Feature Impact on HDB predictions
Predicting HDB resale prices is a fascinating application of machine learning, blending feature engineering, neural networks, and advanced models like XGBoost. This post walks through the end-to-end process—from data loading and cleaning, to feature engineering, and preparing the dataset for predictive modeling. Let’s dive in using Singapore’s structured HDB Resale Flat Prices dataset from data.gov.sg.
Data Loading and Exploration
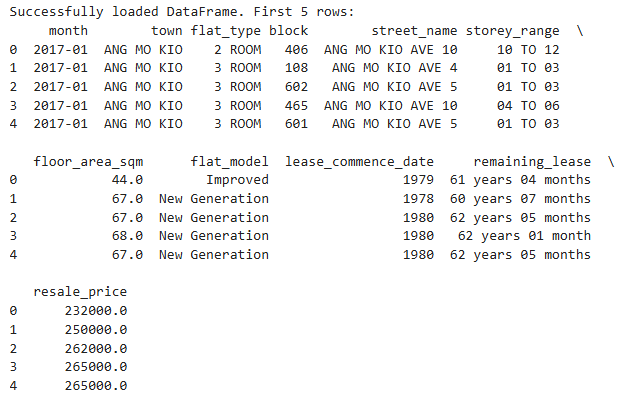
To begin, we load the HDB resale flat prices dataset and explore the first few rows.
import pandas as pd
file_path = 'Resale flat prices based on registration date from Jan-2017 onwards.csv'
try:
df = pd.read_csv(file_path, skipinitialspace=True)
print("Successfully loaded DataFrame. First 5 rows:")
print(df.head())
except FileNotFoundError:
print(f"Error: The file '{file_path}' was not found.")
exit()
except Exception as e:
print(f"An error occurred while reading the CSV file: {e}")
exit()
Feature Engineering & Preprocessing
To get meaningful insights from the dataset, we’ll process some of the raw columns and convert them into usable numerical features.
1. Extract remaining_lease_years
HDB leases are represented in strings like “92 years 3 months”. We’ll convert that into a single numerical column.
def extract_years(lease_str):
if pd.isna(lease_str):
return np.nan
parts = lease_str.split()
years = 0
for i, part in enumerate(parts):
if part.isdigit() and i+1 < len(parts) and parts[i+1].startswith('year'):
years += int(part)
elif part.isdigit() and i+1 < len(parts) and parts[i+1].startswith('month'):
years += int(part)/12
return years
print(f"\nMin original remaining lease: {df['remaining_lease'].min()}")
print(f"Max original remaining lease: {df['remaining_lease'].max()}")
df['remaining_lease_years'] = df['remaining_lease'].apply(extract_years)
print(f"\nMin remaining lease years: {df['remaining_lease_years'].min()}")
print(f"Max remaining lease years: {df['remaining_lease_years'].max()}")
print(f"NaNs in remaining lease years: {df['remaining_lease_years'].isna().sum()}")
if df['remaining_lease_years'].isna().any():
median_lease = df['remaining_lease_years'].median()
print(f"Imputing {df['remaining_lease_years'].isna().sum()} NaNs in remaining_lease_years with median value: {median_lease}")
df['remaining_lease_years'].fillna(median_lease, inplace=True)
# Sample Output
Min original remaining lease: 40 years 01 month
Max original remaining lease: 97 years 09 months
Min remaining lease years: 40.083333333333336
Max remaining lease years: 97.75
NaNs in remaining lease years: 0
2. Convert storey_range to Average Storey
Ranges like "04 TO 06" are transformed into a single value—here, the average storey number.
def convert_storey(storey_range):
if pd.isna(storey_range):
return np.nan
try:
low, high = map(int, storey_range.split(' TO '))
return (low + high) / 2.0
except:
print(f"Warning: Could not parse storey_range: {storey_range}")
return np.nan
print(f"\nMin in original storey_range: {df['storey_range'].min()}")
print(f"Max in original storey_range: {df['storey_range'].max()}")
df['storey_avg'] = df['storey_range'].apply(convert_storey)
print(f"\nMin in storey_avg: {df['storey_avg'].min()}")
print(f"Max in storey_avg: {df['storey_avg'].max()}")
print(f"\nNaNs in storey_avg: {df['storey_avg'].isna().sum()}")
if df['storey_avg'].isna().any():
median_storey = df['storey_avg'].median()
print(f"Imputing {df['storey_avg'].isna().sum()} NaNs in storey_avg with median value: {median_storey}")
df['storey_avg'].fillna(median_storey, inplace=True)
# Sample Output
Min in original storey_range: 01 TO 03
Max in original storey_range: 49 TO 51
Min in storey_avg: 2.0
Max in storey_avg: 50.0
NaNs in storey_avg: 0
3. Extracting Year & Month Components
From the month column (e.g., 2020-05), we extract:
- sale_year
- sale_month
- cyclical encodings (month_sin and month_cos) to capture seasonality.
import numpy as np
df['month'] = pd.to_datetime(df['month'], format='%Y-%m')
df['sale_year'] = df['month'].dt.year
df['sale_month'] = df['month'].dt.month
df['month_sin'] = np.sin(2 * np.pi * df['sale_month'] / 12.0)
df['month_cos'] = np.cos(2 * np.pi * df['sale_month'] / 12.0)
print(f"\nMin in original month: {df['month'].min()}")
print(f"Max in original month: {df['month'].max()}")
print(f"\nMin in sale_year: {df['sale_year'].min()}")
print(f"Max in sale_year: {df['sale_year'].max()}")
# Sample Output
Min in original month: 2017-01-01 00:00:00
Max in original month: 2025-04-01 00:00:00
Min in sale_year: 2017
Max in sale_year: 2025
4. One-Hot Encoding Categorical Features
To handle categorical features like flat_type, flat_model, and town, we use one-hot encoding.
categorical_cols = ['flat_type', 'flat_model', 'town']
print(f"\nApplying One-Hot Encoding to: {categorical_cols}")
df = pd.get_dummies(df, columns=categorical_cols, prefix=categorical_cols, dummy_na=False, dtype=int)
print(f"Shape after One-Hot Encoding: {df.shape}")
print("\nColumns after preprocessing:")
print(df.columns)
Post-encoding shape and preview:
# Sample Output
Applying One-Hot Encoding to: ['flat_type', 'flat_model', 'town']
Shape after One-Hot Encoding: (203694, 68)
Columns after preprocessing:
Index(['month', 'block', 'street_name', 'storey_range', 'floor_area_sqm',
'lease_commence_date', 'remaining_lease', 'resale_price',
'remaining_lease_years', 'storey_avg', 'sale_year', 'sale_month',
'month_sin', 'month_cos', 'flat_type_1 ROOM', 'flat_type_2 ROOM',
'flat_type_3 ROOM', 'flat_type_4 ROOM', 'flat_type_5 ROOM',
'flat_type_EXECUTIVE', 'flat_type_MULTI-GENERATION',
'flat_model_2-room', 'flat_model_3Gen', 'flat_model_Adjoined flat',
'flat_model_Apartment', 'flat_model_DBSS', 'flat_model_Improved',
'flat_model_Improved-Maisonette', 'flat_model_Maisonette',
'flat_model_Model A', 'flat_model_Model A-Maisonette',
'flat_model_Model A2', 'flat_model_Multi Generation',
'flat_model_New Generation', 'flat_model_Premium Apartment',
'flat_model_Premium Apartment Loft', 'flat_model_Premium Maisonette',
'flat_model_Simplified', 'flat_model_Standard', 'flat_model_Terrace',
'flat_model_Type S1', 'flat_model_Type S2', 'town_ANG MO KIO',
'town_BEDOK', 'town_BISHAN', 'town_BUKIT BATOK', 'town_BUKIT MERAH',
'town_BUKIT PANJANG', 'town_BUKIT TIMAH', 'town_CENTRAL AREA',
'town_CHOA CHU KANG', 'town_CLEMENTI', 'town_GEYLANG', 'town_HOUGANG',
'town_JURONG EAST', 'town_JURONG WEST', 'town_KALLANG/WHAMPOA',
'town_MARINE PARADE', 'town_PASIR RIS', 'town_PUNGGOL',
'town_QUEENSTOWN', 'town_SEMBAWANG', 'town_SENGKANG', 'town_SERANGOON',
'town_TAMPINES', 'town_TOA PAYOH', 'town_WOODLANDS', 'town_YISHUN'],
dtype='object')
Defining Features and Target
Now we prepare the dataset for model training:
- Numerical features:
floor_area_sqm,remaining_lease_years,storey_avg,sale_year,sale_month - Categorical (One-hot): Selected
townandflat_modelcolumns - Target:
resale_price
numerical_features = ['floor_area_sqm', 'remaining_lease_years', 'storey_avg', 'sale_year', 'sale_month']
categorical_prefixes = {
'flat_type': [col for col in df.columns if col.startswith('flat_type_')],
'flat_model': [col for col in df.columns if col.startswith('flat_model_')],
'town': [col for col in df.columns if col.startswith('town_')]
}
feature_columns = numerical_features + categorical_prefixes['town'] + categorical_prefixes['flat_model']
target_column = 'resale_price'
X = df[feature_columns].values
y = df[target_column].values
print(f"\nShape of X: {X.shape}")
print(f"Shape of y: {y.shape}")
print(f"Successfully prepared X and y for training.")
