From Model to HDB App
Building on my previous post, this article outlines how to move the selected features into a Kubeflow Pipeline (KFP) for a full model training and deployment workflow. The pipeline fetches input data from S3-compatible MinIO, trains a model using XGBoost with optimized feature selection, and deploys it via KServe. At the end of this journey, a Streamlit app enables users to make resale price predictions by entering flat attributes.
Deploying the InferenceService
Following the official KServe documentation, let’s begin by setting up the necessary components to enable model inference from an S3 backend.
1. Create Service Account
Define a service account that references the secret used to access MinIO.
kubectl apply -f s3-secret.yaml
# s3-secret.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: sa
namespace: kubeflow-user-example-com
secrets:
- name: minio-creds
2. Create S3 Secret
Configure your secret to include the MinIO credentials and required annotations for KServe to read from the S3 bucket.
kubectl apply -f secret-minio.yaml
# secret-minio.yaml
apiVersion: v1
kind: Secret
metadata:
name: minio-creds
namespace: kubeflow-user-example-com
annotations:
serving.kserve.io/s3-endpoint: "minio-service.kubeflow:9000"
serving.kserve.io/s3-usehttps: "0"
serving.kserve.io/s3-useanoncredential: "false"
type: Opaque
stringData:
AWS_ACCESS_KEY_ID: "minio"
AWS_SECRET_ACCESS_KEY: "minio123"
3. Deploy the InferenceService
Using the XGBoost serving guide, deploy the model. This step will also be handled automatically within the pipeline’s Step 6.
Note: Ensure the storageUri points to the correct S3 path that contains the XGBoost .bst model file.
kubectl apply -f kserve-inference.yaml --server-side=true
# Sample S3 minio url
# storageUri: "s3://mlpipeline/v2/artifacts/hdb-xgboost-retraining-pipeline-multi-step/053453f4-8e52-4e4a-b2b1-1f8658b92b54/train-model/15ee1507-42e0-4a05-b06f-bd0fa12a7a42/output_model"
# kserve-inference.yaml
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: hdb-resale-xgb
namespace: kubeflow-user-example-com
annotations:
autoscaling.knative.dev/maxScale: '1'
autoscaling.knative.dev/minScale: '0'
spec:
predictor:
serviceAccountName: sa
model:
modelFormat:
name: xgboost
protocolVersion: v2
runtime: kserve-xgbserver
storageUri: "s3://mlpipeline/hdb-resale-data/xgb-model-test/model.bst"
4. Grant Istio Access
To allow prediction requests, create an Istio AuthorizationPolicy that explicitly allows POST and GET operations on the deployed model endpoint.
kubectl apply -f allow-hdb-xgb-policy.yaml
# allow-hdb-xgb-policy.yaml
apiVersion: security.istio.io/v1
kind: AuthorizationPolicy
metadata:
name: allow-hdb-resale-xgb-access
namespace: kubeflow-user-example-com
spec:
selector:
matchLabels:
serving.kserve.io/inferenceservice: hdb-resale-xgb
action: ALLOW
rules:
- to:
- operation:
methods: ["POST","GET"]
5. Run a Prediction
Once the pipeline completes successfully, prepare an inference input JSON file and use curl to invoke the model endpoint. The output will contain the predicted resale prices.
import json
payload = {
"inputs": [{
"name": "input-0",
"shape": [5, 1],
"datatype": "FP32",
"data": [
0.4311926605504587,
0.2844036697247706,
0.27522935779816515,
0.15137614678899083,
0.4357798165137615
]
}]
}
with open("inference_input.json", "w") as f:
json.dump(payload, f, indent=2)
SERVICE_URL="http://hdb-resale-xgb.kubeflow-user-example-com.svc.cluster.local"
MODEL_NAME="hdb-resale-xgb"
# Construct the V2 inference endpoint path
INFERENCE_ENDPOINT="${SERVICE_URL}/v2/models/${MODEL_NAME}/infer"
echo "Sending request to: ${INFERENCE_ENDPOINT}"
curl -v -H "Content-Type: application/json" "${INFERENCE_ENDPOINT}" -d @inference_input.json
# Sample Output
# * Trying 10.98.223.247:80...
# * Connected to hdb-resale-xgb.kubeflow-user-example-com.svc.cluster.local (10.98.223.247) port 80 (#0)
# > POST /v2/models/hdb-resale-xgb/infer HTTP/1.1
# > Host: hdb-resale-xgb.kubeflow-user-example-com.svc.cluster.local
# ...
# <
# * Connection #0 to host hdb-resale-xgb.kubeflow-user-example-com.svc.cluster.local left intact
# {"model_name":"hdb-resale-xgb","model_version":null,"id":"6d902b7b-a172-4d14-84dd-cc8a004f1200","parameters":null,"outputs":[{ "name":"output-0","shape":[5],"datatype":"FP32","parameters":null,"data":[600095.875,579441.5625,479052.34375,336679.75,586596
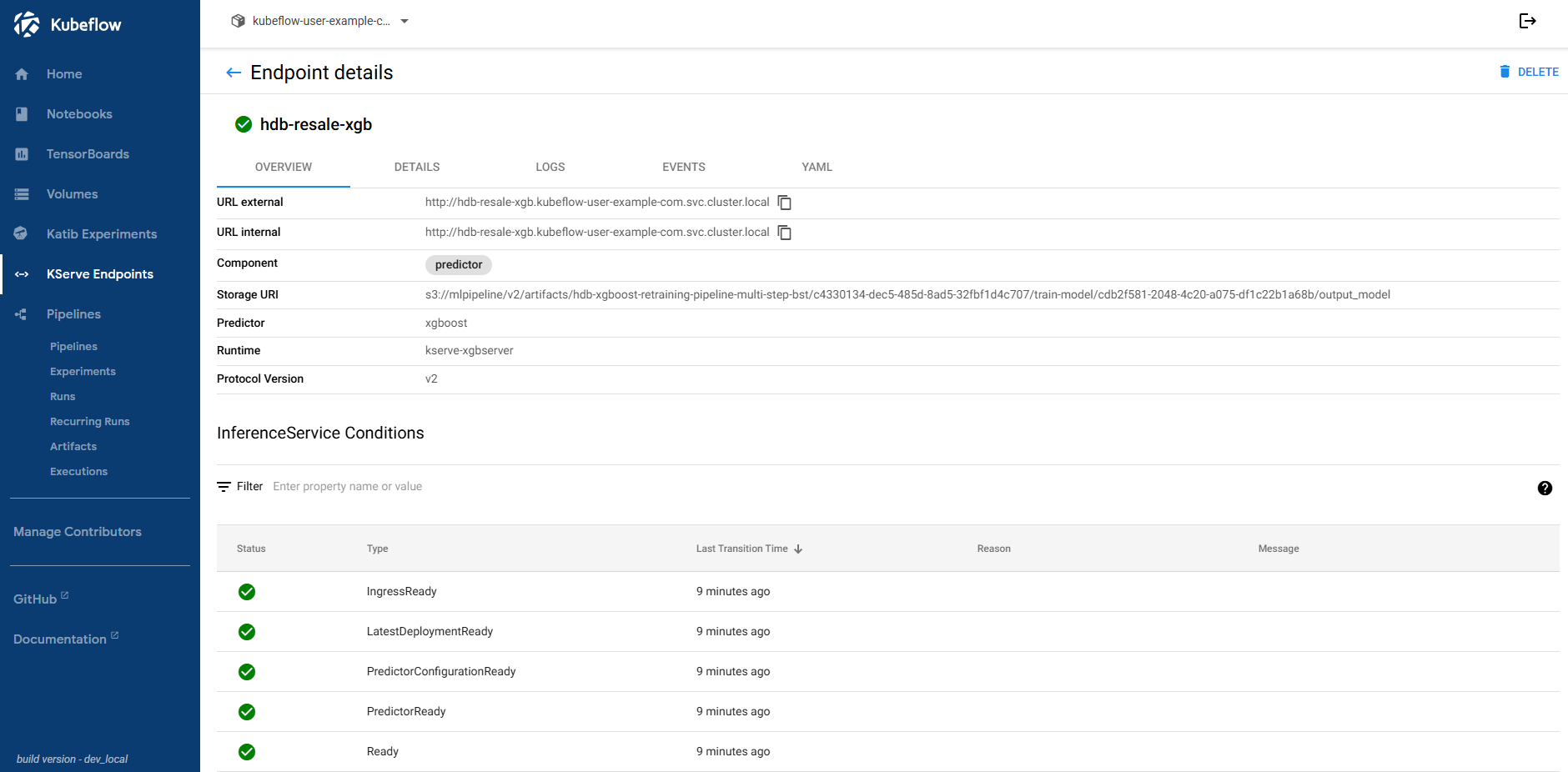
6. Download Scaler File
For accurate predictions, use the same scaler from the training process. Port-forward your MinIO service and download the scaler from the designated path after the pipeline run.
