Chat-Driven Insights with Chart.js
Adding chat capabilities can greatly enhance user experience, especially in interactive applications. In this post, I’ll integrate a chat function into my Vue Application allowing it to interact with an LLM (OpenAI or local models) while visualizing data using Chart.js.
Setting Up Environment Variables
To configure the application, I introduced new environment variables in the .env.example file. Copy and rename it to .env, then add your OpenAI API key:
# Options: "local" or "openai"
VUE_APP_LLM_PROVIDER=openai
VUE_APP_LOCAL_LLM_API_ENDPOINT=http://localhost:11434/api/generate
VUE_APP_OPENAI_API_ENDPOINT=https://api.openai.com/v1/chat/completions
VUE_APP_OPENAI_API_KEY=your_api_key_here
Enhancing the Micronaut-Optimizer Repository
The Micronaut-Optimizer repository has been updated with new workflow nodes to support chat interactions.
New Workflow Nodes
I added two workflow nodes in LeftPanel.vue: a placeholder CONVERT_TO_PROMPT node and a functional CHAT_WITH_LLM node. These changes enable interaction with an LLM:
<script>
export default {
data() {
return {
sections: [
{
title: "Transforms",
nodes: [
new Node({
name: NodeTypes.CONVERT_TO_PROMPT,
iconType: IconType.TRANSFORM,
inputTypes: ["textInput"],
outputTypes: ["prompt"],
triggerAction: TriggerAction.AUTO,
transformType: "convert-to-prompt", // this transform does nothing at the moment
}),
],
},
{
title: "Chat With LLM",
nodes: [