# Sample Output
Shape of X: (203694, 52)
Shape of y: (203694,)
Successfully prepared X and y for training.
In the next part, we’ll feed this preprocessed data into machine learning models—starting with neural networks, then comparing with XGBoost for boosted performance.
Neural Networks
With the features and target variable prepped, I experimented with a simple feedforward neural network using Keras. This serves as a strong baseline model for structured data like the HDB resale dataset.
Neural Networks - python code
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
def train_model_with_features(X_data, y_data, feature_names, epochs=50, batch_size=64, verbose=1):
# Split data
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=42)
# Scale the data
X_scaler = MinMaxScaler()
y_scaler = MinMaxScaler()
X_train_scaled = X_scaler.fit_transform(X_train) # Fit and transform Train
X_test_scaled = X_scaler.transform(X_test) # Transform Test
y_train_scaled = y_scaler.fit_transform(y_train.reshape(-1, 1)).flatten() # Fit and transform Train
y_test_scaled = y_scaler.transform(y_test.reshape(-1, 1)).flatten() # Transform Test
if verbose >= 1:
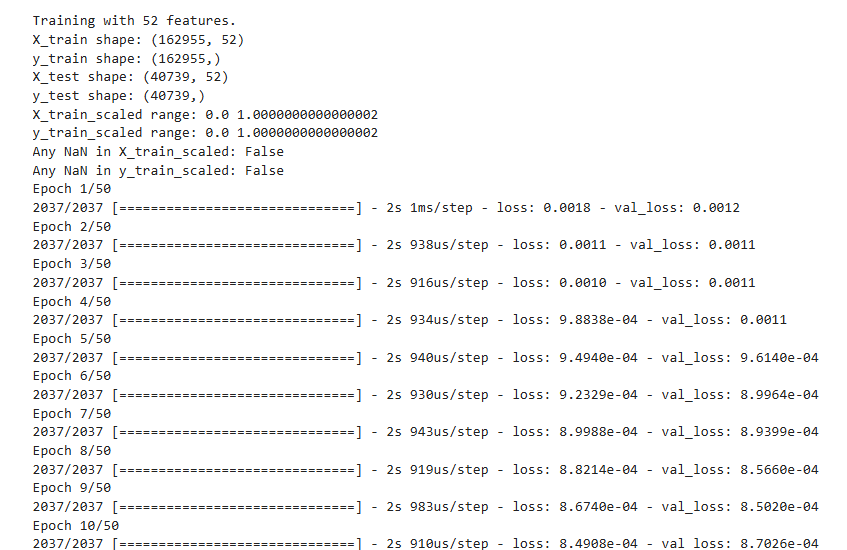
print(f"\nTraining with {len(feature_names)} features.")
print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape)
print("X_train_scaled range:", X_train_scaled.min(), X_train_scaled.max())
print("y_train_scaled range:", y_train_scaled.min(), y_train_scaled.max())
print("Any NaN in X_train_scaled:", np.isnan(X_train_scaled).any())
print("Any NaN in y_train_scaled:", np.isnan(y_train_scaled).any())
# Build model
model = Sequential([
Dense(64, activation='relu', input_shape=(X_train_scaled.shape[1],)),
Dense(32, activation='relu'),
Dense(1)
])
# Compile model
model.compile(optimizer=Adam(learning_rate=0.001), loss='mse') # Use MSE for regression
# Train with early stopping
early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
# Train model
history = model.fit(
X_train_scaled, y_train_scaled,
epochs=epochs,
batch_size=batch_size,
validation_split=0.2, # Validation on a split of the training data
callbacks=[early_stop],
verbose=verbose
)
# Make predictions
y_pred_scaled = model.predict(X_test_scaled)
y_pred = y_scaler.inverse_transform(y_pred_scaled).flatten()
# Calculate metrics using the original UNscaled test data
mse = np.mean((y_test - y_pred)**2)
rmse = np.sqrt(mse)
mae = np.mean(np.abs(y_test - y_pred))
if np.var(y_test) > 1e-9:
r2 = 1 - (np.sum((y_test - y_pred)**2) / np.sum((y_test - np.mean(y_test))**2))
else:
r2 = np.nan
# Print results
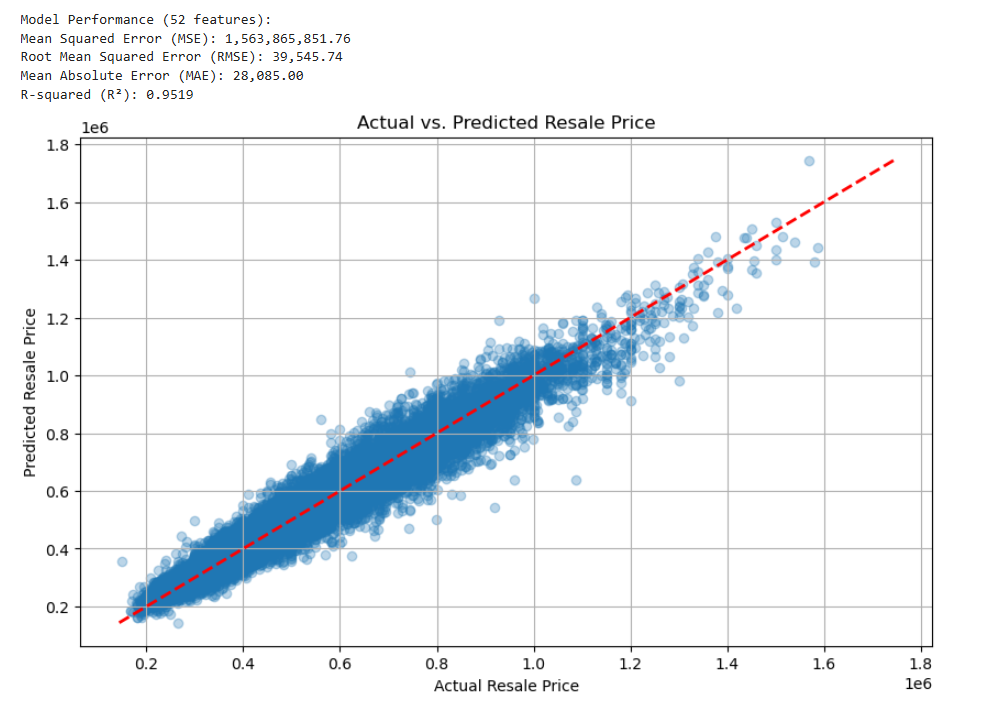
print(f"\nModel Performance ({len(feature_names)} features):")
print(f"Mean Squared Error (MSE): {mse:,.2f}")
print(f"Root Mean Squared Error (RMSE): {rmse:,.2f}")
print(f"Mean Absolute Error (MAE): {mae:,.2f}")
print(f"R-squared (R²): {r2:.4f}")
# Plotting (Plot against one key feature or just residuals)
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.3)
plt.plot([min(y_test.min(), y_pred.min()), max(y_test.max(), y_pred.max())],
[min(y_test.min(), y_pred.min()), max(y_test.max(), y_pred.max())],
'--', color='red', linewidth=2)
plt.xlabel('Actual Resale Price')
plt.ylabel('Predicted Resale Price')
plt.title('Actual vs. Predicted Resale Price')
plt.grid(True)
plt.show()
# Check if history object contains loss and val_loss
if 'loss' in history.history and 'val_loss' in history.history:
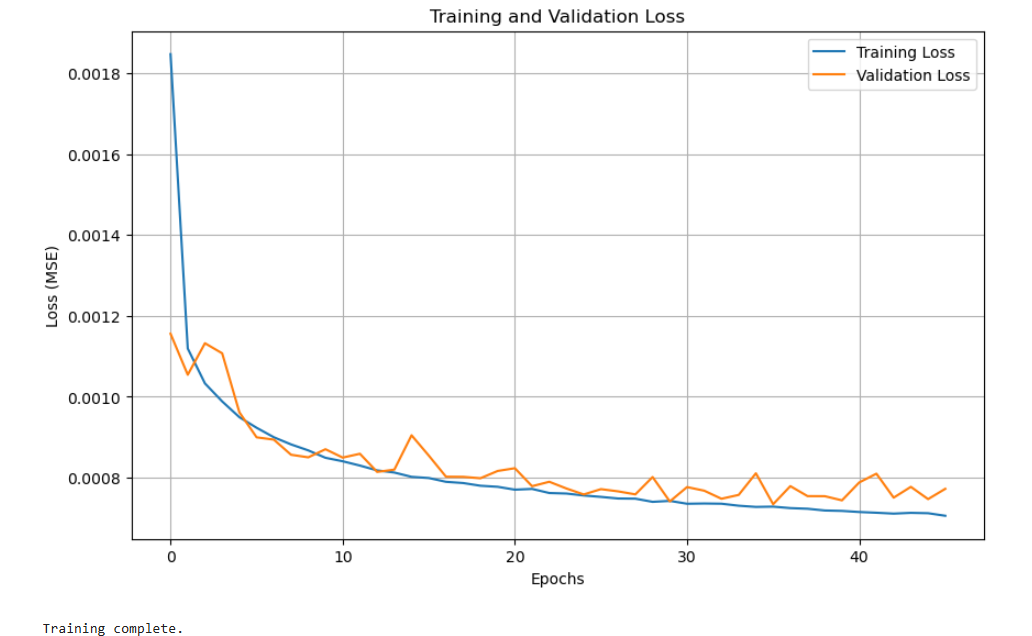
plt.figure(figsize=(10, 6))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss (MSE)')
plt.title('Training and Validation Loss')
plt.legend()
plt.grid(True)
plt.show()
else:
print("Loss history not found for plotting.")