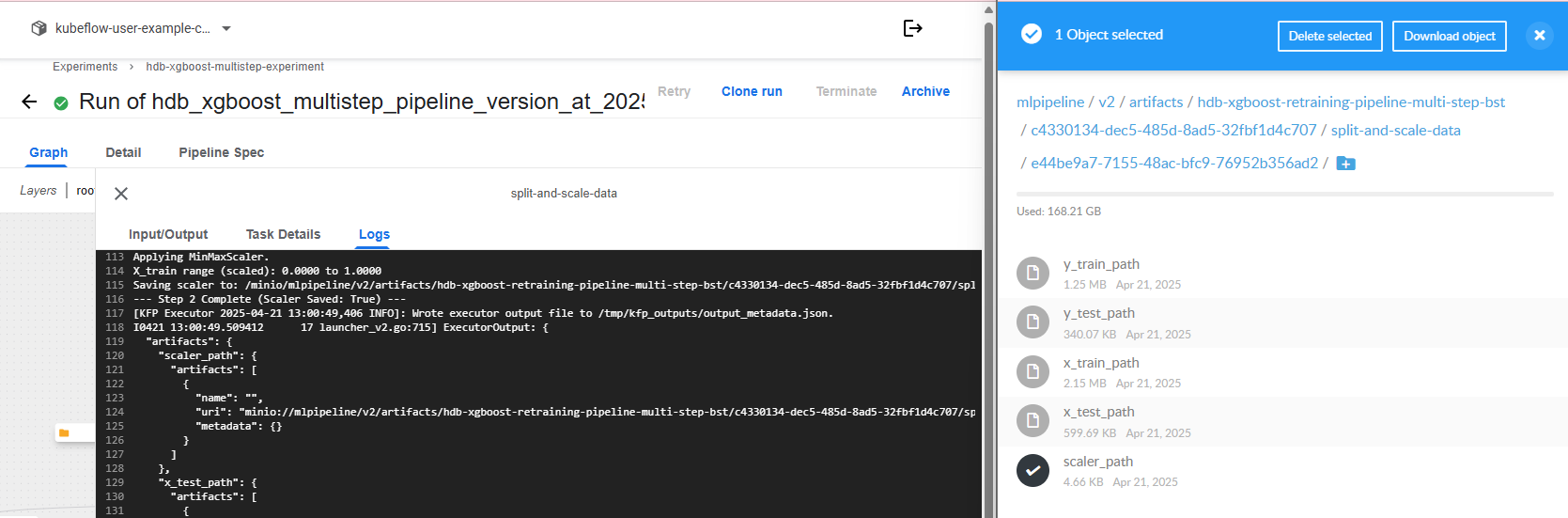
Multistep pipeline
This section outlines the custom Kubeflow pipeline built using KFP DSL. The pipeline handles everything from data ingestion to model deployment. While Kubeflow’s artifact passing is recommended, I encountered limitations and resorted to using OutputPath() and native types for smooth data transfer between steps.
Step 1 - Load & Prepare
This component loads the dataset from MinIO, parses the JSON containing selected features, and splits the data into X (features) and y (target resale price).
Component 1 - python code
import kfp
from kfp import dsl
from kfp.compiler import Compiler
from kfp.dsl import Input, Output, InputPath, OutputPath, Dataset, Metrics, Model, Artifact
import json
from typing import NamedTuple
# ==============================================================================
# Component 1: Load and Prepare Data
# ==============================================================================
@dsl.component(
base_image='python:3.10',
packages_to_install=[
'pandas==2.1.4',
'numpy==1.24.4',
's3fs==2025.3.2',
'pyarrow==19.0.1',
'kfp==2.12.1',
]
)
def load_and_prep_data(
s3_data_uri: str,
target_column: str,
features_json: str,
x_data_path: OutputPath('Dataset'),
y_data_path: OutputPath('Dataset'),
) -> NamedTuple('LoadDataOutput', [
('feature_names_json_out', str)
]):
# Define the NamedTuple
LoadDataOutput = NamedTuple('LoadDataOutput', [
('feature_names_json_out', str)
])
import pandas as pd
import numpy as np
import os
import json
import s3fs
print("--- Step 1: Load and Prep Data ---")
print(f"Input S3 URI: {s3_data_uri}")
print(f"Target Column: {target_column}")
# Load Data
minio_endpoint_url = os.environ.get('AWS_ENDPOINT_URL', 'http://minio-service.kubeflow:9000')
minio_access_key = os.environ.get('AWS_ACCESS_KEY_ID', 'minio')
minio_secret_key = os.environ.get('AWS_SECRET_ACCESS_KEY', 'minio123')
s3_storage_options = {
'key': minio_access_key,
'secret': minio_secret_key,
'client_kwargs': {
'endpoint_url': minio_endpoint_url
}
}
print("Reading parquet from S3...")
df_processed = pd.read_parquet(s3_data_uri, storage_options=s3_storage_options)
print(f"Loaded data shape: {df_processed.shape}")
# Parse Features & Split X/y
feature_names = json.loads(features_json)
print(f"Using pre-defined fixed feature set ({len(feature_names)} features).")
missing_features = [f for f in feature_names if f not in df_processed.columns]
if missing_features:
raise ValueError(f"Fixed features not found in dataset: {missing_features}")
X_data = df_processed[feature_names]
y_data = df_processed[[target_column]]
print(f"X_data shape: {X_data.shape}")
print(f"y_data shape: {y_data.shape}")
# Save Outputs
X_data.to_parquet(x_data_path)
y_data.to_parquet(y_data_path)
print("--- Step 1 Complete ---")
return LoadDataOutput(feature_names_json_out=features_json)
Step 2 - Split & Scale
Performs train/test splitting and applies scaling. The fitted scaler is saved for later use in inference.
Component 2 - python code
# ==============================================================================
# Component 2: Split and Scale Data
# ==============================================================================
@dsl.component(
base_image='python:3.10',
packages_to_install=[
'pandas==2.1.4',
'numpy==1.24.4',
'scikit-learn==1.6.1',
'joblib==1.4.2',
'pyarrow==19.0.1',
'kfp==2.12.1',
]
)
def split_and_scale_data(
x_data_path: InputPath('Dataset'),
y_data_path: InputPath('Dataset'),
feature_names_json: str,
use_scaling: bool,
# Outputs
x_train_path: OutputPath('Dataset'),
x_test_path: OutputPath('Dataset'),
y_train_path: OutputPath('Dataset'),
y_test_path: OutputPath('Dataset'),
scaler_path: OutputPath('Artifact')
):
import pandas as pd
import numpy as np
import joblib
import json
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import os
print("--- Step 2: Split and Scale Data ---")
print(f"Use Scaling: {use_scaling}")
# Load Inputs
X_data = pd.read_parquet(x_data_path)
y_data = pd.read_parquet(y_data_path)
y_data = y_data.iloc[:, 0]
print(f"Loaded X shape: {X_data.shape}, y shape: {y_data.shape}")
feature_names = json.loads(feature_names_json)
print(f"Loaded feature names list ({len(feature_names)} features).")
# Split
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=42)
print(f"X_train: {X_train.shape}, X_test: {X_test.shape}, y_train: {y_train.shape}, y_test: {y_test.shape}")
# Scale
X_scaler = None
scaler_saved = False
if use_scaling:
print("Applying MinMaxScaler.")
X_scaler = MinMaxScaler()
# Fit on Training, Transform Train and Test
X_train_scaled_np = X_scaler.fit_transform(X_train)
X_test_scaled_np = X_scaler.transform(X_test)
# Convert back to DataFrame with original index and columns
X_train = pd.DataFrame(X_train_scaled_np, columns=feature_names, index=X_train.index)
X_test = pd.DataFrame(X_test_scaled_np, columns=feature_names, index=X_test.index)
print(f"X_train range (scaled): {X_train.values.min():.4f} to {X_train.values.max():.4f}")
# Save the scaler
print(f"Saving scaler to: {scaler_path}")
joblib.dump(X_scaler, scaler_path)
scaler_saved = True
else:
print("Using Original Features (No Scaling).")
print(f"No scaler used, creating empty placeholder artifact at: {scaler_path}")
with open(scaler_path, 'w') as f:
f.write('')
# Save Outputs
X_train.to_parquet(x_train_path)
X_test.to_parquet(x_test_path)
pd.DataFrame(y_train).to_parquet(y_train_path)
pd.DataFrame(y_test).to_parquet(y_test_path)
print(f"--- Step 2 Complete (Scaler Saved: {scaler_saved}) ---")
Step 3 - Train Model
An XGBoost model is trained using the core API, with the run tracked via MLflow. The model is saved in .bst format as required by KServe.
