn, you will have a simplified, easy to deploy cloud-native persistent block storage
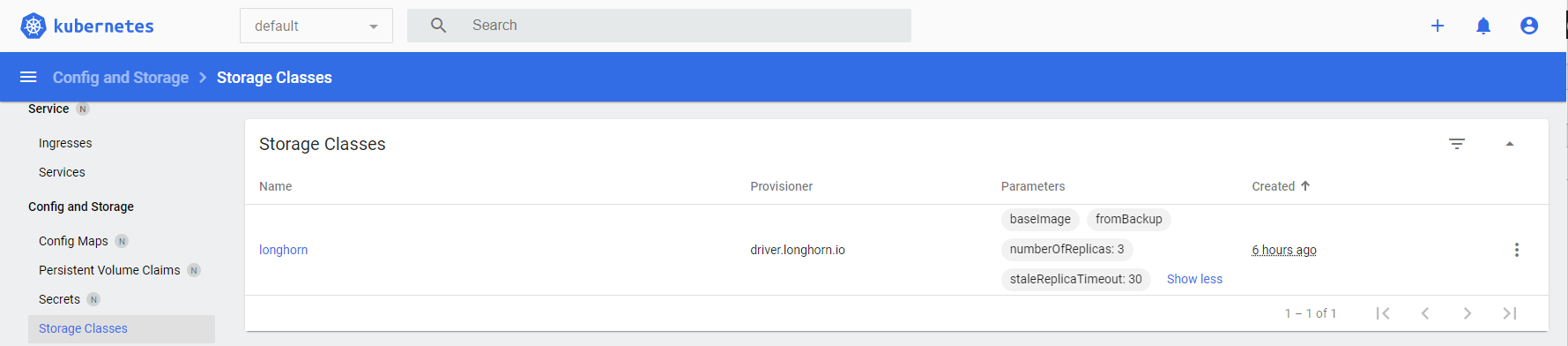
Raspberry Pi Cluster and Longhorn
(Total Setup Time: 30 mins)
In this section, I will install Longhorn, a highly available persistance storage for Kubernetes. This guide assumes that you have a working Raspberry PI Cluster. If you do not have, please follow Kubernetes Cluster with Ansible or HA Kubernetes Pi Cluster (Part I).
Preparation
(10 mins)
First, you need to install helm.
curl https://baltocdn.com/helm/signing.asc | sudo apt-key add -
sudo apt-get install apt-transport-https --yes
echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
# Check helm version
helm version
# Helm version result
version.BuildInfo{Version:"v3.6.0", GitCommit:"7f2df6467771a75f5646b7f12afb408590ed1755", GitTreeState:"clean", GoVersion:"go1.16.3"}
Second, for the managing of Calico resources, I installed the command line interface.
curl -o calicoctl -O -L https://github.com/projectcalico/calicoctl/releases/download/v3.18.4/calicoctl-linux-arm64
chmod +x calicoctl
./calicoctl version
# Export configuration
export KUBECONFIG=~/.kube/config
export DATASTORE_TYPE=kubernetes
# Check the configuration
calicoctl get workloadendpoints
calicoctl get nodes
Third, if you wish to, you may install kubernetes-dashboard with these commands:
# Installs Web UI
curl https://raw.githubusercontent.com/kubernetes/dashboard/v2.2.0/aio/deploy/recommended.yaml -o kubernetes-dashboard.yaml
kubectl apply -f kubernetes-dashboard.yaml
# Creates cluster-admin role
kubectl create serviceaccount dashboard
kubectl create clusterrolebinding dashboard --clusterrole=cluster-admin --serviceaccount=default:dashboard
# Gets login token
kubectl get secrets
kubectl describe secret dashboard-token-7xmhx
# Runs proxy on your host machine
kubectl proxy
Finally, you may access the Kubernetes Web UI by pointing to:
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
Installing Longhorn
(20 mins)
First, following the official guide, please run environment_check.sh and verify that all is good to go.