return {
'model': model, 'history': history, 'X_test': X_test, 'y_test': y_test,
'y_pred': y_pred, 'mse': mse, 'rmse': rmse, 'r2': r2, 'mae': mae,
'X_scaler': X_scaler, 'y_scaler': y_scaler, 'feature_names': feature_names
}
results = train_model_with_features(X, y, feature_columns, epochs=50, batch_size=64, verbose=1)
print("\nTraining complete.")
The model learns to minimize Mean Squared Error (MSE), and we track Mean Absolute Error (MAE) to gauge real-world price prediction deviation.
Training History
You can visualize how the model trains over time—helpful for spotting underfitting or overfitting trends.
Neural Network Predict Price
After training, the model’s performance on unseen test data is crucial.
Neural Networks Predict Price - python code
def predict_price(input_data, model, x_scaler, y_scaler, feature_names_list):
try:
df_input = pd.DataFrame([input_data])
original_categorical_cols = []
if 'town' in df_input.columns:
original_categorical_cols.append('town')
if 'flat_type' in df_input.columns:
original_categorical_cols.append('flat_type')
if original_categorical_cols:
df_input = pd.get_dummies(df_input, columns=original_categorical_cols, dtype=int)
df_aligned = df_input.reindex(columns=feature_names_list, fill_value=0)
X_new = df_aligned.values
expected_features = model.input_shape[1]
if X_new.shape[1] != expected_features:
print(f"Error: Input data has {X_new.shape[1]} features, but model expects {expected_features}.")
print("Feature mismatch. Ensure input_data and feature_names_list are correct.")
print("Expected features:", feature_names_list)
print("Provided features after processing:", df_aligned.columns.tolist())
return None
X_new_scaled = x_scaler.transform(X_new)
y_pred_scaled = model.predict(X_new_scaled)
y_pred = y_scaler.inverse_transform(y_pred_scaled)
predicted_price = y_pred[0][0]
return predicted_price
except Exception as e:
print(f"An error occurred during prediction: {e}")
import traceback
traceback.print_exc()
return None
# Assuming 'results' is the dictionary returned by your train_model_with_features function
trained_model = results['model']
fitted_x_scaler = results['X_scaler']
fitted_y_scaler = results['y_scaler']
model_feature_names = results['feature_names']
# Create a dictionary representing the flat you want to predict
new_flat_data = {
'floor_area_sqm': 44.0,
'remaining_lease_years': 61.333,
'storey_avg': 2.0,
'sale_year': 2018,
'sale_month': 1,
'town': 'ANG MO KIO',
'flat_type': '3 ROOM'
}
# Predict the price
predicted_hdb_price = predict_price(
input_data=new_flat_data,
model=trained_model,
x_scaler=fitted_x_scaler,
y_scaler=fitted_y_scaler,
feature_names_list=model_feature_names
)
# Display the result
if predicted_hdb_price is not None:
print("\n--- Prediction ---")
print(f"Input Features: {new_flat_data}")
print(f"Predicted Resale Price: ${predicted_hdb_price:,.2f}")
else:
print("\nPrediction failed. Please check the input data and error messages.")
This gives a sense of how close our predicted resale prices are to the actual values.
# Sample Output
1/1 [==============================] - 0s 11ms/step
--- Prediction ---
Input Features: {'floor_area_sqm': 44.0, 'remaining_lease_years': 61.333, 'storey_avg': 2.0, 'sale_year': 2018, 'sale_month': 1, 'town': 'ANG MO KIO', 'flat_type': '3 ROOM'}
Predicted Resale Price: $248,929.12
XGBoost Regressor
To complement the neural network, I also trained a Gradient Boosted Trees model using XGBoost—a powerful algorithm for tabular data.
XGBoost Regressor - python code
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import xgboost as xgb
from xgboost import plot_importance
import mlflow
import mlflow.xgboost
import os
import joblib
import traceback
def get_dynamic_figsize(feature_count, max_features=20):
height = min(14, max(6, min(feature_count, max_features) * 0.4))
width = 12
return (width, height)
def train_xgboost_model(X_data, y_data, feature_names, n_estimators=100, learning_rate=0.1, max_depth=5, early_stopping_rounds=10,
colsample_bytree=0.8, min_child_weight=1, use_scaling=False, verbose=False, run_name=None):
mlflow.xgboost.autolog(
log_input_examples=False,
log_model_signatures=False,
log_models=False,
log_datasets=True,
disable=False,
)
active_run = mlflow.active_run()
if active_run is None:
mlflow.start_run(run_name=run_name)
else:
mlflow.set_tag("mlflow.runName", run_name)
try:
current_run = mlflow.active_run()
current_run_id = current_run.info.run_id
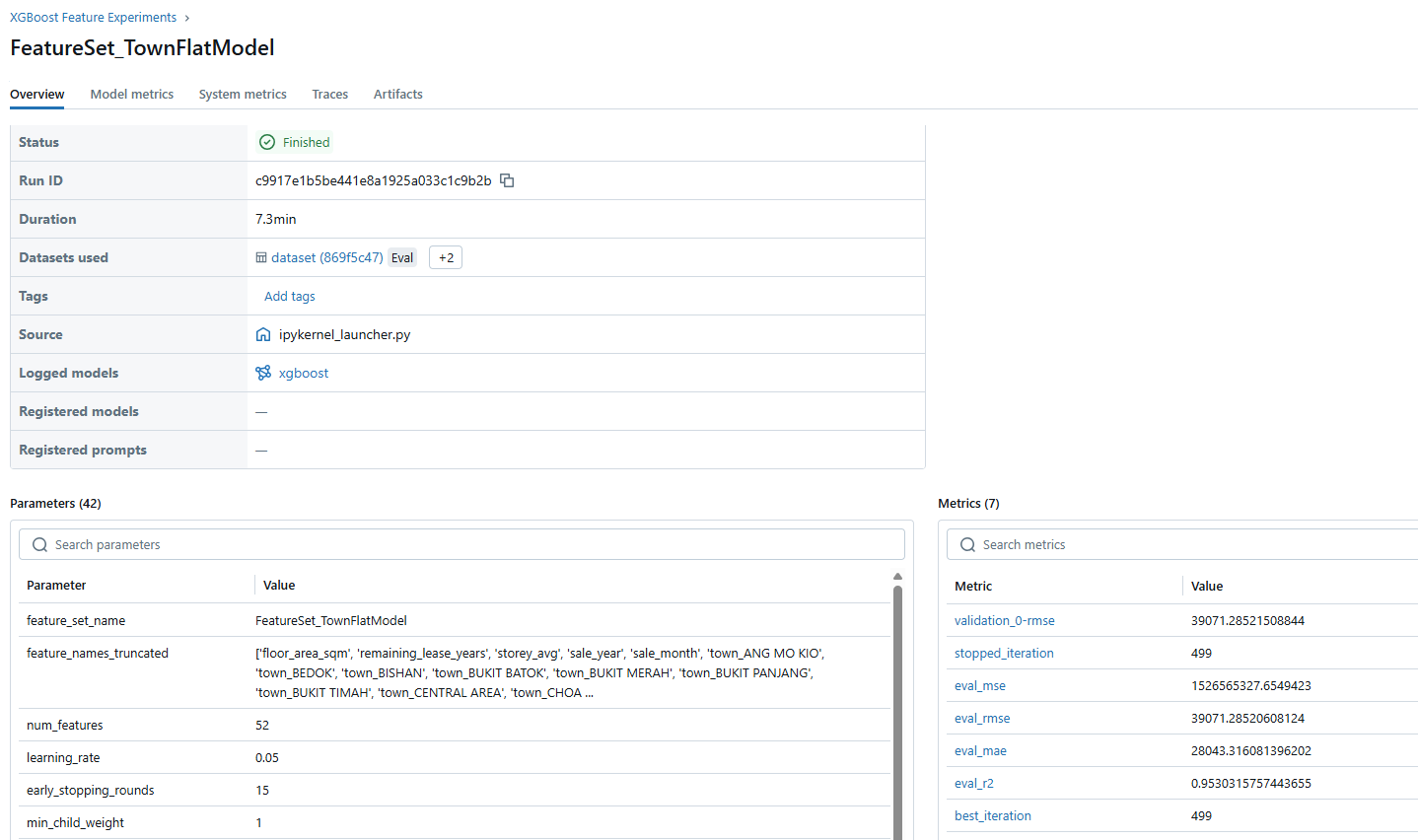
print(f"Using MLflow Run ID: {current_run_id}")
print("Logging parameters manually...")
mlflow.log_param("feature_set_name", run_name if run_name else "default_feature_set")
mlflow.log_param("num_features", len(feature_names))
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("learning_rate", learning_rate)
mlflow.log_param("max_depth", max_depth)
mlflow.log_param("early_stopping_rounds", early_stopping_rounds)
mlflow.log_param("colsample_bytree", colsample_bytree)
mlflow.log_param("min_child_weight", min_child_weight)
mlflow.log_param("use_scaling", use_scaling)
max_len = 250
feature_names_str = str(feature_names)
if len(feature_names_str) > max_len:
mlflow.log_param("feature_names_truncated", feature_names_str[:max_len-3] + "...")
with open("feature_names.txt", "w") as f:
f.write(feature_names_str)
mlflow.log_artifact("feature_names.txt")
os.remove("feature_names.txt")
else:
mlflow.log_param("feature_names", feature_names_str)
# --- Data Preparation ---
if not isinstance(X_data, pd.DataFrame):
print("Converting X_data (NumPy array) to DataFrame using provided feature_names.")
X_data = pd.DataFrame(X_data, columns=feature_names)
X_data.columns = feature_names
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=42)
X_scaler = None
if use_scaling:
print("Using Scaled Features for XGBoost.")
X_scaler = MinMaxScaler()
# Fit on Training, Transform Train and Test
X_train_scaled_np = X_scaler.fit_transform(X_train)
X_test_scaled_np = X_scaler.transform(X_test)
# Convert back to DataFrame with original index and columns
X_train = pd.DataFrame(X_train_scaled_np, columns=feature_names, index=X_train.index)
X_test = pd.DataFrame(X_test_scaled_np, columns=feature_names, index=X_test.index)
print(f"X_train range (scaled): {X_train.values.min():.4f} to {X_train.values.max():.4f}")
try:
scaler_path = "min_max_scaler.joblib"
joblib.dump(X_scaler, scaler_path)
mlflow.log_artifact(scaler_path, artifact_path="scaler")
os.remove(scaler_path)
print("Scaler logged as artifact.")
except Exception as e:
print(f"Warning: Could not save or log scaler: {e}")
else:
print("Using Original Features for XGBoost.")
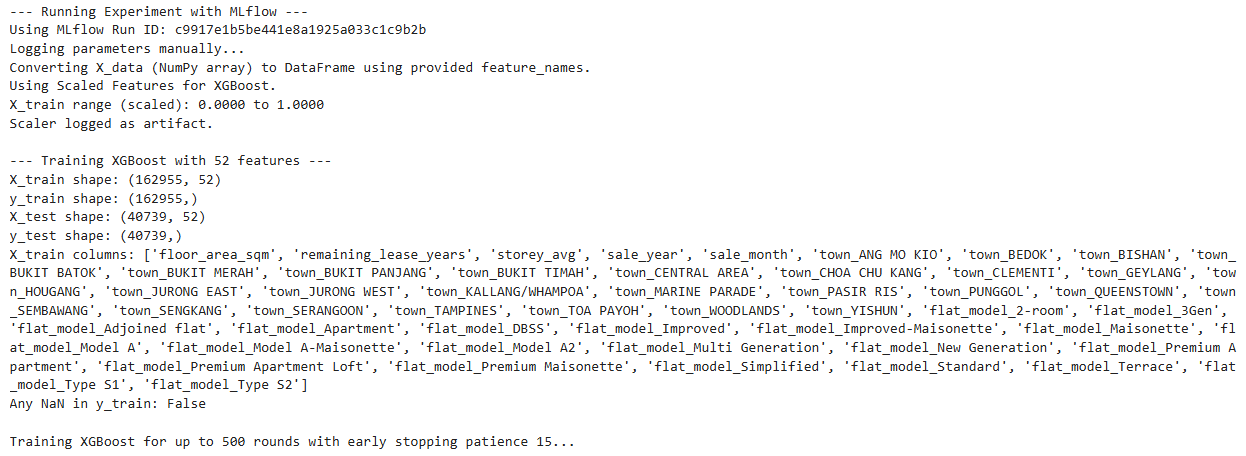
print(f"\n--- Training XGBoost with {len(feature_names)} features ---")
print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape)
print("X_train columns:", list(X_train.columns))
if isinstance(y_train, pd.DataFrame): y_train_series = y_train.iloc[:, 0]
elif isinstance(y_train, np.ndarray): y_train_series = pd.Series(y_train.ravel())
else: y_train_series = y_train
print("Any NaN in y_train:", y_train_series.isnull().any())
# --- Model Training ---
xgb_model = xgb.XGBRegressor(
objective='reg:squarederror',
n_estimators=n_estimators,
learning_rate=learning_rate,
max_depth=max_depth,
subsample=0.8,
colsample_bytree=colsample_bytree,
min_child_weight=min_child_weight,
random_state=42,
n_jobs=-1,
enable_categorical=False,
eval_metric='rmse',
early_stopping_rounds=early_stopping_rounds
)
eval_set = [(X_test, y_test)]
print(f"\nTraining XGBoost for up to {n_estimators} rounds with early stopping patience {early_stopping_rounds}...")
xgb_model.fit(
X_train, y_train,
eval_set=eval_set,
verbose=verbose
)
mlflow.xgboost.log_model(xgb_model, "model")
# --- Prediction and Evaluation ---
y_pred = xgb_model.predict(X_test)
if isinstance(y_test, (pd.Series, pd.DataFrame)):
y_test_np = y_test.values.ravel()
else:
y_test_np = np.array(y_test).ravel()
valid_indices = ~np.isnan(y_test_np) & ~np.isinf(y_test_np) & ~np.isnan(y_pred) & ~np.isinf(y_pred)
if not np.all(valid_indices):
print("Warning: NaN or Inf detected in y_test or y_pred. Metrics calculated on valid data points only.")
y_test_np = y_test_np[valid_indices]
y_pred = y_pred[valid_indices]
mse = np.mean((y_test_np - y_pred)**2)
rmse = np.sqrt(mse)
mae = np.mean(np.abs(y_test_np - y_pred))
if np.var(y_test_np) > 1e-9:
r2 = 1 - (np.sum((y_test_np - y_pred)**2) / np.sum((y_test_np - np.mean(y_test_np))**2))
else:
r2 = np.nan
best_iteration = xgb_model.best_iteration if hasattr(xgb_model, 'best_iteration') and xgb_model.best_iteration is not None else n_estimators
# --- Log Metrics Manually ---
print("\nLogging final evaluation metrics to MLflow...")
mlflow.log_metric("eval_mse", mse)
mlflow.log_metric("eval_rmse", rmse)
mlflow.log_metric("eval_mae", mae)
if not np.isnan(r2):
mlflow.log_metric("eval_r2", r2)
mlflow.log_metric("best_iteration", best_iteration)
print("\n--- XGBoost Model Performance ---")
print(f"(Features: {len(feature_names)}, Scaled: {use_scaling})")
print(f"Best Iteration: {best_iteration}")
print(f"Test Set MSE: {mse:,.4f}")
print(f"Test Set RMSE: {rmse:,.4f}")
print(f"Test Set MAE: {mae:,.4f}")
print(f"Test Set R²: {'N/A' if np.isnan(r2) else f'{r2:.4f}'}")
# --- Log Custom Plots as Artifacts ---
print("Generating and logging custom plots to MLflow...")
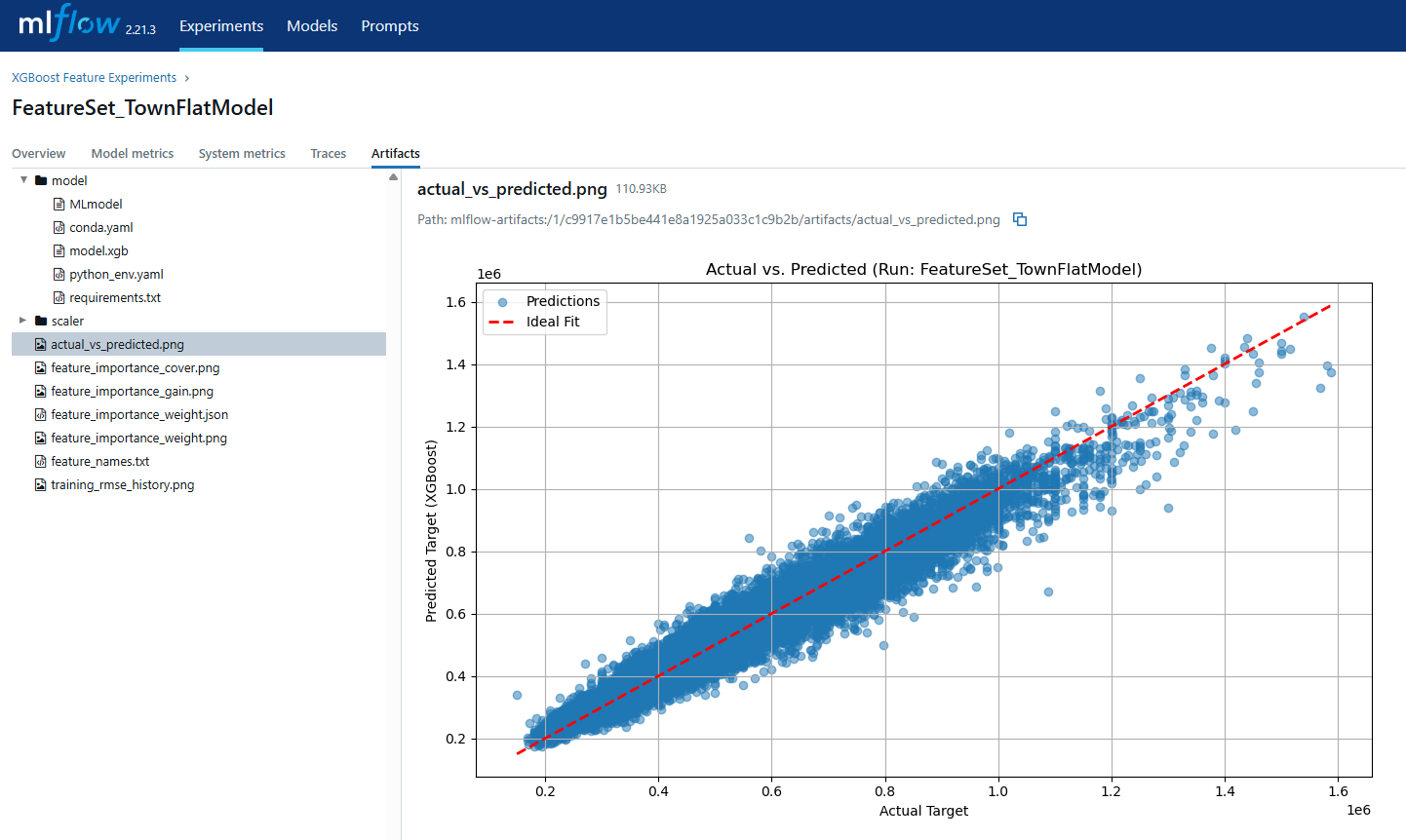
# Plotting Actual vs Predicted
try:
fig_pred, ax_pred = plt.subplots(figsize=(10, 6))
ax_pred.scatter(y_test_np, y_pred, alpha=0.5, label="Predictions")
min_val = min(y_test_np.min(), y_pred.min())
max_val = max(y_test_np.max(), y_pred.max())
ax_pred.plot([min_val, max_val], [min_val, max_val], '--', color='red', linewidth=2, label="Ideal Fit")
ax_pred.set_xlabel('Actual Target')
ax_pred.set_ylabel('Predicted Target (XGBoost)')
ax_pred.set_title(f'Actual vs. Predicted (Run: {run_name or current_run_id[:8]})')
ax_pred.legend()
ax_pred.grid(True)
plt.tight_layout()
mlflow.log_figure(fig_pred, "actual_vs_predicted.png")
plt.close(fig_pred)
print("Logged actual_vs_predicted.png")
except Exception as e:
print(f"Could not plot or log Actual vs Predicted plot: {e}")
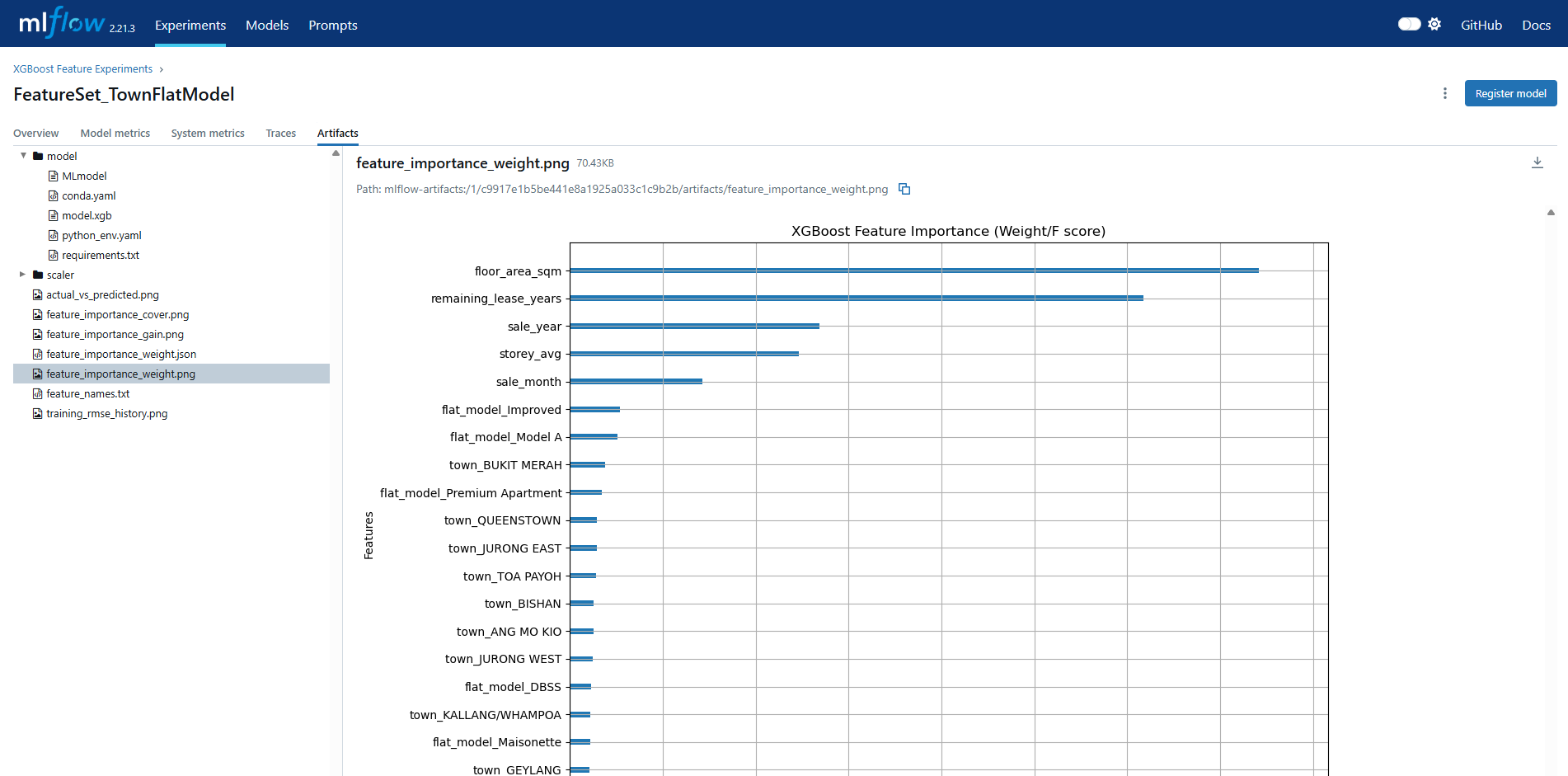
try:
# Weight importance
fig_imp_w, ax_imp_w = plt.subplots(figsize=get_dynamic_figsize(len(feature_names)))
plot_importance(xgb_model, ax=ax_imp_w, max_num_features=20, importance_type='weight', show_values=False)
ax_imp_w.set_title('XGBoost Feature Importance (Weight/F score)')
plt.tight_layout()
mlflow.log_figure(fig_imp_w, "feature_importance_weight.png")
plt.close(fig_imp_w)
print("Logged feature_importance_weight.png")
# Gain importance
fig_imp_g, ax_imp_g = plt.subplots(figsize=get_dynamic_figsize(len(feature_names)))
plot_importance(xgb_model, ax=ax_imp_g, max_num_features=20, importance_type='gain', show_values=False)
ax_imp_g.set_title('XGBoost Feature Importance (Gain)')
plt.tight_layout()
mlflow.log_figure(fig_imp_g, "feature_importance_gain.png")
plt.close(fig_imp_g)
print("Logged feature_importance_gain.png")
# Cover importance
fig_imp_c, ax_imp_c = plt.subplots(figsize=get_dynamic_figsize(len(feature_names)))
plot_importance(xgb_model, ax=ax_imp_c, max_num_features=20, importance_type='cover', show_values=False)
ax_imp_c.set_title('XGBoost Feature Importance (Cover)')
plt.tight_layout()
mlflow.log_figure(fig_imp_c, "feature_importance_cover.png")
plt.close(fig_imp_c)
print("Logged feature_importance_cover.png")
except Exception as e:
print(f"Could not plot or log importance plots: {e}")
# Plot training history (RMSE)
try:
results = xgb_model.evals_result()
if results and 'validation_0' in results and 'rmse' in results['validation_0']:
eval_metric_history = results['validation_0']['rmse']
fig_hist, ax_hist = plt.subplots(figsize=(10, 6))
epochs_ran = len(eval_metric_history)
x_axis = range(0, epochs_ran)
ax_hist.plot(x_axis, eval_metric_history, label='Validation RMSE')
ax_hist.set_xlabel('Boosting Rounds')
ax_hist.set_ylabel('RMSE')
ax_hist.set_title('XGBoost Training History (Validation RMSE)')
ax_hist.legend()
ax_hist.grid(True)
plt.tight_layout()
mlflow.log_figure(fig_hist, "training_rmse_history.png")
plt.close(fig_hist)
print("Logged training_rmse_history.png")
except Exception as e:
print(f"Could not plot or log training history plot: {e}")
mlflow.end_run()
print("MLflow Run completed and logging finished.")