Component 3 - python code
# ==============================================================================
# Component 3: Train Model
# ==============================================================================
@dsl.component(
base_image='python:3.10',
packages_to_install=[
'pandas==2.1.4',
'numpy==1.24.4',
'xgboost==2.1.1',
'mlflow==2.21.3',
'pyarrow==19.0.1',
'joblib==1.4.2',
'kfp==2.12.1',
'scikit-learn==1.6.1'
]
)
def train_model(
# Data inputs
x_train_path: InputPath('Dataset'),
x_test_path: InputPath('Dataset'),
y_train_path: InputPath('Dataset'),
y_test_path: InputPath('Dataset'),
scaler_path: InputPath('Artifact'),
use_scaling: bool,
feature_names_json: str,
# Hyperparameters
n_estimators: int,
learning_rate: float,
max_depth: int,
early_stopping_rounds: int,
colsample_bytree: float,
min_child_weight: int,
subsample: float,
random_state: int,
# MLflow info
run_name: str,
mlflow_tracking_uri: str,
mlflow_experiment_name: str,
# Outputs
output_model: Output[Model],
) -> NamedTuple('TrainOutput', [
('mlflow_run_id_out', str)
]):
# Define NamedTuple
TrainOutput = NamedTuple('TrainOutput', [('mlflow_run_id_out', str)])
import pandas as pd
import numpy as np
import xgboost as xgb
import mlflow
import mlflow.xgboost
import os
import joblib
import json
from pathlib import Path
import warnings
# Ignore the UBJSON format warning during saving
warnings.filterwarnings('ignore', category=UserWarning, module='xgboost.core')
print("--- Step 3: Train Model ---")
print(f"MLflow Tracking URI: {mlflow_tracking_uri}")
print(f"MLflow Experiment Name: {mlflow_experiment_name}")
print(f"Using XGBoost version: {xgb.__version__}")
print(f"Hyperparameters: n_est={n_estimators}, lr={learning_rate}, depth={max_depth}, early_stop={early_stopping_rounds}, colsample={colsample_bytree}, min_child={min_child_weight}, subsample={subsample}")
# Load Data
print("Loading training/testing data")
X_train_df = pd.read_parquet(x_train_path)
X_test_df = pd.read_parquet(x_test_path)
y_train_df = pd.read_parquet(y_train_path)
y_test_df = pd.read_parquet(y_test_path)
# Ensure y is a 1D array
y_train = y_train_df.iloc[:, 0].values
y_test = y_test_df.iloc[:, 0].values
# Get feature names and enforce order in DataFrame
feature_names = json.loads(feature_names_json)
print(f"Loaded feature names list ({len(feature_names)} features).")
# Ensure feature order matches the expected order
X_train = X_train_df[feature_names]
X_test = X_test_df[feature_names]
print(f"Verified feature order in datasets. X_train: {X_train.shape}, X_test: {X_test.shape}")
# Convert to NumPy FOR TRAINING - crucial step
print("Converting data to NumPy arrays for DMatrix creation...")
X_train_np = X_train_df.values
X_test_np = X_test_df.values
# MLflow Setup and Start Run
mlflow.set_tracking_uri(mlflow_tracking_uri)
mlflow.set_experiment(mlflow_experiment_name)
# Configure MLflow autologging - DISABLE model logging
mlflow.xgboost.autolog(
log_input_examples=False,
log_model_signatures=False,
log_models=False,
log_datasets=False,
disable=False,
registered_model_name=None
)
# Start MLflow Run
kfp_run_id = os.environ.get('KFP_RUN_ID', 'local')
final_run_name = f"{run_name}_{kfp_run_id}"
print(f"Starting MLflow run with name: {final_run_name}")
with mlflow.start_run(run_name=final_run_name) as run:
current_run_id = run.info.run_id
print(f"Started MLflow Run ID: {current_run_id}")
# Log parameters
mlflow.log_params({
"feature_set_name": final_run_name,
"num_features": len(feature_names),
"use_scaling": use_scaling,
"n_estimators": n_estimators,
"learning_rate": learning_rate,
"max_depth": max_depth,
"early_stopping_rounds": early_stopping_rounds,
"colsample_bytree": colsample_bytree,
"min_child_weight": min_child_weight,
"subsample": subsample,
"random_state": random_state,
"model_type": "XGBoost",
"training_api": "xgb.train",
"framework": f"xgboost=={xgb.__version__}"
})
# Log feature names as artifact
try:
temp_feat_path = "feature_names.json"
with open(temp_feat_path, "w") as f:
json.dump(feature_names, f)
mlflow.log_artifact(temp_feat_path, artifact_path="features")
print("Feature names list logged as artifact.")
except Exception as e:
print(f"Warning: Could not log feature names artifact: {e}")
# Log scaler artifact if used
if use_scaling and os.path.exists(scaler_path) and os.path.getsize(scaler_path) > 0:
try:
mlflow.log_artifact(scaler_path, artifact_path="scaler")
print("Scaler logged as artifact to MLflow.")
except Exception as e:
print(f"Warning: Could not log scaler artifact: {e}")
# Model Training using Core API
print("Creating DMatrix WITHOUT feature names...")
dtrain = xgb.DMatrix(X_train_np, label=y_train)
dtest = xgb.DMatrix(X_test_np, label=y_test)
print("DMatrix created.")
print("Training XGBoost model using xgb.train...")
params = {
'objective': 'reg:squarederror',
'learning_rate': learning_rate,
'max_depth': max_depth,
'subsample': subsample,
'colsample_bytree': colsample_bytree,
'min_child_weight': min_child_weight,
'random_state': random_state,
'eval_metric': 'rmse',
}
evals = [(dtrain, 'train'), (dtest, 'eval')]
# Train the model - returns the booster object
bst_model = xgb.train(
params,
dtrain,
num_boost_round=n_estimators,
evals=evals,
early_stopping_rounds=early_stopping_rounds,
verbose_eval=False
)
print(f"Training complete. Best iteration: {bst_model.best_iteration}, Best score (RMSE): {bst_model.best_score}")
# Save Model Manually (Binary Format)
try:
model_dir = Path(output_model.path)
model_dir.mkdir(parents=True, exist_ok=True)
model_file_path = model_dir / "model.bst"
print(f"Saving model in binary format to: {model_file_path}")
bst_model.save_model(model_file_path)
# Verify the model was saved
if not model_file_path.exists() or model_file_path.stat().st_size == 0:
raise RuntimeError(f"Failed to save model or model file is empty at {model_file_path}")
print(f"Model successfully saved locally to {model_file_path}")
# Log Model Manually to MLflow
print("Logging model artifact to MLflow...")
mlflow.log_artifact(model_file_path, artifact_path="model")
if 'temp_feat_path' in locals() and Path(temp_feat_path).exists():
mlflow.log_artifact(temp_feat_path, artifact_path="model")
os.remove(temp_feat_path)
print("Model artifacts logged to MLflow run.")
# Set KFP output model metadata
output_model.metadata.update({
"framework": "xgboost",
"format": "bst",
"feature_order": json.dumps(feature_names),
"feature_count": str(len(feature_names)),
"best_iteration": str(bst_model.best_iteration),
"best_score": str(bst_model.best_score),
"training_samples": str(len(X_train_np)),
"validation_samples": str(len(X_test_np)),
"mlflow_run_id": current_run_id
})
except Exception as e:
print(f"Error saving/logging model artifacts: {str(e)}")
raise
print(f"--- Step 3 Complete (MLflow Run ID: {current_run_id}) ---")
return TrainOutput(mlflow_run_id_out=current_run_id)
Step 4 - Predict & Evaluate
The trained model is used to predict on test data, and performance metrics are logged to MLflow.
Component 4 - python code
# ==============================================================================
# Component 4: Predict and Evaluate
# ==============================================================================
@dsl.component(
base_image='python:3.10',
packages_to_install=[
'pandas==2.1.4',
'numpy==1.24.4',
'xgboost==2.1.1',
'scikit-learn==1.6.1',
'mlflow==2.21.3',
'pyarrow==19.0.1',
'joblib==1.4.2',
'kfp==2.12.1',
]
)
def predict_and_evaluate(
input_model: Input[Model],
x_test_path: InputPath('Dataset'),
y_test_path: InputPath('Dataset'),
mlflow_run_id: str,
mlflow_tracking_uri: str,
feature_names_json: str,
# Outputs
y_pred_path: OutputPath('Dataset'),
test_rmse_output: OutputPath(float),
test_mae_output: OutputPath(float),
test_r2_output: OutputPath(float),
):
import pandas as pd
import numpy as np
import xgboost as xgb
import mlflow
import joblib
import os
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import json
from pathlib import Path
print("--- Step 4: Predict and Evaluate ---")
print(f"Using XGBoost version: {xgb.__version__}")
# Load Inputs
print("Loading model...")
model_dir = Path(input_model.path)
# Look for model.bst
model_file_bst = model_dir / "model.bst"
if not model_file_bst.exists():
raise FileNotFoundError(f"Model file 'model.bst' not found at {model_dir}")
print(f"Loading XGBoost model from {model_file_bst}")
# Load model using Booster interface
booster = xgb.Booster()
booster.load_model(model_file_bst)
print("Model loaded successfully.")
print("Loading test data...")
X_test_df = pd.read_parquet(x_test_path)
y_test_df = pd.read_parquet(y_test_path)
y_test = y_test_df.iloc[:, 0].values
# Load feature names to ensure correct column order in X_test_df
feature_names = json.loads(feature_names_json)
print(f"Ensuring test data feature order using: {feature_names}")
try:
X_test_df = X_test_df[feature_names]
except KeyError as e:
print(f"Error: Feature mismatch when ordering X_test columns: {e}")
missing = set(feature_names) - set(X_test_df.columns)
if missing:
print(f"Features expected but missing in X_test data: {missing}")
raise
# Configure MLflow Client
mlflow.set_tracking_uri(mlflow_tracking_uri)
print(f"Using MLflow Run ID: {mlflow_run_id}")
print("Attempting to log metrics to existing MLflow run...")
with mlflow.start_run(run_id=mlflow_run_id):
# Prediction
print("Generating predictions...")
print(f"Creating DMatrix from X_test data with shape: {X_test_df.shape}")
dtest = xgb.DMatrix(X_test_df)
y_pred = booster.predict(dtest)
y_pred = np.array(y_pred).ravel() # Ensure y_pred is a flat NumPy array
print(f"Predictions generated with shape: {y_pred.shape}")
# Evaluation
print("Calculating evaluation metrics...")