Second, install Longhorn with Helm 3 with these commands:
kubectl create namespace longhorn-system
helm install longhorn longhorn/longhorn --namespace longhorn-system
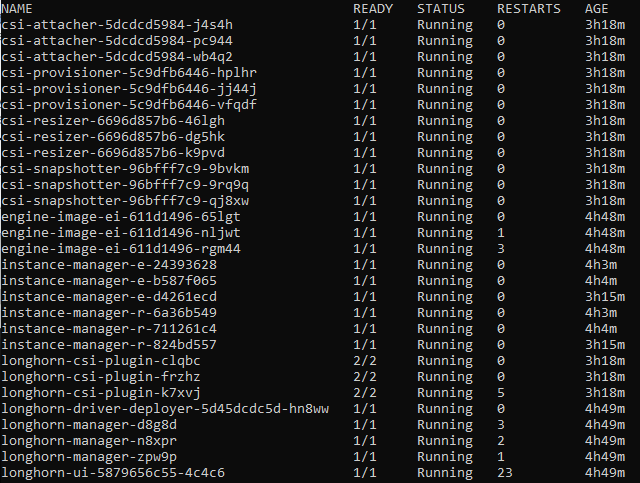
# Confirm that deployment is successful (this might take quite a while)
watch kubectl get pod -n longhorn-system
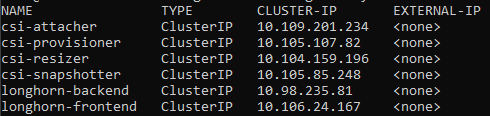
Third, you may access the Longhorn using these commands:
# Get name of longhorn-frontend
kubectl get svc -n longhorn-system
# Runs port-forward on your host machine
kubectl port-forward services/longhorn-frontend 8080:http -n longhorn-system
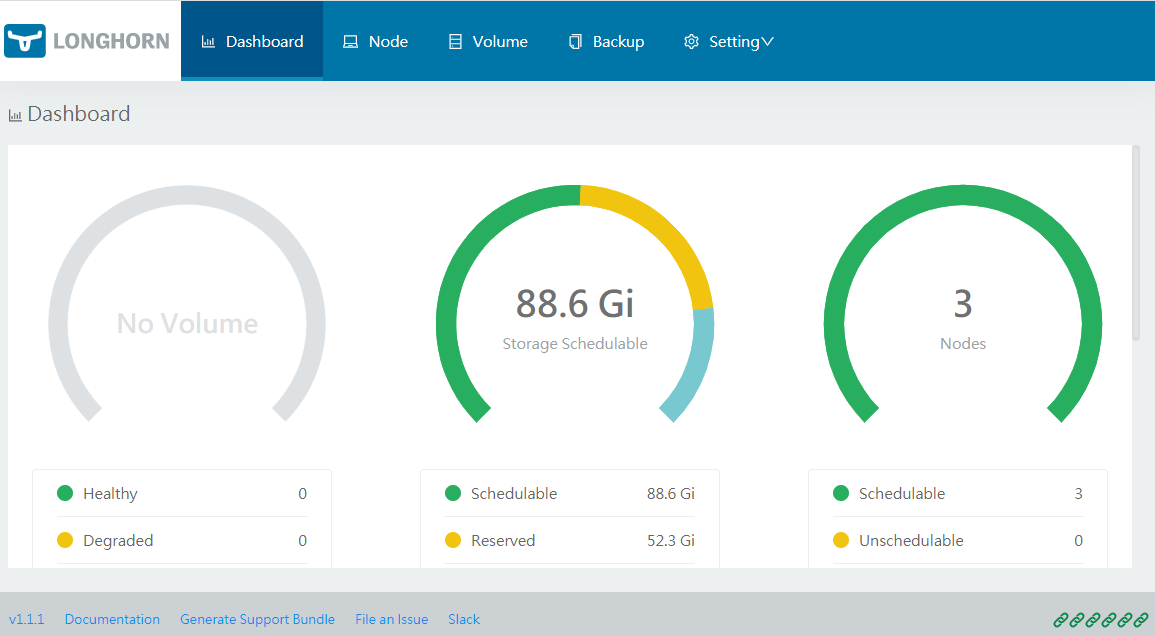
That’s it! The Raspberry PI Cluster with Longhorn is ready! Now, you have a highly availale persistance storage.
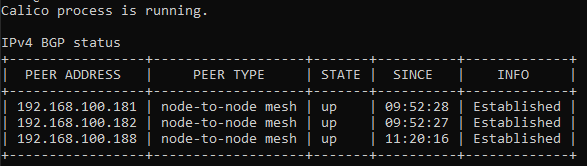
Troubleshooting
Calico node running but show up as 0/1
With the CLI command, calicoctl node status, I realized that the peer address are in different range.
# Check IP address
ip addr
# Re-configure to using same interface
kubectl set env daemonset/calico-node -n kube-system IP_AUTODETECTION_METHOD=interface=eth0
# Re-apply Kubernetes setting
kubectl apply -f ~/calico-etcd.yaml
longhorn-system namespace deletion stuck in terminating
While uninstalling Longhorn, I faced this issue.
helm uninstall longhorn -n longhorn-system
kubectl delete namespace longhorn-system
# Run this command when namespace deletion takes forever
kubectl get namespace longhorn-system -o json \
| tr -d "\n" | sed "s/\"finalizers\": \[[^]]\+\]/\"finalizers\": []/" \
| kubectl replace --raw /api/v1/namespaces/longhorn-system/finalize -f -
Error: rendered manifests contain a resource that already exists.
During re-installing of Longhorn, I realized some of the custom resources definition were not removed.
# Check if there are any crd ending with longhorn.io
kubectl get crd
# Delete each of those
kubectl patch crd/engineimages.longhorn.io -p '{"metadata":{"finalizers":[]}}' --type=merge
kubectl patch crd/instancemanagers.longhorn.io -p '{"metadata":{"finalizers":[]}}' --type=merge
Node does not appear in Longhorn
You may check on the taint value if any of the master nodes are not in Longhorn.
kubectl describe node master3
# Sample result
...
Taints: node-role.kubernetes.io/master:NoSchedule
...
# Remove the taintness from master3
kubectl taint node master3 node-role.kubernetes.io/master:NoSchedule-