return {
'mlflow_run_id': current_run_id,
'model': xgb_model,
'evals_result': xgb_model.evals_result() if hasattr(xgb_model, 'evals_result') else None,
'X_test': X_test,
'y_test': y_test,
'y_pred': y_pred,
'mse': mse,
'rmse': rmse,
'r2': r2,
'mae': mae,
'X_scaler': X_scaler,
'feature_names': feature_names,
'best_iteration': best_iteration
}
finally:
if active_run is None:
mlflow.end_run()
print("--- Running Experiment with MLflow ---")
xgb_results = train_xgboost_model(
X,
y,
feature_columns,
n_estimators=500,
learning_rate=0.05,
max_depth=6,
early_stopping_rounds=15,
use_scaling=True,
verbose=False,
run_name="FeatureSet_TownFlatModel"
)
XGBoost Predict Price
XGBoost Predict Price - python code
import pandas as pd
import numpy as np
def predict_price_xgboost(input_data_dict, model, scaler, feature_names):
# 1. Convert input dict to DataFrame
try:
new_data_raw = pd.DataFrame(input_data_dict, index=[0])
except ValueError:
new_data_raw = pd.DataFrame({k: [v] for k, v in input_data_dict.items()}, index=[0])
print("--- Preprocessing New Data Inside Wrapper ---")
new_data_processed = new_data_raw.copy()
# --- Apply THE SAME Preprocessing Steps as Training Data ---
if 'month' in new_data_processed.columns:
new_data_processed['month'] = pd.to_datetime(new_data_processed['month'], format='%Y-%m')
new_data_processed['sale_year'] = new_data_processed['month'].dt.year
new_data_processed['sale_month'] = new_data_processed['month'].dt.month
new_data_processed['month_sin'] = np.sin(2 * np.pi * new_data_processed['sale_month'] / 12.0)
new_data_processed['month_cos'] = np.cos(2 * np.pi * new_data_processed['sale_month'] / 12.0)
if 'remaining_lease' in new_data_processed.columns:
new_data_processed['remaining_lease_years'] = new_data_processed['remaining_lease'].apply(extract_years)
if 'storey_range' in new_data_processed.columns:
new_data_processed['storey_avg'] = new_data_processed['storey_range'].apply(convert_storey)
categorical_cols_base = ['flat_type', 'flat_model', 'town']
cols_to_encode = [col for col in categorical_cols_base if col in new_data_processed.columns]
if cols_to_encode:
new_data_processed = pd.get_dummies(new_data_processed, columns=cols_to_encode, prefix=cols_to_encode, dummy_na=False, dtype=int)
# --- Align columns to the required feature_names ---
print(f"Aligning columns to {len(feature_names)} features...")
try:
X_new_prepared = new_data_processed.reindex(columns=feature_names, fill_value=0)
except Exception as e:
print(f"Error during reindex. Check feature_names and processed columns. Error: {e}")
print("Columns in processed data:", list(new_data_processed.columns))
print("Columns expected by model:", feature_names)
return None
print("Columns aligned.")
# --- Scaling (if applicable) ---
X_new_scaled = X_new_prepared
if scaler is not None:
print("Applying scaler...")
try:
X_new_scaled_np = scaler.transform(X_new_prepared)
X_new_scaled = pd.DataFrame(X_new_scaled_np, columns=feature_names, index=X_new_prepared.index)
except Exception as e:
print(f"Error during scaling. Check data types. Error: {e}")
print("Data dtypes before scaling:\n", X_new_prepared.dtypes)
return None # Or raise error
else:
print("No scaler applied.")
# --- Prediction ---
print("Making prediction...")
try:
prediction = model.predict(X_new_scaled)
final_prediction = prediction[0] if isinstance(prediction, np.ndarray) else prediction
print("Prediction successful.")
return final_prediction
except Exception as e:
print(f"Error during model prediction: {e}")
return None
xgb_model = xgb_results['model']
X_scaler = xgb_results['X_scaler']
feature_names = list(xgb_results['feature_names'])
new_flat_data_raw = {
'floor_area_sqm': 44.0,
'remaining_lease': '61 years 4 months',
'storey_range': '01 TO 03',
'month': '2018-01',
'town': 'ANG MO KIO',
'flat_type': '3 ROOM'
}
predicted_price_xgb = predict_price_xgboost(
input_data_dict=new_flat_data_raw,
model=xgb_model,
scaler=X_scaler,
feature_names=feature_names
)
if predicted_price_xgb is not None:
print(f"\nPredicted HDB Price (XGBoost): ${predicted_price_xgb:,.2f}")
else:
print("\nXGBoost prediction failed.")
# Sample Output
--- Preprocessing New Data Inside Wrapper ---
Aligning columns to 52 features...
Columns aligned.
Applying scaler...
Making prediction...
Prediction successful.
Predicted HDB Price (XGBoost): $213,966.08
Optional - Experimenting with Features
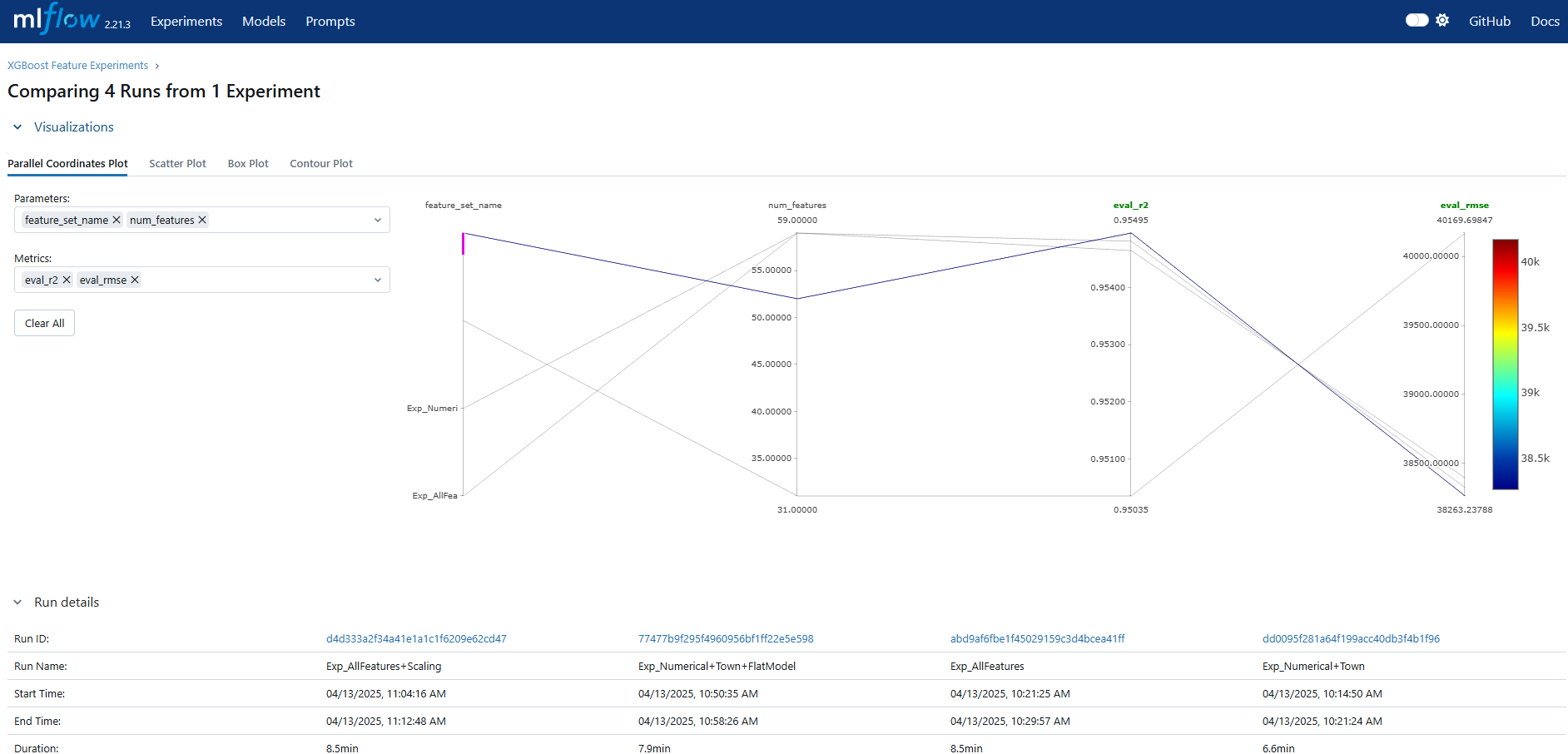
To evaluate the impact of various feature combinations, I conducted a series of XGBoost experiments—exploring numerical, categorical, and engineered features. Each setup was tracked using MLflow to capture key performance metrics such as RMSE, MAE, and R². Here’s how the different feature sets performed:
Features experimenting - python code
- Features Setup
numerical_features = ['floor_area_sqm', 'remaining_lease_years', 'storey_avg', 'sale_year', 'sale_month']
categorical_prefixes = {
'flat_type': [col for col in X_data.columns if col.startswith('flat_type_')],
'flat_model': [col for col in X_data.columns if col.startswith('flat_model_')],
'town': [col for col in X_data.columns if col.startswith('town_')]
}
# Time-based features
df_processed['years_since_2017'] = df_processed['sale_year'] - 2017
df_processed['month_of_year'] = df_processed['sale_month'].apply(lambda x: (x-1)//3 + 1) # Quarters
# Space-time interactions
df_processed['storey_per_floor_area'] = df_processed['storey_avg'] / df_processed['floor_area_sqm']
# Lease remaining ratios
df_processed['lease_floor_ratio'] = df_processed['remaining_lease_years'] / df_processed['floor_area_sqm']
time_features = ['years_since_2017', 'month_of_year']
numerical_less_time_features = ['floor_area_sqm', 'remaining_lease_years', 'storey_avg']
month_sin_cos_features = ['month_sin', 'month_cos']
interaction_features = ['storey_per_floor_area', 'lease_floor_ratio']
new_engineered_features = time_features + interaction_features + month_sin_cos_features
for feature in new_engineered_features:
X_data[feature] = df_processed[feature]
- Experiment Setup
experiments = [
{
'name': 'Numerical+TimeBased',
'features': time_features + numerical_less_time_features,
'use_scaling': True
},
{
'name': 'NumericalOnly',
'features': numerical_features,
'use_scaling': True
},
{
'name': 'Numerical+FlatType',
'features': numerical_features + categorical_prefixes['flat_type'],
'use_scaling': True
},
{
'name': 'Numerical+FlatModel',
'features': numerical_features + categorical_prefixes['flat_model'],
'use_scaling': True
},
{
'name': 'Numerical+Town',
'features': numerical_features + categorical_prefixes['town'],
'use_scaling': True
},
{
'name': 'AllFeatures',
'features': numerical_features + categorical_prefixes['flat_type'] +
categorical_prefixes['flat_model'] + categorical_prefixes['town'],
'use_scaling': False
},
{
'name': 'Numerical+Engineered',
'features': numerical_features + new_engineered_features,
'use_scaling': True
},
{
'name': 'AllFeatures+Scaling',
'features': numerical_features + categorical_prefixes['flat_type'] +
categorical_prefixes['flat_model'] + categorical_prefixes['town'],
'use_scaling': True
},
{
'name': 'Numerical+Town+FlatModel',
'features': numerical_features + categorical_prefixes['town'] + categorical_prefixes['flat_model'],
'use_scaling': True
},
]
- Running Experiments
experiment_results = []
for exp in experiments:
print(f"\n--- Running Experiment: {exp['name']} ---")
print(f"Features ({len(exp['features'])}): {exp['features'][:5]}...")
if 'preprocessor' in exp:
X_modified = exp['preprocessor'](X_data.copy())
else:
X_modified = X_data
# Dynamic hyperparameter adjustment based on feature count
feature_count = len(exp['features'])
learning_rate = 0.05
max_depth = 6
colsample_bytree = 0.8
min_child_weight = 1
# Adjust parameters for larger feature sets
if feature_count > 30:
learning_rate = 0.04
max_depth = 7
colsample_bytree = 0.7
min_child_weight = 3
xgb_results = train_xgboost_model(
X_modified[exp['features']],
y_data,
feature_names=exp['features'],
n_estimators=500,
learning_rate=learning_rate,
max_depth=max_depth,
early_stopping_rounds=15,
colsample_bytree=colsample_bytree,
min_child_weight=min_child_weight,
use_scaling=exp['use_scaling'],
verbose=False,
run_name=f"Exp_{exp['name']}"
)
print(f"RMSE for {exp['name']}: {xgb_results['rmse']:.4f}")
print(f"R2 for {exp['name']}: {xgb_results['r2']:.4f}")
print(f"MAE for {exp['name']}: {xgb_results['mae']:.4f}")
experiment_results.append({
'name': exp['name'],
'num_features': len(exp['features']),
'use_scaling': exp['use_scaling'],
'rmse': xgb_results['rmse'],
'r2': xgb_results['r2'],
'mae': xgb_results['mae'],
'best_iteration': xgb_results['best_iteration'],
'mlflow_run_id': xgb_results['mlflow_run_id']
})
results_df = pd.DataFrame(experiment_results).sort_values('rmse')
print("\n--- Experiment Summary ---")
print(results_df)

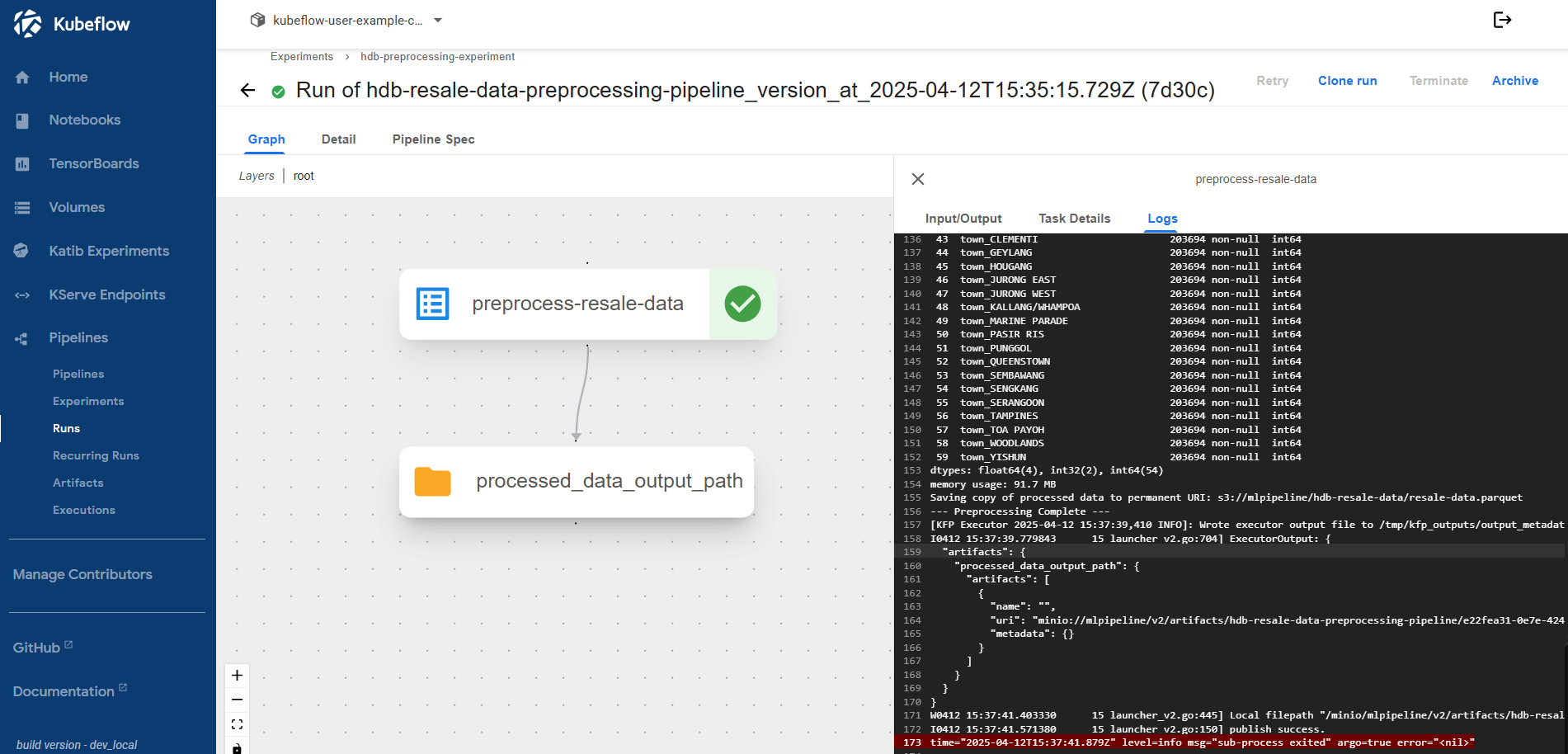
Optional - Data Preprocess Pipeline
To ensure our model receives clean and well-structured input, we’ll build a preprocessing pipeline that:
- Reads raw CSV data from MinIO
- Cleans and transforms important fields (e.g., lease years, storey ranges)
- Applies one-hot encoding on categorical variables
- Saves the output in Parquet format for downstream training
This preprocessing step is encapsulated as a Kubeflow Pipeline component.