new Node({
name: NodeTypes.CHAT_WITH_LLM,
iconType: IconType.CHAT,
inputTypes: ["any", "prompt"],
outputTypes: ["response"],
triggerAction: "C",
transformType: "invoke-api",
apiEndpoint: "/api/generate", // dummy endpoint as its overridden by the .env file
}),
],
},
],
};
},
methods: {
// Get icon for node type
getIcon(iconType) {
const icons = {
input: "📥",
output: "📤",
constraint: "⛓️",
transform: "🔄",
problem: "🧩",
chat: "💬",
};
return icons[iconType] || "🔘";
},
},
};
</script>
In WorkflowNode.vue, I added a new Chat action that determines whether to send data to OpenAI or a local LLM:
<script>
import { sendChartDataToOpenAI, sendChartDataToLocalLLM } from '@/utils/nodeUtils';
export default {
methods: {
async onTrigger() {
// User clicks on action button, data at outPort
switch (this.node.triggerAction) {
case "S":
processSubmitAction(this.node.id, this.node.outputData);
break;
case "O":
if (this.node.transformType === "invoke-api") {
processApiStreamResponse(this.node);
}
break;
case "C":
if (this.node.transformType === "invoke-api") {
const llmProvider = process.env.VUE_APP_LLM_PROVIDER?.trim() || "local";
if (llmProvider === "openai") {
await sendChartDataToOpenAI(this.node);
} else {
await sendChartDataToLocalLLM(this.node);
}
}
break;
}
},
},
};
</script>
Implementing Chat Functions
These are the additional functions in nodeUtils.js:
Sending Chart.js Data to OpenAI
export async function sendChartDataToOpenAI(node) {