# Handle potential NaN/inf
valid_indices = ~np.isnan(y_test) & ~np.isinf(y_test) & ~np.isnan(y_pred) & ~np.isinf(y_pred)
if not np.all(valid_indices):
print(f"Warning: NaN or Inf detected... ")
y_test_valid = y_test[valid_indices]
y_pred_valid = y_pred[valid_indices]
else:
y_test_valid = y_test
y_pred_valid = y_pred
# Check if any valid data remains after filtering
if len(y_test_valid) == 0:
print("Error: No valid data points remain after filtering NaN/Inf. Cannot calculate metrics.")
rmse, mae, r2 = np.nan, np.nan, np.nan
else:
mse = mean_squared_error(y_test_valid, y_pred_valid)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test_valid, y_pred_valid)
r2 = r2_score(y_test_valid, y_pred_valid)
# Get best iteration from metadata if available
best_iteration = int(input_model.metadata.get('best_iteration', -1))
# Log Metrics to MLflow
print("Logging metrics to MLflow...")
mlflow.log_metrics({
"eval_mse": mse if not np.isnan(mse) else 0,
"eval_rmse": rmse if not np.isnan(rmse) else 0,
"eval_mae": mae if not np.isnan(mae) else 0,
"eval_r2": r2 if not np.isnan(r2) else 0,
# Log best_iteration if valid
**({"best_iteration_eval": best_iteration} if best_iteration != -1 else {})
})
print("\n--- Evaluation Results ---")
print(f"Test Set MSE: {mse:,.4f}")
print(f"Test Set RMSE: {rmse:,.4f}")
print(f"Test Set MAE: {mae:,.4f}")
print(f"Test Set R²: {r2:.4f}")
if best_iteration != -1:
print(f"Best Iteration (from training): {best_iteration}")
# Save predictions as DataFrame/Parquet
print(f"Saving predictions DataFrame ({len(y_pred)} rows) to: {y_pred_path}")
pred_df = pd.DataFrame({'predictions': y_pred}, index=X_test_df.index)
pred_df.to_parquet(y_pred_path)
# Save metrics to KFP output paths
with open(test_rmse_output, 'w') as f: f.write(str(rmse if not np.isnan(rmse) else 0.0))
with open(test_mae_output, 'w') as f: f.write(str(mae if not np.isnan(mae) else 0.0))
with open(test_r2_output, 'w') as f: f.write(str(r2 if not np.isnan(r2) else 0.0))
print("--- Step 4 Complete ---")
Step 5 - Generate & Log Plot
This component visualizes key performance metrics and logs the resulting plots to the MLflow run.
Component 5 - python code
# ==============================================================================
# Component 5: Generate and Log Plots
# ==============================================================================
@dsl.component(
base_image='python:3.10',
packages_to_install=[
'pandas==2.1.4',
'numpy==1.24.4',
'xgboost==2.1.1',
'matplotlib==3.10.0',
'mlflow==2.21.3',
'joblib==1.4.2',
'pyarrow==19.0.1',
'kfp==2.12.1',
]
)
def generate_and_log_plots(
input_model: Input[Model],
y_test_path: InputPath('Dataset'),
y_pred_path: InputPath('Dataset'),
feature_names_json: str,
mlflow_run_id: str,
mlflow_tracking_uri: str,
run_name: str,
):
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost import plot_importance
import matplotlib.pyplot as plt
import mlflow
import os
import json
import traceback
from pathlib import Path
print("--- Step 5: Generate and Log Plots ---")
print(f"Using XGBoost version: {xgb.__version__}")
# Load Inputs
print("Loading model...")
model_dir = Path(input_model.path)
# Check for model file
model_file_bst = model_dir / "model.bst"
if not model_file_bst.exists():
raise FileNotFoundError(f"Model file 'model.bst' not found at {model_dir}")
print(f"Loading XGBoost model from {model_file_bst}")
booster = xgb.Booster()
booster.load_model(model_file_bst)
print("Model loaded successfully.")
print("Loading y_test data...")
y_test = pd.read_parquet(y_test_path).iloc[:, 0].values # Load as numpy array
print("Loading feature names...")
feature_names = json.loads(feature_names_json)
print(f"Loaded {len(feature_names)} feature names.")
if feature_names:
print("Setting feature names on loaded booster for plotting...")
booster.feature_names = feature_names
else:
print("Warning: Empty feature names list received. Importance plots might use default 'fN' names.")
print(f"Using MLflow Run ID: {mlflow_run_id}")
# Load predictions
print(f"Loading predictions from: {y_pred_path}")
try:
y_pred_df = pd.read_parquet(y_pred_path)
y_pred = y_pred_df.iloc[:, 0].values # Load as numpy array
print(f"Loaded predictions, shape: {y_pred.shape}")
except Exception as e:
print(f"Error loading predictions: {e}")
raise
# Configure MLflow Client
mlflow.set_tracking_uri(mlflow_tracking_uri)
# Log plots to the existing MLflow run
with mlflow.start_run(run_id=mlflow_run_id):
# Helper Functions
def get_dynamic_figsize(feature_count, max_features=20):
display_count = min(feature_count, max_features)
height = max(6, display_count * 0.4 + 1)
width = 10
return (width, height)
# Generate and Log Plots
kfp_run_id = os.environ.get('KFP_RUN_ID', 'local')
final_run_name = f"{run_name}_{kfp_run_id}"
print("Generating and logging plots to MLflow...")
# Actual vs Predicted Plot
try:
fig_pred, ax_pred = plt.subplots(figsize=(10, 6))
valid_indices = ~np.isnan(y_test_np) & ~np.isinf(y_test_np) & ~np.isnan(y_pred) & ~np.isinf(y_pred)
y_test_plt = y_test_np[valid_indices]
y_pred_plt = y_pred[valid_indices]
ax_pred.scatter(y_test_plt, y_pred_plt, alpha=0.5, label="Predictions")
min_val = min(y_test_plt.min(), y_pred_plt.min()) * 0.98
max_val = max(y_test_plt.max(), y_pred_plt.max()) * 1.02
ax_pred.plot([min_val, max_val], [min_val, max_val], '--', color='red', linewidth=2, label="Ideal Fit")
ax_pred.set_xlabel('Actual Target')
ax_pred.set_ylabel('Predicted Target')
ax_pred.set_title(f'Actual vs. Predicted ({final_run_name})')
ax_pred.legend()
ax_pred.grid(True)
plt.tight_layout()
mlflow.log_figure(fig_pred, "plots/actual_vs_predicted.png")
plt.close(fig_pred)
print("Logged actual_vs_predicted.png")
except Exception as e:
print(f"Warning: Could not plot Actual vs Predicted: {e}\n{traceback.format_exc()}")
# Feature Importance Plots
try:
num_features = len(booster.feature_names) if booster.feature_names else 0
if num_features == 0:
print("Skipping importance plots: No feature names set on booster.")
else:
max_plot_features = 20
# Weight
fig_imp_w, ax_imp_w = plt.subplots(figsize=get_dynamic_figsize(num_features, max_plot_features))
plot_importance(booster, ax=ax_imp_w, max_num_features=max_plot_features, importance_type='weight', show_values=False, title=f'Importance (Weight) - {final_run_name}')
plt.tight_layout()
mlflow.log_figure(fig_imp_w, "plots/feature_importance_weight.png")
plt.close(fig_imp_w)
print("Logged feature_importance_weight.png")
# Gain
fig_imp_g, ax_imp_g = plt.subplots(figsize=get_dynamic_figsize(num_features, max_plot_features))
plot_importance(booster, ax=ax_imp_g, max_num_features=max_plot_features, importance_type='gain', show_values=False, title=f'Importance (Gain) - {final_run_name}')
plt.tight_layout()
mlflow.log_figure(fig_imp_g, "plots/feature_importance_gain.png")
plt.close(fig_imp_g)
print("Logged feature_importance_gain.png")
# Cover
fig_imp_c, ax_imp_c = plt.subplots(figsize=get_dynamic_figsize(num_features, max_plot_features))
plot_importance(booster, ax=ax_imp_c, max_num_features=max_plot_features, importance_type='cover', show_values=False, title=f'Importance (Cover) - {final_run_name}')
plt.tight_layout()
mlflow.log_figure(fig_imp_c, "plots/feature_importance_cover.png")
plt.close(fig_imp_c)
print("Logged feature_importance_cover.png")
except Exception as e:
if isinstance(e, xgb.core.XGBoostError) and 'feature_names' in str(e):
print(f"Error plotting importance (likely missing feature names internally): {e}")
else:
print(f"Warning: Could not plot importance plots: {e}\n{traceback.format_exc()}")
print("--- Step 5 Complete ---")
Step 6 - Deploy to KServe
Deploys the final model using KServe with configuration compatible with XGBoost serving. Uses the same storage path and service account setup detailed earlier.