Kubeflow pipeline - python code
import kfp
from kfp import dsl
from kfp.client import Client
from kfp.compiler import Compiler
from kfp.dsl import Input, Output, Dataset, Model, Metrics, OutputPath, InputPath
@dsl.component(
base_image='python:3.10',
packages_to_install=['pandas==2.1.4', 'numpy==1.24.4', 'scikit-learn==1.3.2', 'pyarrow==19.0.1', 's3fs']
)
def preprocess_resale_data(
raw_data_path: str,
processed_data_output_path: OutputPath("Dataset"),
permanent_output_uri: str,
):
import pandas as pd
import numpy as np
import os
print(f"--- Starting Preprocessing ---")
print(f"Raw data S3 URI: {raw_data_path}")
print(f"KFP Output Path (for artifact tracking): {processed_data_output_path}")
print(f"Permanent Output URI (for custom storage): {permanent_output_uri}")
# --- Define MinIO Connection Details ---
minio_endpoint_url = os.environ.get('AWS_ENDPOINT_URL', 'http://minio-service.kubeflow:9000')
minio_access_key = os.environ.get('AWS_ACCESS_KEY_ID', 'minio')
minio_secret_key = os.environ.get('AWS_SECRET_ACCESS_KEY', 'minio123')
s3_storage_options = {
'key': minio_access_key,
'secret': minio_secret_key,
'client_kwargs': {
'endpoint_url': minio_endpoint_url
}
}
# --- Load Data ---
df = None
try:
df = pd.read_csv(raw_data_path, skipinitialspace=True, storage_options=s3_storage_options)
print(f"Successfully loaded DataFrame using pandas+s3fs with storage_options. Shape: {df.shape}")
except FileNotFoundError:
print(f"Error: The S3 object '{raw_data_path}' was not found.")
raise
except Exception as e:
print(f"An error occurred while reading the CSV file from S3: {e}")
raise
if df is None:
raise RuntimeError("DataFrame could not be loaded.")
print("\nDataFrame Info before processing:")
df.info()
def extract_years(lease_str):
if pd.isna(lease_str): return np.nan
parts = lease_str.split()
years = 0
months = 0
for i, part in enumerate(parts):
if part.isdigit():
value = int(part)
if i + 1 < len(parts):
unit = parts[i+1].lower()
if unit.startswith('year'):
years += value
elif unit.startswith('month'):
months += value
return years + months / 12.0
def convert_storey(storey_range):
if pd.isna(storey_range): return np.nan
try:
low, high = map(int, storey_range.split(' TO '))
return (low + high) / 2.0
except Exception as e:
print(f"Warning: Could not parse storey_range: {storey_range}. Error: {e}")
return np.nan
# --- Apply Feature Engineering ---
# Remaining Lease
print("\nProcessing 'remaining_lease'...")
df['remaining_lease_years'] = df['remaining_lease'].apply(extract_years)
print(f"Min/Max remaining lease years (raw): {df['remaining_lease_years'].min()} / {df['remaining_lease_years'].max()}")
nan_count_lease = df['remaining_lease_years'].isna().sum()
print(f"NaNs in remaining lease years: {nan_count_lease}")
if nan_count_lease > 0:
median_lease = df['remaining_lease_years'].median()
print(f"Imputing {nan_count_lease} NaNs with median: {median_lease}")
df['remaining_lease_years'].fillna(median_lease, inplace=True)
# Storey Range
print("\nProcessing 'storey_range'...")
df['storey_avg'] = df['storey_range'].apply(convert_storey)
print(f"Min/Max storey avg (raw): {df['storey_avg'].min()} / {df['storey_avg'].max()}")
nan_count_storey = df['storey_avg'].isna().sum()
print(f"NaNs in storey_avg: {nan_count_storey}")
if nan_count_storey > 0:
median_storey = df['storey_avg'].median()
print(f"Imputing {nan_count_storey} NaNs with median: {median_storey}")
df['storey_avg'].fillna(median_storey, inplace=True)
# Date Features
print("\nProcessing 'month'...")
try:
df['month_dt'] = pd.to_datetime(df['month'], format='%Y-%m')
df['sale_year'] = df['month_dt'].dt.year
df['sale_month'] = df['month_dt'].dt.month
print(f"Created 'sale_year' (Min/Max): {df['sale_year'].min()} / {df['sale_year'].max()}")
print(f"Created 'sale_month' (Min/Max): {df['sale_month'].min()} / {df['sale_month'].max()}")
except Exception as e:
print(f"Error processing date column 'month': {e}")
raise
# One-Hot Encoding
categorical_cols = ['flat_type', 'flat_model', 'town']
print(f"\nApplying One-Hot Encoding to: {categorical_cols}")
valid_cat_cols = [col for col in categorical_cols if col in df.columns]
if len(valid_cat_cols) != len(categorical_cols):
print(f"Warning: Missing some categorical columns in the DataFrame. Found: {valid_cat_cols}")
df = pd.get_dummies(df, columns=valid_cat_cols, prefix=valid_cat_cols, dummy_na=False, dtype=int)
print(f"Shape after One-Hot Encoding: {df.shape}")
# --- Select Final Columns & Save ---
cols_to_drop = ['month', 'remaining_lease', 'storey_range', 'block', 'street_name', 'lease_commence_date', 'month_dt']
cols_exist_to_drop = [col for col in cols_to_drop if col in df.columns]
df.drop(columns=cols_exist_to_drop, inplace=True)
print(f"\nDropped original/intermediate columns: {cols_exist_to_drop}")
print("\nFinal columns in processed DataFrame:")
print(df.columns.tolist())
print("\nProcessed DataFrame Info:")
df.info()
print(f"\nSaving copy of processed data to permanent URI: {permanent_output_uri}")
try:
df.to_parquet(permanent_output_uri, index=False, engine='pyarrow', storage_options=s3_storage_options)
except Exception as e:
print(f"Warning: Error saving copy to permanent path {permanent_output_uri}: {e}")
raise
print(f"--- Preprocessing Complete ---")
@dsl.pipeline(name='HDB Resale Data Preprocessing Pipeline')
def hdb_preprocessing_pipeline(
raw_data_uri: str = 's3://mlpipeline/Resale flat prices based on registration date from Jan-2017 onwards.csv',
permanent_save_uri: str = 's3://mlpipeline/hdb-resale-data/resale-data.parquet'
):
preprocess_task = preprocess_resale_data(
raw_data_path=raw_data_uri,
permanent_output_uri=permanent_save_uri
)
if __name__ == '__main__':
Compiler().compile(
pipeline_func=hdb_preprocessing_pipeline,
package_path='pipeline.yaml'
)
print("Compilation complete.")
Final Thoughts
Both models demonstrate strong predictive power, though their strengths differ:
- Neural Networks are flexible and learn complex patterns but may require tuning.
- XGBoost tends to perform out-of-the-box and handles missing values and categorical splits efficiently.