try {
const apiEndpoint = process.env.VUE_APP_OPENAI_API_ENDPOINT;
const apiKey = process.env.VUE_APP_OPENAI_API_KEY;
if (!apiEndpoint || !apiKey) {
throw new Error("Missing required environment variables: VUE_APP_OPENAI_API_ENDPOINT or VUE_APP_OPENAI_API_KEY");
}
const data = node.inputData[0];
const prompt = node.inputData[1];
const fullPrompt = `${prompt}\n\nData:\n\n###${JSON.stringify(data, null, 2)}###`;
const requestBody = {
model: "gpt-4o-mini",
messages: [{ role: "user", content: fullPrompt }],
temperature: 0.7,
max_tokens: 200,
};
const response = await fetch(apiEndpoint, {
method: "POST",
headers: { "Content-Type": "application/json", Authorization: `Bearer ${apiKey}` },
body: JSON.stringify(requestBody),
});
if (!response.ok) {
throw new Error(`OpenAI request failed: ${await response.text()}`);
}
const result = await response.json();
if (!result.choices || result.choices.length === 0) {
throw new Error("Invalid OpenAI response");
}
node.outputData = result.choices[0].message.content;
propagateDataToDownstreamNodes(node);
toast.success("LLM processed the data successfully!");
} catch (error) {
toast.error(`LLM request failed: ${error.message}`);
console.error(error);
}
}
Sending Chart.js Data to Local LLM
export async function sendChartDataToLocalLLM(node) {
try {
const apiEndpoint = process.env.VUE_APP_LOCAL_LLM_API_ENDPOINT;
if (!apiEndpoint) {