Component 6 - python code
# ==============================================================================
# Component 6: Deploy to KServe
# ==============================================================================
@dsl.component(
base_image='python:3.10',
packages_to_install=[
'kfp==2.12.1',
'kubernetes==29.0.0',
'PyYAML==6.0.1'
]
)
def deploy_to_kserve(
# Inputs
model_name: str,
model_uri: Input[Model],
serving_namespace: str,
# Outputs
endpoint_url_output: OutputPath(str),
# Optional Args
model_format: str = 'xgboost',
kserve_api_group: str = 'serving.kserve.io',
kserve_api_version: str = 'v1beta1',
service_account_name: str = None,
min_replicas: int = 0,
max_replicas: int = 1,
cpu_request: str = "100m",
cpu_limit: str = "1",
memory_request: str = "256Mi",
memory_limit: str = "2Gi",
):
from kubernetes import client, config
from kubernetes.client.rest import ApiException
import time
import yaml
import os
import json
from urllib.parse import urlparse, urlunparse
print(f"--- Step 6: Deploy Model to KServe ---")
print(f"InferenceService Name: {model_name}")
print(f"Deployment Namespace: {serving_namespace}")
print(f"Input Model Artifact URI (directory): {model_uri.uri}")
print(f"Input Model metadata: {json.dumps(model_uri.metadata, indent=2)}")
expected_metadata_format = "bst"
actual_metadata_format = model_uri.metadata.get('format')
if not actual_metadata_format:
print(f"Warning: Model metadata does not contain 'format' key.")
elif actual_metadata_format != expected_metadata_format:
print(f"Warning: Model metadata format ('{actual_metadata_format}') does not match expected format ('{expected_metadata_format}').")
else:
print(f"Model format verified from metadata: '{actual_metadata_format}'")
# Adjust storageUri scheme AND append filename
storage_uri = model_uri.uri
# Ensure the scheme is s3:// for MinIO/S3 compatibility
parsed_uri = urlparse(storage_uri)
if parsed_uri.scheme == 'minio':
storage_uri = urlunparse(parsed_uri._replace(scheme='s3'))
print(f"Converted storage URI scheme to s3://: {storage_uri}")
elif parsed_uri.scheme != 's3':
print(f"Warning: Unexpected storage URI scheme '{parsed_uri.scheme}'. KServe might require 's3://'.")
print(f"Using final storageUri (directory): {storage_uri}")
# Construct InferenceService Object
isvc_manifest = {
"apiVersion": f"{kserve_api_group}/{kserve_api_version}",
"kind": "InferenceService",
"metadata": {
"name": model_name,
"namespace": serving_namespace,
"annotations": {
"autoscaling.knative.dev/minScale": str(min_replicas),
"autoscaling.knative.dev/maxScale": str(max_replicas)
}
},
"spec": {
"predictor": {
"model": {
"modelFormat": {
"name": model_format
},
"runtime": "kserve-xgbserver", # Use the standard XGBoost runtime
"protocolVersion": "v2",
"storageUri": storage_uri,
"resources": {
"requests": {
"cpu": cpu_request,
"memory": memory_request
},
"limits": {
"cpu": cpu_limit,
"memory": memory_limit
}
}
}
}
}
}
# Add service account if specified
if service_account_name:
isvc_manifest["spec"]["predictor"]["serviceAccountName"] = service_account_name
print("\nConstructed InferenceService Manifest:")
print(yaml.dump(isvc_manifest, indent=2))
# Authenticate Kubernetes Client
try:
config.load_incluster_config()
print("Loaded in-cluster Kubernetes config.")
except config.ConfigException:
try:
config.load_kube_config()
print("Loaded local Kubernetes config.")
except config.ConfigException as e:
print(f"Error: Could not load any Kubernetes config: {e}")
raise
api_client = client.ApiClient()
custom_api = client.CustomObjectsApi(api_client)
# Create or Update InferenceService
try:
print(f"Checking if InferenceService '{model_name}' exists in namespace '{serving_namespace}'...")
existing_isvc = custom_api.get_namespaced_custom_object(
group=kserve_api_group,
version=kserve_api_version,
namespace=serving_namespace,
plural="inferenceservices",
name=model_name
)
print("InferenceService exists. Patching...")
# Update only the relevant parts if needed, or replace the whole spec
# For simplicity, patching the whole body ensures config drift is fixed
resp = custom_api.patch_namespaced_custom_object(
group=kserve_api_group,
version=kserve_api_version,
namespace=serving_namespace,
plural="inferenceservices",
name=model_name,
body=isvc_manifest # Apply the desired state
)
print("Patch successful.")
except ApiException as e:
if e.status == 404:
print("Creating new InferenceService...")
resp = custom_api.create_namespaced_custom_object(
group=kserve_api_group,
version=kserve_api_version,
namespace=serving_namespace,
plural="inferenceservices",
body=isvc_manifest
)
print("Create successful.")
else:
# Log the error details properly
print(f"Error interacting with Kubernetes API: Status={e.status}, Reason={e.reason}")
print(f"Body: {e.body}")
raise
# Wait for InferenceService to be Ready
print("Waiting for InferenceService to become Ready...")
timeout_seconds = 300
start_time = time.time()
isvc_url = None
last_message = ""
while time.time() - start_time < timeout_seconds:
try:
isvc = custom_api.get_namespaced_custom_object(
group=kserve_api_group,
version=kserve_api_version,
namespace=serving_namespace,
plural="inferenceservices",
name=model_name
)
status = isvc.get("status", {})
url = status.get("url")
conditions = status.get("conditions", [])
ready_condition = next(
(c for c in conditions if c.get("type") == "Ready"),
None
)
current_message = "No Ready condition found"
if ready_condition:
current_message = f"Ready={ready_condition.get('status')}, Reason={ready_condition.get('reason', 'N/A')}, Msg={ready_condition.get('message', 'N/A')}"
if ready_condition.get("status") == "True":
if url:
isvc_url = url
print(f"\nInferenceService is Ready at: {isvc_url}")
break
else:
current_message += " (URL not available yet)"
# Only print status if it changes
if current_message != last_message:
print(f"Current status: {current_message}")
last_message = current_message
except ApiException as e:
error_message = f"Status check error: {e.status} - {e.reason}"
if error_message != last_message:
print(error_message)
last_message = error_message
except Exception as e:
# Catch other potential errors during status check
error_message = f"Unexpected error during status check: {str(e)}"
if error_message != last_message:
print(error_message)
last_message = error_message
time.sleep(15) # Increase sleep interval slightly
if not isvc_url:
print(f"Warning: Timeout after {timeout_seconds} seconds waiting for InferenceService '{model_name}' to become ready.")
# Try to get last known status for debugging
try:
isvc = custom_api.get_namespaced_custom_object(group=kserve_api_group, version=kserve_api_version, namespace=serving_namespace, plural="inferenceservices", name=model_name)
print(f"Final status check: {json.dumps(isvc.get('status'), indent=2)}")
except Exception as final_e:
print(f"Could not get final status: {final_e}")
isvc_url = "ERROR: Deployment timeout or failure"
# Save Endpoint URL Output
with open(endpoint_url_output, 'w') as f:
f.write(isvc_url)
print("--- Step 6 Complete ---")
Step 7 - Pipeline Definition
Defines task ordering and parameter passing. Note: I noticed set_display_name() sometimes causes unexpected errors and have commented it out.
# load_task.set_display_name("Load & Prep Data")
Component 7 - python code
# ==============================================================================
# Pipeline Definition
# ==============================================================================
@dsl.pipeline(
name='HDB XGBoost Retraining Pipeline (Multi-Step BST)',
description='Retrains XGBoost model (BST format) and deploys to KServe.'
)
def hdb_xgboost_multistep_pipeline(
# Pipeline Parameters
fixed_processed_data_s3_uri: str = 's3://mlpipeline/hdb-resale-data/resale-data-etl-final.parquet',
target_column: str = 'resale_price',
mlflow_tracking_uri: str = 'http://mlflow-tracking.mlflow',
mlflow_experiment_name: str = 'XGBoostMultistepBST',
# Features/HPs
best_features_json: str = '[]',
best_use_scaling: bool = True,
best_n_estimators: int = 500,
best_learning_rate: float = 0.04,
best_max_depth: int = 7,
best_early_stopping_rounds: int = 15,
best_colsample_bytree: float = 0.7,
best_min_child_weight: int = 3,
best_subsample: float = 0.8,
best_random_state: int = 42,
base_run_name: str = "XGBoostMultiStepBST",
# KServe Deployment Params
kserve_model_name: str = 'hdb-resale-xgb',
kserve_namespace: str = 'kubeflow-user-example-com',
kserve_model_format: str = 'xgboost',
kserve_predictor_service_account: str = 'sa'
):
# Define Helper Function for Adding Env Vars
def add_env_vars(task):
task.set_env_variable(name="MLFLOW_TRACKING_USERNAME", value="user")
task.set_env_variable(name="MLFLOW_TRACKING_PASSWORD", value="qYlTnUDQMe")
# Pipeline Steps
# Step 1: Load Data
load_task = load_and_prep_data(
s3_data_uri=fixed_processed_data_s3_uri,
target_column=target_column,
features_json=best_features_json
)
load_task.set_caching_options(enable_caching=False)
# Step 2: Split & Scale
scale_task = split_and_scale_data(
x_data_path=load_task.outputs['x_data_path'],
y_data_path=load_task.outputs['y_data_path'],
feature_names_json=load_task.outputs['feature_names_json_out'],
use_scaling=best_use_scaling
)
scale_task.set_caching_options(enable_caching=False)
# Step 3: Train Model
train_task = train_model(
x_train_path=scale_task.outputs['x_train_path'],
x_test_path=scale_task.outputs['x_test_path'],
y_train_path=scale_task.outputs['y_train_path'],
y_test_path=scale_task.outputs['y_test_path'],
scaler_path=scale_task.outputs['scaler_path'],
use_scaling=best_use_scaling,
feature_names_json=load_task.outputs['feature_names_json_out'],
# HPs
n_estimators=best_n_estimators,
learning_rate=best_learning_rate,
max_depth=best_max_depth,
early_stopping_rounds=best_early_stopping_rounds,
colsample_bytree=best_colsample_bytree,
min_child_weight=best_min_child_weight,
subsample=best_subsample,
random_state=best_random_state,
# MLflow
run_name=base_run_name,
mlflow_tracking_uri=mlflow_tracking_uri,
mlflow_experiment_name=mlflow_experiment_name
)
train_task.set_caching_options(enable_caching=False)
add_env_vars(train_task)
# Step 4: Predict & Evaluate
eval_task = predict_and_evaluate(
input_model=train_task.outputs['output_model'],
x_test_path=scale_task.outputs['x_test_path'],
y_test_path=scale_task.outputs['y_test_path'],
mlflow_run_id=train_task.outputs['mlflow_run_id_out'],
mlflow_tracking_uri=mlflow_tracking_uri,
feature_names_json=load_task.outputs['feature_names_json_out']
)
eval_task.set_caching_options(enable_caching=False)
add_env_vars(eval_task)
# Step 5: Generate & Log Plots
plot_task = generate_and_log_plots(
input_model=train_task.outputs['output_model'],
y_test_path=scale_task.outputs['y_test_path'],
y_pred_path=eval_task.outputs['y_pred_path'],
feature_names_json=load_task.outputs['feature_names_json_out'],
mlflow_run_id=train_task.outputs['mlflow_run_id_out'],
mlflow_tracking_uri=mlflow_tracking_uri,
run_name=base_run_name
)
plot_task.set_caching_options(enable_caching=False)
add_env_vars(plot_task)
# Step 6: Deploy Model
deploy_task = deploy_to_kserve(
model_name=kserve_model_name,
model_uri=train_task.outputs['output_model'],
serving_namespace=kserve_namespace,
model_format=kserve_model_format,
service_account_name=kserve_predictor_service_account
).after(train_task)
deploy_task.set_caching_options(enable_caching=False)
Step 8 - Compilation
Compiles and uploads the pipeline as a .yaml file to Kubeflow Pipelines for execution.
Component 8 - python code
# ==============================================================================
# Pipeline Compilation
# ==============================================================================
if __name__ == '__main__':
# Define best feature set found during exploration
BEST_FEATURE_SET = ['floor_area_sqm', 'remaining_lease_years', 'storey_avg', 'sale_year', 'sale_month',
'flat_type_1 ROOM', 'flat_type_2 ROOM', 'flat_type_3 ROOM', 'flat_type_4 ROOM', 'flat_type_5 ROOM',
'flat_type_EXECUTIVE', 'flat_type_MULTI-GENERATION', 'flat_model_2-room', 'flat_model_3Gen', 'flat_model_Adjoined flat',
'flat_model_Apartment', 'flat_model_DBSS', 'flat_model_Improved', 'flat_model_Improved-Maisonette', 'flat_model_Maisonette',
'flat_model_Model A', 'flat_model_Model A-Maisonette', 'flat_model_Model A2', 'flat_model_Multi Generation', 'flat_model_New Generation',
'flat_model_Premium Apartment', 'flat_model_Premium Apartment Loft', 'flat_model_Premium Maisonette', 'flat_model_Simplified', 'flat_model_Standard',
'flat_model_Terrace', 'flat_model_Type S1', 'flat_model_Type S2', 'town_ANG MO KIO', 'town_BEDOK',
'town_BISHAN', 'town_BUKIT BATOK', 'town_BUKIT MERAH', 'town_BUKIT PANJANG', 'town_BUKIT TIMAH',
'town_CENTRAL AREA', 'town_CHOA CHU KANG', 'town_CLEMENTI', 'town_GEYLANG', 'town_HOUGANG',
'town_JURONG EAST', 'town_JURONG WEST', 'town_KALLANG/WHAMPOA', 'town_MARINE PARADE', 'town_PASIR RIS',
'town_PUNGGOL', 'town_QUEENSTOWN', 'town_SEMBAWANG', 'town_SENGKANG', 'town_SERANGOON',
'town_TAMPINES', 'town_TOA PAYOH', 'town_WOODLANDS', 'town_YISHUN']
BEST_FEATURE_SET_JSON = json.dumps(BEST_FEATURE_SET)
# Define other best parameters if needed for compile-time defaults
BEST_USE_SCALING = True
BEST_N_ESTIMATORS = 500
BEST_LEARNING_RATE = 0.04
BEST_MAX_DEPTH = 7
BEST_EARLY_STOPPING_ROUNDS = 15
BEST_COLSAMPLE_BYTREE = 0.7
BEST_MIN_CHILD_WEIGHT = 3
# Set pipeline parameters for compilation
pipeline_parameters = {
'best_features_json': BEST_FEATURE_SET_JSON,
'best_use_scaling': BEST_USE_SCALING,
'best_n_estimators': BEST_N_ESTIMATORS,
'best_learning_rate': BEST_LEARNING_RATE,
'best_max_depth': BEST_MAX_DEPTH,
'best_early_stopping_rounds': BEST_EARLY_STOPPING_ROUNDS,
'best_colsample_bytree': BEST_COLSAMPLE_BYTREE,
'best_min_child_weight': BEST_MIN_CHILD_WEIGHT,
}
Compiler().compile(
pipeline_func=hdb_xgboost_multistep_pipeline,
package_path='hdb_xgboost_multistep_pipeline.yaml',
pipeline_parameters=pipeline_parameters
)
print("Pipeline compiled to hdb_xgboost_multistep_pipeline.yaml")
HDB Predictor App
Finally, a simple and intuitive Streamlit app lets users interact with the model by entering flat details (e.g., floor area, location, lease year). The app sends the inputs to the KServe endpoint and displays the predicted resale price.
streamlit run app.py
app.py - python code
# app.py
import streamlit as st
import requests
import numpy as np
import pandas as pd
import joblib
import os
import json
from datetime import datetime
# --- SET PAGE CONFIG FIRST ---
st.set_page_config(layout="centered", page_title="HDB Price Predictor")
# --- Configuration ---
KSERVE_URL = os.environ.get("KSERVE_URL", "http://hdb-resale-xgb.kubeflow-user-example-com.svc.cluster.local/v2/models/hdb-resale-xgb/infer")
SCALER_PATH = "scaler.joblib"
# Feature names in the EXACT order the model expects
FEATURE_NAMES = ['floor_area_sqm', 'remaining_lease_years', 'storey_avg', 'sale_year', 'sale_month',
'flat_type_1 ROOM', 'flat_type_2 ROOM', 'flat_type_3 ROOM', 'flat_type_4 ROOM', 'flat_type_5 ROOM',
'flat_type_EXECUTIVE', 'flat_type_MULTI-GENERATION', 'flat_model_2-room', 'flat_model_3Gen', 'flat_model_Adjoined flat',
'flat_model_Apartment', 'flat_model_DBSS', 'flat_model_Improved', 'flat_model_Improved-Maisonette', 'flat_model_Maisonette',
'flat_model_Model A', 'flat_model_Model A-Maisonette', 'flat_model_Model A2', 'flat_model_Multi Generation', 'flat_model_New Generation',
'flat_model_Premium Apartment', 'flat_model_Premium Apartment Loft', 'flat_model_Premium Maisonette', 'flat_model_Simplified', 'flat_model_Standard',
'flat_model_Terrace', 'flat_model_Type S1', 'flat_model_Type S2', 'town_ANG MO KIO', 'town_BEDOK',
'town_BISHAN', 'town_BUKIT BATOK', 'town_BUKIT MERAH', 'town_BUKIT PANJANG', 'town_BUKIT TIMAH',
'town_CENTRAL AREA', 'town_CHOA CHU KANG', 'town_CLEMENTI', 'town_GEYLANG', 'town_HOUGANG',
'town_JURONG EAST', 'town_JURONG WEST', 'town_KALLANG/WHAMPOA', 'town_MARINE PARADE', 'town_PASIR RIS',
'town_PUNGGOL', 'town_QUEENSTOWN', 'town_SEMBAWANG', 'town_SENGKANG', 'town_SERANGOON',
'town_TAMPINES', 'town_TOA PAYOH', 'town_WOODLANDS', 'town_YISHUN']
NUM_FEATURES = len(FEATURE_NAMES)
# --- Extract Categories for Dropdowns ---
def extract_categories(prefix, feature_list):
categories = []
prefix_len = len(prefix)
for feature in feature_list:
if feature.startswith(prefix):
categories.append(feature[prefix_len:])
return sorted(categories)
FLAT_TYPES = extract_categories("flat_type_", FEATURE_NAMES)
FLAT_MODELS = extract_categories("flat_model_", FEATURE_NAMES)
TOWNS = extract_categories("town_", FEATURE_NAMES)
# --- Load Scaler ---
try:
scaler = joblib.load(SCALER_PATH)
print("Scaler loaded successfully.")
except FileNotFoundError:
st.error(f"Error: Scaler file not found at {SCALER_PATH}. Cannot proceed.")
st.stop()
except Exception as e:
st.error(f"Error loading scaler: {e}")
st.stop()
# --- Streamlit UI ---
st.title("HDB Resale Price Predictor")
st.markdown("Enter the details below to get a price prediction.")
# --- Input Fields ---
col1, col2 = st.columns(2) # Arrange inputs in columns
with col1:
st.header("Key Features")
floor_area = st.number_input("Floor Area (sqm)", min_value=20.0, max_value=300.0, value=90.0, step=1.0)
lease_years = st.number_input("Remaining Lease (Years)", min_value=10.0, max_value=99.0, value=70.0, step=0.5)
storey = st.number_input("Storey (Average)", min_value=1.0, max_value=50.0, value=10.0, step=1.0)
with col2:
st.header("Location & Type")
# Set default indices based on common values or simple index 0
default_town_index = TOWNS.index("TAMPINES") if "TAMPINES" in TOWNS else 0
default_flat_type_index = FLAT_TYPES.index("4 ROOM") if "4 ROOM" in FLAT_TYPES else 0
default_flat_model_index = FLAT_MODELS.index("Improved") if "Improved" in FLAT_MODELS else 0
selected_town = st.selectbox("Town", TOWNS, index=default_town_index)
selected_flat_type = st.selectbox("Flat Type", FLAT_TYPES, index=default_flat_type_index)
selected_flat_model = st.selectbox("Flat Model", FLAT_MODELS, index=default_flat_model_index)
# --- Prediction Button ---
if st.button("Predict Resale Price", type="primary"):
st.markdown("---")
st.subheader("Processing...")
# --- Prepare Input Data ---
# Start with all features as 0.0
input_dict = {feat: 0.0 for feat in FEATURE_NAMES}
# Update with numerical user inputs
input_dict['floor_area_sqm'] = float(floor_area)
input_dict['remaining_lease_years'] = float(lease_years)
input_dict['storey_avg'] = float(storey)
# Update with default sale year/month
now = datetime.now()
input_dict['sale_year'] = float(now.year)
input_dict['sale_month'] = float(now.month)
# *** Update one-hot encoded features based on dropdown selections ***
# Town
town_feature_name = f"town_{selected_town}"
if town_feature_name in input_dict:
input_dict[town_feature_name] = 1.0
else:
st.warning(f"Selected town feature '{town_feature_name}' not found in model features. Check FEATURE_NAMES.")
# Flat Type
flat_type_feature_name = f"flat_type_{selected_flat_type}"
if flat_type_feature_name in input_dict:
input_dict[flat_type_feature_name] = 1.0
else:
st.warning(f"Selected flat type feature '{flat_type_feature_name}' not found in model features.")
# Flat Model
flat_model_feature_name = f"flat_model_{selected_flat_model}"
if flat_model_feature_name in input_dict:
input_dict[flat_model_feature_name] = 1.0
else:
st.warning(f"Selected flat model feature '{flat_model_feature_name}' not found in model features.")
# Convert dictionary to ordered list
try:
input_list = [input_dict[feature] for feature in FEATURE_NAMES]
input_array = np.array(input_list).astype(np.float32).reshape(1, -1) # Reshape for scaler
st.write(f"Input shape before scaling: {input_array.shape}")
# Optional: Display which one-hot features are set
# set_features = {k:v for k,v in input_dict.items() if v==1.0 and ('town_' in k or 'flat_type_' in k or 'flat_model_' in k)}
# st.write(f"One-hot features set: {set_features}")
# --- Scale the Input Data ---
input_scaled = scaler.transform(input_array)
st.write(f"Input shape after scaling: {input_scaled.shape}")
payload_data = input_scaled.flatten().tolist()
# --- Construct KServe Payload ---
payload = {
"inputs": [{
"name": "input-0",
"shape": [1, NUM_FEATURES],
"datatype": "FP32",
"data": payload_data
}]
}
st.write("Sending request to KServe...")
# --- Send Request ---
try:
response = requests.post(KSERVE_URL, json=payload, timeout=30)
response.raise_for_status()
result = response.json()
st.write("Response received:")
prediction = result.get('outputs', [{}])[0].get('data', [None])[0]
if prediction is not None:
st.success(f"**Predicted Resale Price:** S$ {prediction:,.2f}")
else:
st.error("Prediction data not found in the response.")
st.json(result)
# ... (Error handling remains the same) ...
except requests.exceptions.Timeout:
st.error(f"Error: Request timed out connecting to {KSERVE_URL}")
except requests.exceptions.ConnectionError:
st.error(f"Error: Could not connect to the prediction service at {KSERVE_URL}. Is it running and accessible?")
except requests.exceptions.HTTPError as err:
st.error(f"Error: Prediction service returned status code {err.response.status_code}.")
try:
error_detail = err.response.json()
st.json({"error_details": error_detail})
except json.JSONDecodeError:
st.text(f"Response content:\n{err.response.text}")
except Exception as e:
st.error(f"An unexpected error occurred: {e}")
except Exception as e:
st.error(f"Error preparing data for prediction: {e}")
Since this app is running from within a Jupyter Notebook environment, we need to port-forward the jupyter-tff service to Streamlit’s default port 8501:
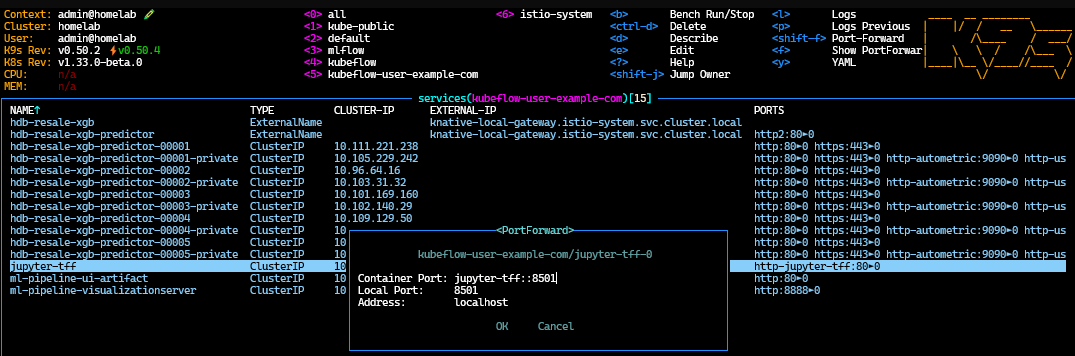
Once port-forwarding is active, open your browser and navigate to http://localhost:8501 to access the app interface:
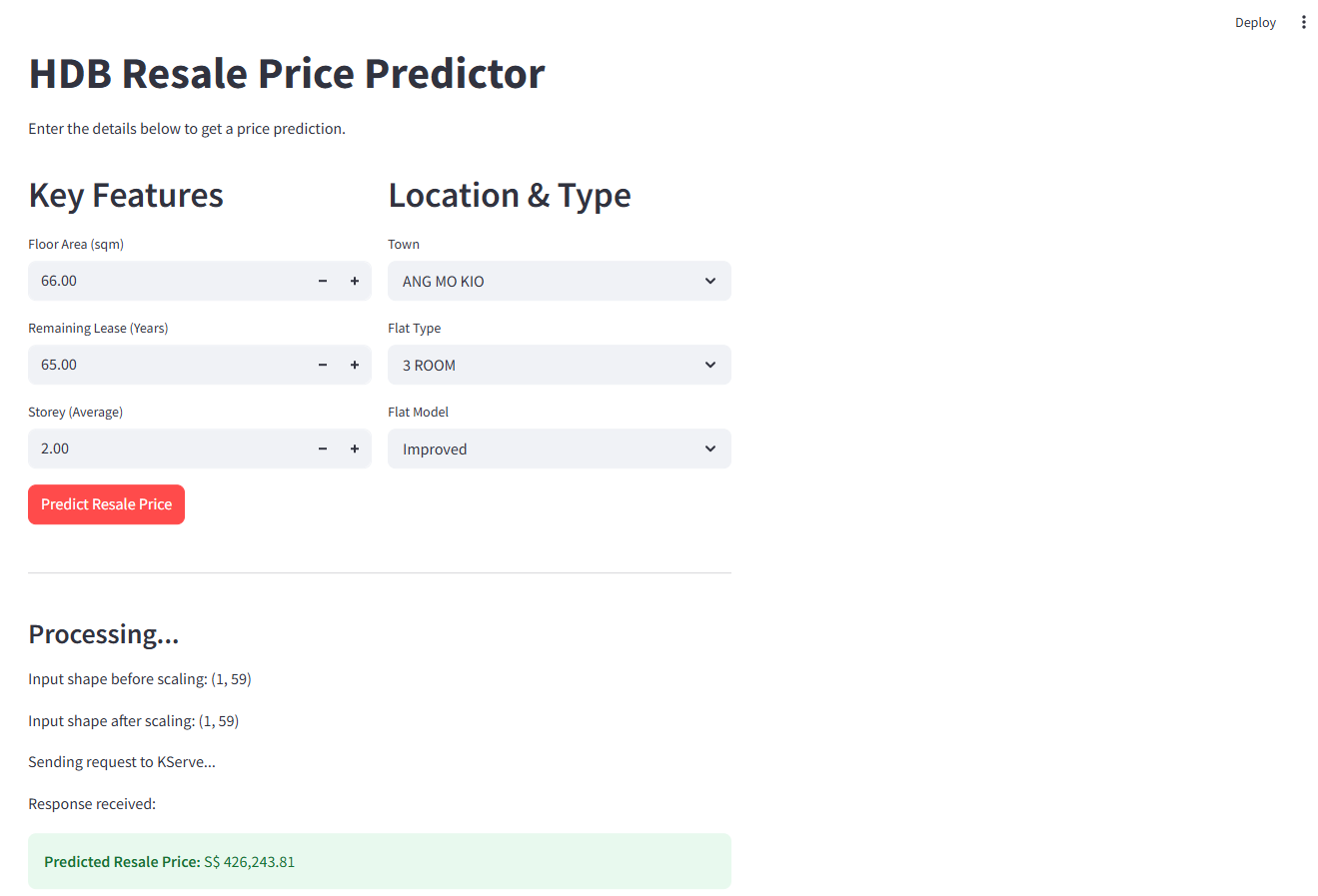
Bonus: Tracking Model Performance with MLflow
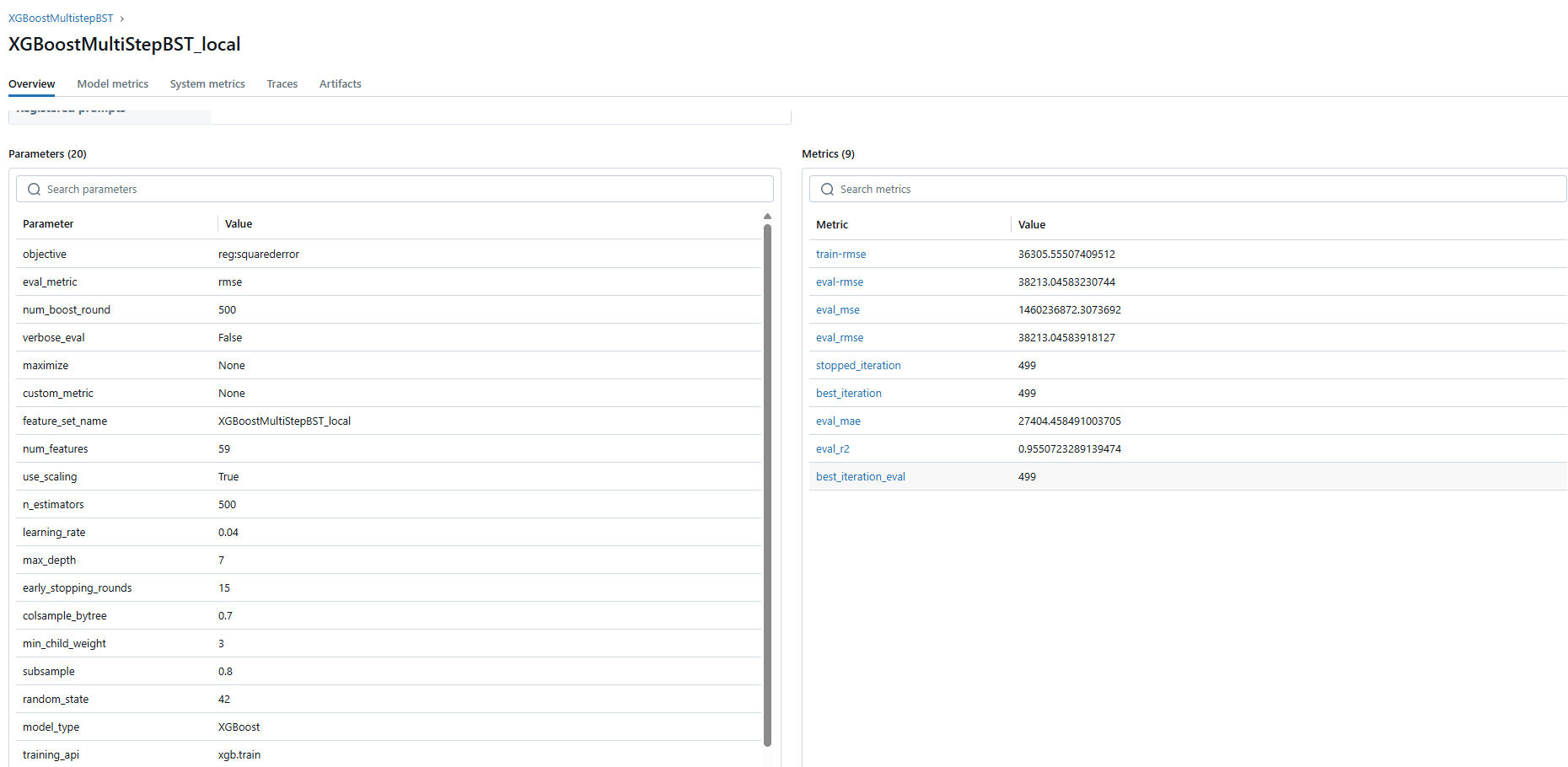
To better monitor model performance and track different training experiments, I used MLflow for experiment tracking. Below is a snapshot of the interface showing various model runs and their corresponding metrics:
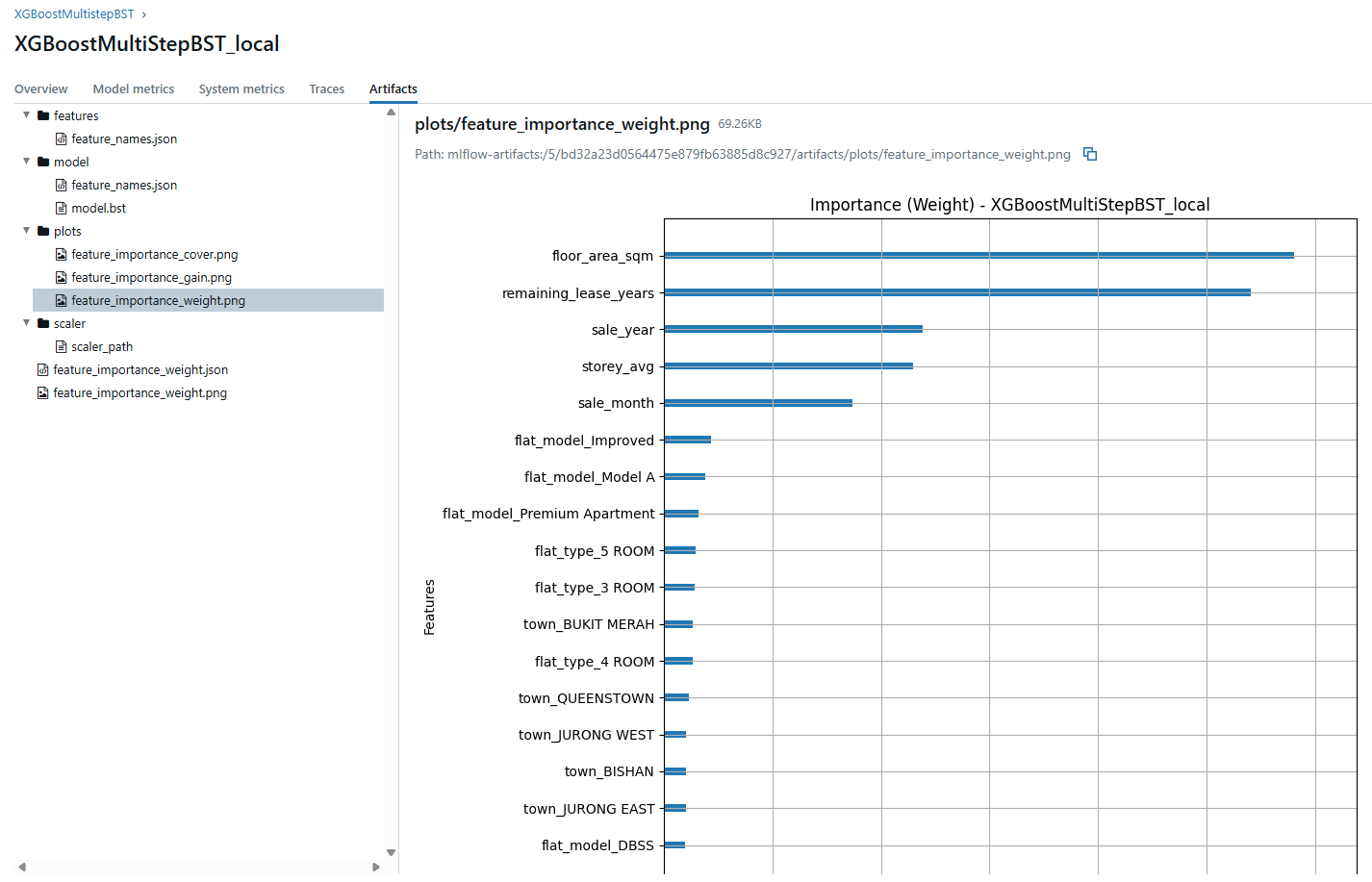
This setup helps keep experimentation organized and reproducible, especially when tuning hyperparameters or trying different data splits.
Conclusion
This walkthrough showcased how easy it is to get started with a full-featured Jupyter environment in Kubeflow using the jupyter-tensorflow-full image. By combining this with Streamlit, I was able to build and test an HDB resale price predictor app directly within my notebook server. With minimal setup and simple port forwarding, Kubeflow proves to be a solid platform not just for machine learning pipelines but also for interactive app development and experimentation.