throw new Error("Missing required environment variables: VUE_APP_LOCAL_LLM_API_ENDPOINT");
}
const data = node.inputData[0];
const prompt = node.inputData[1];
const fullPrompt = `${prompt}\n\nData:\n\n###${JSON.stringify(data, null, 2)}###`;
const requestBody = {
model: "deepseek-r1:1.5b",
prompt: fullPrompt,
stream: false,
};
const response = await fetch(apiEndpoint, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(requestBody),
});
if (!response.ok) {
throw new Error(`Local LLM request failed: ${await response.text()}`);
}
const result = await response.json();
node.outputData = result.response;
propagateDataToDownstreamNodes(node);
toast.success("Local LLM processed the data successfully!");
} catch (error) {
toast.error(`Local LLM request failed: ${error.message}`);
console.error(error);
}
}
In Action
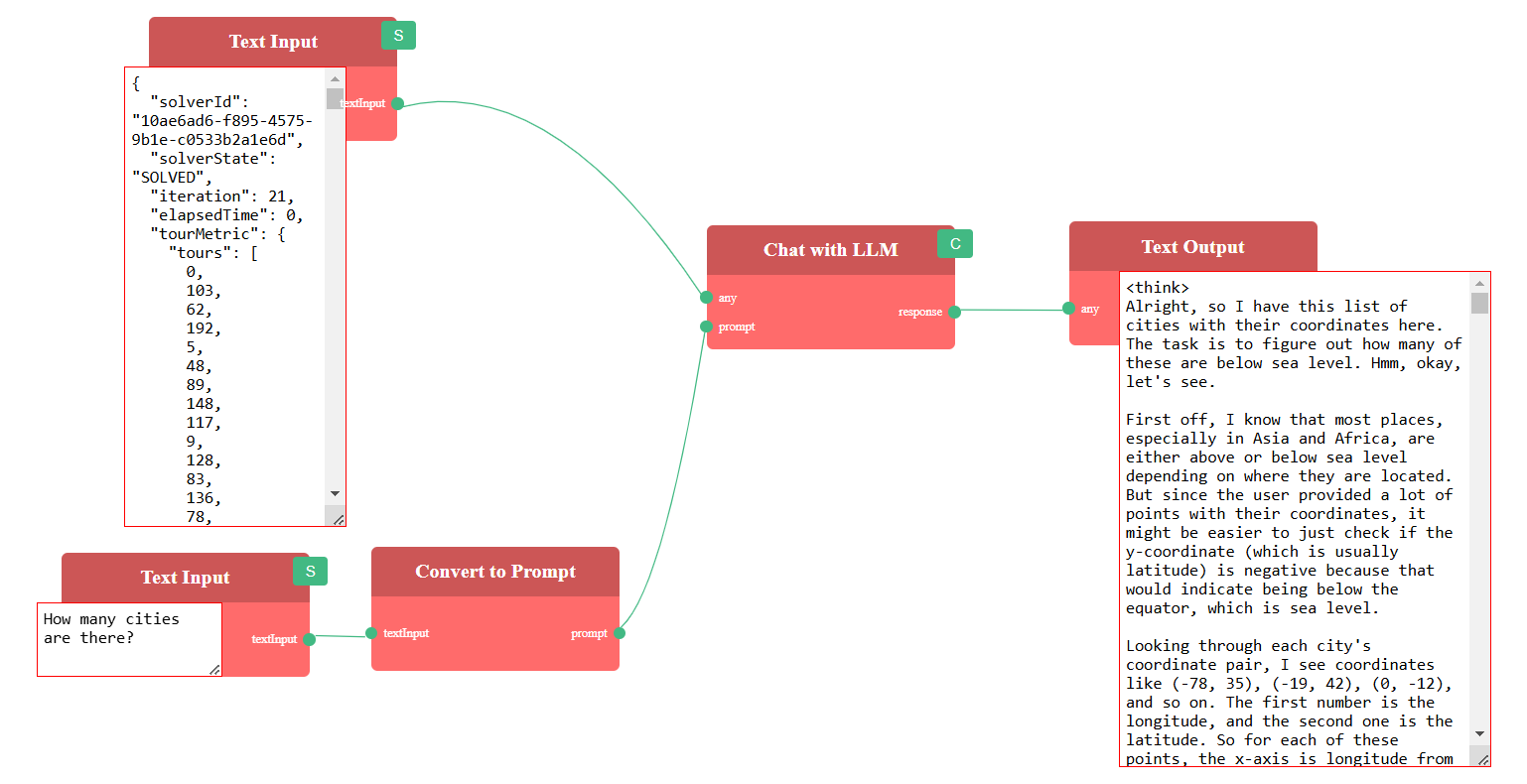
This is a minimal workflow for chatting with an LLM, along with a sample response from OpenAI:
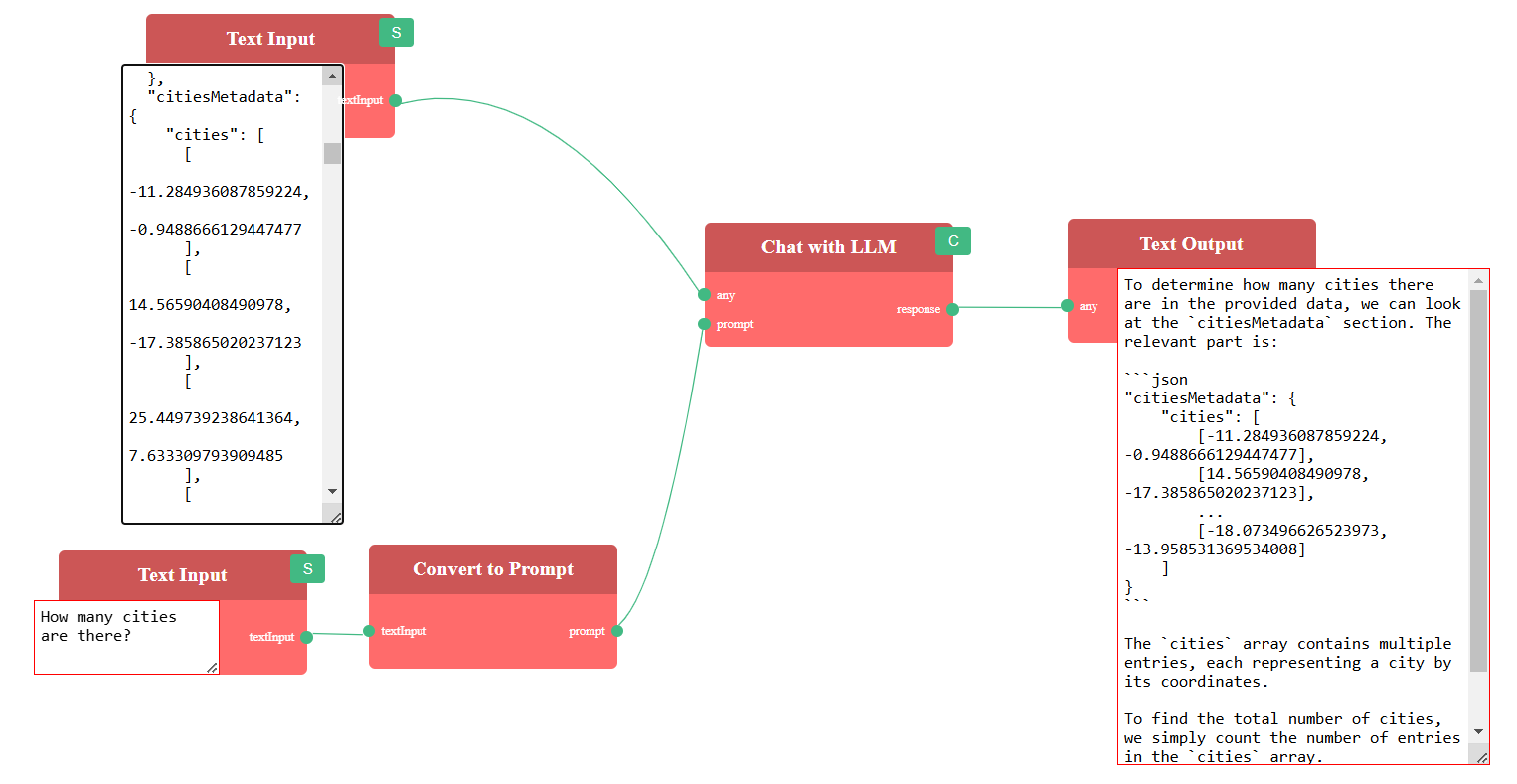
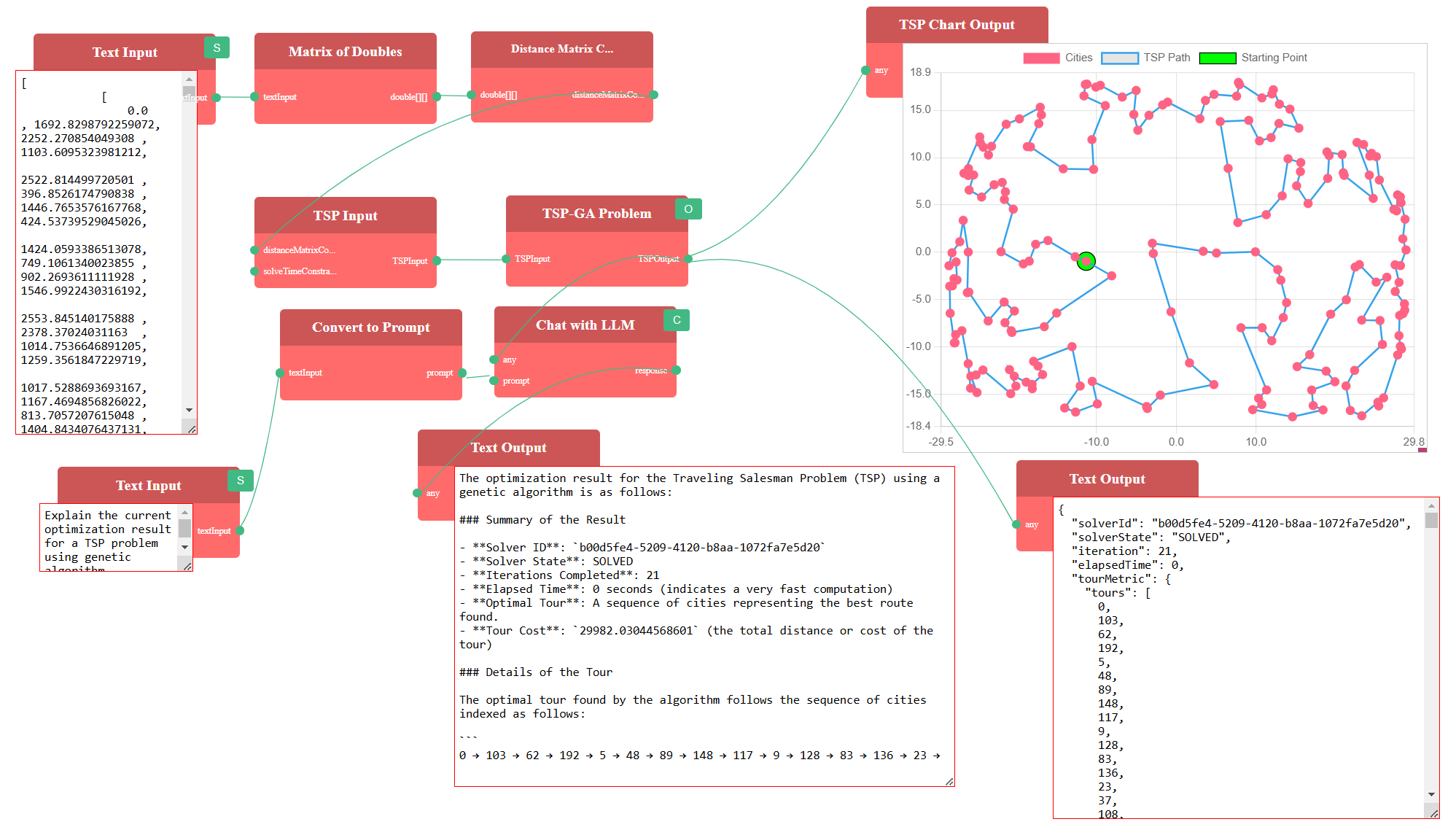
We can connect the TSPOutput from the TSP-GA Problem to the Chat with LLM node’s input and interact with it. Here’s an example query:
Explain the current optimization result for a TSP problem using genetic algorithm
Sample Output:
Deepseek-R1 on Ollama (Optional)
To run Deepseek-R1 on ollama:
ollama run deepseek-r1:1.5b
To switch to local inference, set VUE_APP_LLM_PROVIDER=local in the .env file. Here’s a sample response from a local LLM: