Building a Recommender System
As I continue the Unsupervised Learning, Recommenders, and Reinforcement Learning course — which combines theory with hands-on labs — I’m applying what I learn to solidify my understanding. This post walks through building a movie recommender system using the MovieLens dataset. From data loading and feature engineering to generating embeddings and performing similarity search with pgvector in PostgreSQL, the goal is to bring the course material to life through a practical, end-to-end example. The dataset is based on The MovieLens Datasets: History and Context.
Environment Setup
PostgreSQL Installation
I installed the Bitnami PostgreSQL Helm chart in my homelab environment:
helm install my-release oci://registry-1.docker.io/bitnamicharts/postgresql
# To get password
export POSTGRES_PASSWORD=$(kubectl get secret --namespace postgres postgres-postgresql -o jsonpath="{.data.postgres-password}" | base64 -d)
echo $POSTGRES_PASSWORD
Database Schema Preparation
Here’s the schema I created for storing movie-related data and embeddings. I also enabled the vector extension for future use in vector-based operations.
-- Create schema and enable vector extension
CREATE SCHEMA IF NOT EXISTS movie_recommender;
CREATE EXTENSION IF NOT EXISTS vector;
-- Drop tables if they exist (clean start)
DROP TABLE IF EXISTS movie_recommender.movie_embeddings;
DROP TABLE IF EXISTS movie_recommender.ratings;
DROP TABLE IF EXISTS movie_recommender.links;
DROP TABLE IF EXISTS movie_recommender.tags;
DROP TABLE IF EXISTS movie_recommender.movies;
-- Define core tables
CREATE TABLE movie_recommender.movies (
movieId INT PRIMARY KEY,
title VARCHAR(255),
genres VARCHAR(255)
);
CREATE TABLE movie_recommender.ratings (
userId INT,
movieId INT,
rating FLOAT,
timestamp BIGINT,
PRIMARY KEY (userId, movieId),
FOREIGN KEY (movieId) REFERENCES movie_recommender.movies(movieId)
);
CREATE TABLE movie_recommender.links (
movieId INT PRIMARY KEY,
imdbId VARCHAR(20),
tmdbId INT,
FOREIGN KEY (movieId) REFERENCES movie_recommender.movies(movieId)
);
CREATE TABLE movie_recommender.tags (
userId INT,
movieId INT,
tag VARCHAR(255),
timestamp BIGINT,
FOREIGN KEY (movieId) REFERENCES movie_recommender.movies(movieId)
);
-- Embeddings table
CREATE TABLE movie_recommender.movie_embeddings (
movieid INT NOT NULL,
embedding public.vector NULL,
CONSTRAINT movie_embeddings_pkey PRIMARY KEY (movieid),
FOREIGN KEY (movieid) REFERENCES movie_recommender.movies(movieId)
);
Load Data from CSV
1. Database Configuration in Jupyter
Note: For production, consider using environment variables or a secrets manager for credentials.
# File paths
ratings_file = 'ratings.csv'
movies_file = 'movies.csv'
links_file = 'links.csv'
tags_file = 'tags.csv'
# Database credentials
db_params = {
'database': 'postgres',
'user': 'postgres',
'password': 'W8oMlEyhq9',
'host': 'postgres-postgresql.postgres',
'port': '5432'
}
target_schema = "movie_recommender"
2. Writing CSV to PostgreSQL
import psycopg2
# Function to bulk copy data
def copy_data_to_postgres(csv_path, schema_name, table_name, columns, connection):
qualified_table_name = f"{schema_name}.{table_name}"
try:
with open(csv_path, 'r', encoding='utf-8') as f:
next(f)
cursor = connection.cursor()
copy_sql = f"COPY {qualified_table_name} ({','.join(columns)}) FROM STDIN WITH (FORMAT CSV, DELIMITER ',', HEADER FALSE)"
print(f"Attempting to copy data to {qualified_table_name}...")
cursor.copy_expert(sql=copy_sql, file=f)
connection.commit()
print(f"Successfully copied data from {csv_path} to {qualified_table_name}")
except (Exception, psycopg2.DatabaseError) as error:
print(f"Error copying data to {qualified_table_name}: {error}")
connection.rollback()
finally:
if cursor:
cursor.close()
# Establish DB connection
conn = None
try:
print(f"Attempting to connect to PostgreSQL database '{db_params['database']}' on {db_params['host']}...")
conn = psycopg2.connect(**db_params)
print("PostgreSQL connection successful.")
# Copy datasets
print(f"\n-- Copying data into tables in schema '{target_schema}' --")
movies_cols = ['movieId', 'title', 'genres']
links_cols = ['movieId', 'imdbId', 'tmdbId']
ratings_cols = ['userId', 'movieId', 'rating', 'timestamp']
tags_cols = ['userId', 'movieId', 'tag', 'timestamp']
copy_data_to_postgres(movies_file, target_schema, 'movies', movies_cols, conn)
copy_data_to_postgres(links_file, target_schema, 'links', links_cols, conn)
copy_data_to_postgres(ratings_file, target_schema, 'ratings', ratings_cols, conn)
copy_data_to_postgres(tags_file, target_schema, 'tags', tags_cols, conn)
except Exception as e:
print(f"Unexpected DB error: {e}")
if conn:
conn.rollback()
finally:
if conn:
conn.close()
print("DB connection closed.")
Load Data from PostgreSQL
Now let’s read the ingested data back into Pandas for inspection and processing.
import pandas as pd
from sqlalchemy import create_engine, text
# Setup SQLAlchemy engine
db_url = f"postgresql+psycopg2://{db_params['user']}:{db_params['password']}@{db_params['host']}:{db_params['port']}/{db_params['database']}"
engine = create_engine(db_url)
# Load data
query_ratings = text(f'SELECT userid, movieid, rating FROM {target_schema}.ratings')
ratings_df = pd.read_sql(query_ratings, engine)
query_movies = text(f'SELECT movieid, title, genres FROM {target_schema}.movies')
movies_df = pd.read_sql(query_movies, engine)
pd.set_option('display.width', 200)
print(f"Loaded {len(ratings_df)} ratings and {len(movies_df)} movies.")
print(ratings_df.head())
print(movies_df.head())
engine.dispose()
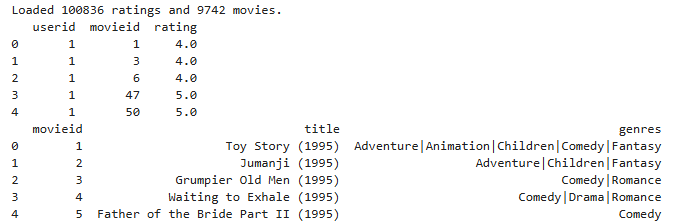
Feature Engineering
Movie Features
We’ll perform the following preprocessing steps:
- Extract year from the movie title
- One-hot encode genres
- Calculate the average rating per movie
from sklearn.preprocessing import MultiLabelBinarizer
import re
# Extract Year
movies_df['year'] = movies_df['title'].str.extract(r'\((\d{4})\)', expand=False)
movies_df['year'] = pd.to_numeric(movies_df['year'], errors='coerce')
median_year = movies_df['year'].median()
movies_df['year'] = movies_df['year'].fillna(median_year).astype(int)
# Drop entries with no genres
movies_df = movies_df[movies_df['genres'] != '(no genres listed)'].copy()
# One-hot encode genres
movies_df['genres_list'] = movies_df['genres'].str.split('|')
mlb = MultiLabelBinarizer()
genre_df = pd.DataFrame(
mlb.fit_transform(movies_df['genres_list']),
columns=mlb.classes_,
index=movies_df.index
)
# Compute average rating
movie_avg_ratings = ratings_df.groupby('movieid')['rating'].mean().reset_index()
movie_avg_ratings.rename(columns={'rating': 'movie_avg_rating'}, inplace=True)
# Final item feature dataframe
item_features_df = movies_df[['movieid', 'year']].join(genre_df)
item_features_df = pd.merge(item_features_df, movie_avg_ratings, on='movieid', how='left')
item_features_df['movie_avg_rating'] = item_features_df['movie_avg_rating'].fillna(ratings_df['rating'].mean())
print(item_features_df.head(2))
# Sample Output
# movieid year Action Adventure Animation Children Comedy Crime Documentary Drama ... Horror IMAX Musical Mystery Romance Sci-Fi Thriller War Western movie_avg_rating
# 0 1 1995 0 1 1 1 1 0 0 0 ... 0 0 0 0 0 0 0 0 0 3.920930
# 1 2 1995 0 1 0 1 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 3.431818
# [2 rows x 22 columns]
User Features
Now that we’ve engineered item-level features, let’s shift our focus to the users. A personalized recommendation system must understand user preferences—and what better way to do that than by analyzing how users rate movies across different genres?
# Mapping Users to Genres
print("Merging ratings with genres...")
genre_cols = list(mlb.classes_)
item_genres_for_merge = item_features_df[['movieid'] + genre_cols].copy()
ratings_with_genres = pd.merge(
ratings_df[['userid', 'movieid', 'rating']],
item_genres_for_merge,
on='movieid',
how='inner'
)
print(f"Shape after merging ratings with genres: {ratings_with_genres.shape}")
# Reshaping Data for Aggregation
print("Melting genre data...")
melted_genres = ratings_with_genres.melt(
id_vars=['userid', 'rating'],
value_vars=genre_cols,
var_name='genre',
value_name='has_genre'
)
print(f"Shape after melting: {melted_genres.shape}")
# Filtering Valid Genre Associations
user_genre_ratings = melted_genres[melted_genres['has_genre'] == 1].copy()
print(f"Shape after filtering for has_genre=1: {user_genre_ratings.shape}")
# Computing Genre-Based Averages Per User
print("Calculating average rating per user per genre...")
user_genre_avg_ratings = user_genre_ratings.groupby(['userid', 'genre'])['rating'].mean().reset_index()
print(f"Shape after grouping user/genre: {user_genre_avg_ratings.shape}")
# Pivoting to a Feature Matrix
print("Pivoting table...")
user_genre_features_df = user_genre_avg_ratings.pivot(index='userid', columns='genre', values='rating')
print(user_genre_features_df.head(2))
# Rename columns for clarity
user_genre_feature_cols = [f'genre_avg_{col}' for col in user_genre_features_df.columns]
user_genre_features_df.columns = user_genre_feature_cols
print(f"Created {len(user_genre_feature_cols)} user-genre average features.")
# Sample Output
# Merging ratings with genres...
# Shape after merging ratings with genres: (100789, 22)
# Melting genre data...
# Shape after melting: (1914991, 4)
# Shape after filtering for has_genre=1: (274433, 4)
# Calculating average rating per user per genre...
# Shape after grouping user/genre: (10001, 3)
# Pivoting table...
# genre Action Adventure Animation Children Comedy Crime Documentary Drama Fantasy Film-Noir Horror IMAX Musical Mystery Romance Sci-Fi Thriller War Western
# userid
# 1 4.322222 4.388235 4.689655 4.547619 4.277108 4.355556 NaN 4.529412 4.297872 5.0 3.470588 NaN 4.681818 4.166667 4.307692 4.225 4.145455 4.5 4.285714
# 2 3.954545 4.166667 NaN NaN 4.000000 3.800000 4.333333 3.882353 NaN NaN 3.000000 3.75 NaN 4.000000 4.500000 3.875 3.700000 4.5 3.500000
# Created 19 user-genre average features.
Final Feature Assembly
With both item-level and user-level features constructed, we now assemble the final dataset that will feed into our model.
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.model_selection import train_test_split
# Start with the original ratings data (userid, movieid, rating)
ratings_with_features = ratings_df[['userid', 'movieid', 'rating']].copy()
# Merge item features
cols_to_merge_item = ['movieid', 'year', 'movie_avg_rating'] + genre_cols
ratings_with_features = pd.merge(
ratings_with_features,
item_features_df[cols_to_merge_item],
on='movieid',
how='inner'
)
print(f"Shape after merging item features: {ratings_with_features.shape}")
# Merge user features
ratings_with_features = pd.merge(
ratings_with_features,
user_genre_features_df,
on='userid',
how='inner'
)
ratings_with_features.dropna(inplace=True)
print(f"Shape after merging user features: {ratings_with_features.shape}")
# Feature splitting
item_feature_cols = ['year', 'movie_avg_rating'] + genre_cols
X_user_features = ratings_with_features[user_genre_feature_cols]
X_item_features = ratings_with_features[item_feature_cols]
y_target = ratings_with_features['rating']
print(f"\nUser feature matrix shape (before split): {X_user_features.shape}")
print(f"Item feature matrix shape (before split): {X_item_features.shape}")
print(f"Target vector shape (before split): {y_target.shape}")
# Train-Test split
X_user_train_unscaled, X_user_test_unscaled, X_item_train_unscaled, X_item_test_unscaled, y_train_unscaled, y_test_unscaled = train_test_split(
X_user_features, X_item_features, y_target,
test_size=0.2,
random_state=42
)
print(f"\nTraining shapes (before scaling): User={X_user_train_unscaled.shape}, Item={X_item_train_unscaled.shape}, Target={y_train_unscaled.shape}")
print(f"Testing shapes (before scaling): User={X_user_test_unscaled.shape}, Item={X_item_test_unscaled.shape}, Target={y_test_unscaled.shape}")
# Feature scaling
scalerUser = StandardScaler()
user_train = scalerUser.fit_transform(X_user_train_unscaled)
user_test = scalerUser.transform(X_user_test_unscaled)
print(f"\nScaled user features matrix. Train shape: {user_train.shape}, Test shape: {user_test.shape}")
scalerItem = StandardScaler()
item_train = scalerItem.fit_transform(X_item_train_unscaled)
item_test = scalerItem.transform(X_item_test_unscaled)
print(f"Scaled item features matrix. Train shape: {item_train.shape}, Test shape: {item_test.shape}")
scalerTarget = MinMaxScaler((-1, 1))
y_train = scalerTarget.fit_transform(y_train_unscaled.values.reshape(-1, 1))
y_test = scalerTarget.transform(y_test_unscaled.values.reshape(-1, 1))
print(f"Scaled target variable (y). Train shape: {y_train.shape}, Test shape: {y_test.shape}")
num_user_features = user_train.shape[1]
num_item_features = item_train.shape[1]
# Final dataset shapes
print(f"\nuser_train: {user_train.shape}")
print(f"item_train: {item_train.shape}")
print(f"y_train: {y_train.shape}")
# Sample Output
# Shape after merging item features: (100789, 24)
# Shape after merging user features: (53434, 43)
# User feature matrix shape (before split): (53434, 19)
# Item feature matrix shape (before split): (53434, 21)
# Target vector shape (before split): (53434,)
# Training shapes (before scaling): User=(42747, 19), Item=(42747, 21), Target=(42747,)
# Testing shapes (before scaling): User=(10687, 19), Item=(10687, 21), Target=(10687,)
# Scaled user features matrix. Train shape: (42747, 19), Test shape: (10687, 19)
# Scaled item features matrix. Train shape: (42747, 21), Test shape: (10687, 21)
# Scaled target variable (y). Train shape: (42747, 1), Test shape: (10687, 1)
# user_train: (42747, 19)
# item_train: (42747, 21)
# y_train: (42747, 1)
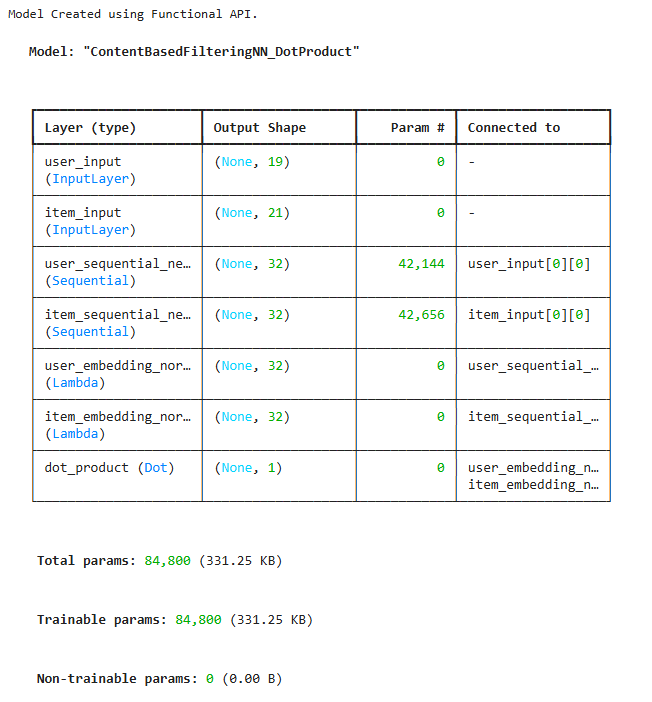
Define the Model
Following the course lab, we design a content-based filtering neural network using the Keras Functional API. The model learns user and item embeddings from their respective features and uses the dot product to compute similarity between them.
import tensorflow as tf
from tensorflow import keras
# Set a fixed seed for reproducibility
tf.random.set_seed(1)
# Define the size of the final embedding space
num_outputs = 32
# Define the user sub-network
user_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation='relu', name='user_dense_1'),
tf.keras.layers.Dense(128, activation='relu', name='user_dense_2'),
tf.keras.layers.Dense(num_outputs, name='user_embedding_output'),
], name='user_sequential_network')
# Define the item sub-network
item_NN = tf.keras.models.Sequential([
tf.keras.layers.Dense(256, activation='relu', name='item_dense_1'),
tf.keras.layers.Dense(128, activation='relu', name='item_dense_2'),
tf.keras.layers.Dense(num_outputs, name='item_embedding_output'),
], name='item_sequential_network')
# User input and embedding pipeline
input_user = tf.keras.layers.Input(shape=(num_user_features,), name='user_input')
vu = user_NN(input_user)
vu_normalized = tf.keras.layers.Lambda(lambda x: tf.linalg.l2_normalize(x, axis=1), name='user_embedding_normalized')(vu)
# Item input and embedding pipeline
input_item = tf.keras.layers.Input(shape=(num_item_features,), name='item_input')
vm = item_NN(input_item)
vm_normalized = tf.keras.layers.Lambda(lambda x: tf.linalg.l2_normalize(x, axis=1), name='item_embedding_normalized')(vm)
# Compute similarity using dot product
dot_product = tf.keras.layers.Dot(axes=1, name='dot_product')([vu_normalized, vm_normalized])
# Define the full model
model = tf.keras.Model(inputs=[input_user, input_item], outputs=dot_product, name='ContentBasedFilteringNN_DotProduct')
print("Model Created using Functional API.")
model.summary()
Compile the Model
We compile the model using the Mean Squared Error (MSE) loss function and the Adam optimizer, suitable for learning continuous similarity scores.
print("\nCompiling Model...")
tf.random.set_seed(1)
cost_fn = tf.keras.losses.MeanSquaredError()
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(optimizer=opt, loss=cost_fn)
print("Model Compiled.")
Train the Model
We now train the model using model.fit(), passing in both user and item features as inputs and the target similarity scores (y_train) as labels.
print("Starting Model Training...")
# Define training parameters
EPOCHS = 30
tf.random.set_seed(1)
history = model.fit(
x=[user_train, item_train], # Inputs: user and item features
y=y_train, # Target: similarity score (e.g., scaled rating)
epochs=EPOCHS,
verbose=1
)
print("Model Training Complete.")

Evaluate the Model
Finally, we evaluate the model on a separate test dataset and compute both the MSE and RMSE for interpretability.
import numpy as np
print(f"\n-- Evaluating the Model on SCALED Test Data --")
test_loss = model.evaluate([user_test, item_test], y_test, verbose=1)
# Compute RMSE for easier interpretation
test_rmse = np.sqrt(test_loss)
print(f"\nTest Loss (MSE on scaled data): {test_loss:.4f}")
print(f"Test RMSE (calculated from MSE): {test_rmse:.4f}")
# Sample Output
# -- Evaluating the Model on SCALED Test Data --
# 334/334 ━━━━━━━━━━━━━━━━━━━━ 0s 728us/step - loss: 0.1056
# Test Loss (MSE on scaled data): 0.1052
# Test RMSE (calculated from MSE): 0.3244
Predicting Ratings for an Existing User
This section walks through how we generate personalized movie recommendations for a specific user using our trained neural network model.
We apply the following process:
- Find unrated movies for the selected user.
- Prepare the feature vectors for both the user and unrated items.
- Make predictions using the scaled input features.
- Rescale the predictions to match the original rating scale.
- Display recommendations sorted by predicted rating and popularity.
- Evaluate prediction performance for items the user has already rated.
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
def predict_and_display_for_user(uid, model, user_features_df, item_features_df,
ratings_df, movies_df, scalerUser, scalerItem,
scalerTarget, maxcount=15):
# Fetch all ratings made by this user
user_actuals = ratings_df[ratings_df['userid'] == uid]
# Identify movies not yet rated by the user
unrated_movies = item_features_df[~item_features_df['movieid'].isin(user_actuals['movieid'])]
if len(unrated_movies) == 0:
print(f"User {uid} has rated all available movies.")
return
# Repeat the user's feature vector to match the unrated movie count
user_vec = user_features_df[user_features_df['userid'] == uid][scalerUser.feature_names_in_]
user_vecs = pd.concat([user_vec] * len(unrated_movies), ignore_index=True)
# Scale both user and item feature vectors
suser_vecs = scalerUser.transform(user_vecs)
sitem_vecs = scalerItem.transform(unrated_movies[scalerItem.feature_names_in_])
# Predict scaled ratings, then inverse transform to original scale
scaled_preds = model.predict([suser_vecs, sitem_vecs])
predictions = scalerTarget.inverse_transform(scaled_preds).flatten()
# Build result DataFrame
results = pd.DataFrame({
'movieid': unrated_movies['movieid'],
'predicted_raw': predictions,
'title': unrated_movies['movieid'].map(dict(zip(movies_df['movieid'], movies_df['title'])))
})
# Join with movie rating stats
movie_stats = ratings_df.groupby('movieid').agg(
avg_rating=('rating', 'mean'),
rating_count=('rating', 'count')
)
results = results.merge(movie_stats, on='movieid', how='left')
# Clip predictions to valid rating range
results['predicted'] = np.clip(results['predicted'], 0.5, 5.0)
# Filter by movies with enough votes and sort
results = results[
(results['rating_count'] >= 10)
].sort_values(
by=['predicted', 'rating_count'],
ascending=[False, False]
).head(maxcount)
# Print the final top-N recommendations
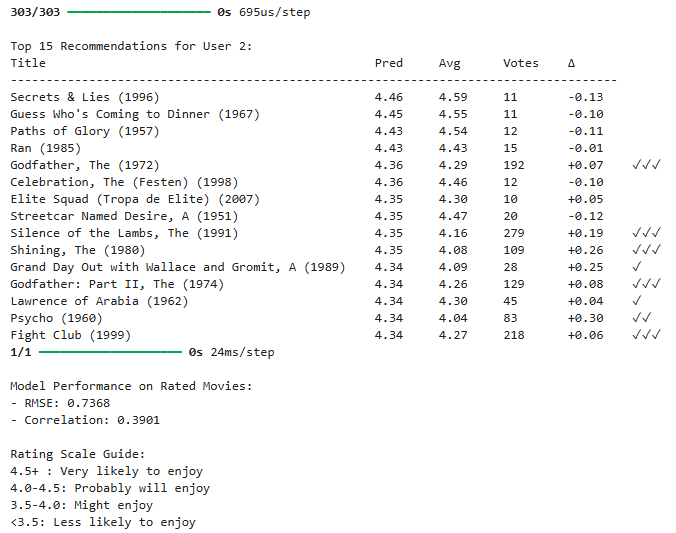
print(f"\nTop {maxcount} Recommendations for User {uid}:")
print("{:<50} {:<8} {:<8} {:<8} {:<10}".format(
"Title", "Pred", "Avg", "Votes", "Δ"))
print("-"*85)
for _, row in results.iterrows():
delta = row['predicted'] - row['avg_rating']
reliability = ""
if row['rating_count'] > 100:
reliability = "✓✓✓"
elif row['rating_count'] > 50:
reliability = "✓✓"
elif row['rating_count'] > 20:
reliability = "✓"
print("{:<50} {:<8.2f} {:<8.2f} {:<8} {:<+8.2f} {}".format(
row['title'][:48],
row['predicted'],
row['avg_rating'],
int(row['rating_count']),
delta,
reliability))
Evaluating Predictions on Previously Rated Movies
We also assess how well the model performs by comparing predictions against the user’s actual ratings:
rated_predictions = get_rated_predictions(
uid, model, user_features_df, item_features_df,
ratings_df, scalerUser, scalerItem, scalerTarget
)
if not rated_predictions.empty:
mse = ((rated_predictions['predicted'] - rated_predictions['actual'])**2).mean()
print("\nModel Performance on Rated Movies:")
print(f"- RMSE: {np.sqrt(mse):.4f}")
print(f"- Correlation: {rated_predictions['predicted'].corr(rated_predictions['actual']):.4f}")
print("\nRating Scale Guide:")
print("4.5+ : Very likely to enjoy")
print("4.0–4.5 : Probably will enjoy")
print("3.5–4.0 : Might enjoy")
print("<3.5 : Less likely to enjoy")
Supporting Function - get_rated_predictions()
This helper function returns model predictions for items the user has already rated, so we can compare against ground truth.
def get_rated_predictions(uid, model, user_features_df, item_features_df,
ratings_df, scalerUser, scalerItem, scalerTarget):
user_ratings = ratings_df[ratings_df['userid'] == uid]
rated_items = item_features_df[item_features_df['movieid'].isin(user_ratings['movieid'])]
if len(rated_items) == 0:
return pd.DataFrame()
user_vec = user_features_df[user_features_df['userid'] == uid][scalerUser.feature_names_in_]
user_vecs = pd.concat([user_vec] * len(rated_items), ignore_index=True)
suser_vecs = scalerUser.transform(user_vecs)
sitem_vecs = scalerItem.transform(rated_items[scalerItem.feature_names_in_])
scaled_preds = model.predict([suser_vecs, sitem_vecs])
predictions = scalerTarget.inverse_transform(scaled_preds).flatten()
return pd.DataFrame({
'movieid': rated_items['movieid'].values,
'actual': user_ratings['rating'].values,
'predicted': predictions
})
Example Output
Let’s test this by generating recommendations for User 2:
user_genre_features_df = user_genre_features_df.reset_index()
assert 'userid' in user_genre_features_df.columns
predict_and_display_for_user(
uid=2,
model=model,
user_features_df=user_genre_features_df,
item_features_df=item_features_df,
ratings_df=ratings_df,
movies_df=movies_df,
scalerUser=scalerUser,
scalerItem=scalerItem,
scalerTarget=scalerTarget,
maxcount=15
)
PgVector: Embedding-Based Movie Recommendations
1. Insert Embedding
To enable similarity search with pgvector, we first generate embeddings using a previously trained model. These embeddings are then stored in a PostgreSQL table with the vector extension enabled.
The following VectorRecommender class handles embedding generation, storage, and querying for similar items and personalized recommendations:
import numpy as np
import pandas as pd
import psycopg2
from psycopg2.extras import execute_values
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sqlalchemy import create_engine, text
import tensorflow as tf
from tqdm import tqdm
class VectorRecommender:
def __init__(self, db_config, target_schema="movie_recommender"):
self.db_config = db_config
self.target_schema = target_schema
self.embedding_table = "movie_embeddings"
self.engine = None
self.embedding_dim = None
self._initialize_connection()
def _initialize_connection(self):
try:
self.engine = create_engine(
f"postgresql+psycopg2://{self.db_config['user']}:{self.db_config['password']}@"
f"{self.db_config['host']}:{self.db_config['port']}/{self.db_config['database']}"
)
with self.engine.connect() as conn:
conn.execute(text("SELECT 1"))
print("Database connection established")
return True
except Exception as e:
print(f"Connection failed: {e}")
self.engine = None
return False
def setup_embeddings(self, model, item_features_df, scalerItem):
try:
item_nn = model.get_layer('item_sequential_network')
input_item = tf.keras.layers.Input(shape=(item_features_df.shape[1]-1,))
vm = item_nn(input_item)
vm = tf.keras.layers.Lambda(lambda x: tf.linalg.l2_normalize(x, axis=1))(vm)
embedding_model = tf.keras.Model(inputs=input_item, outputs=vm)
item_features = item_features_df.iloc[:, 1:].values
scaled_features = scalerItem.transform(item_features)
embeddings = embedding_model.predict(scaled_features, batch_size=512, verbose=1)
self.embedding_dim = embeddings.shape[1]
movie_ids = item_features_df['movieid'].values
self._store_embeddings(movie_ids, embeddings)
return True
except Exception as e:
print(f"Embedding setup failed: {e}")
return False
def _store_embeddings(self, movie_ids, embeddings):
data = [(int(mid), [float(x) for x in emb])
for mid, emb in zip(movie_ids, embeddings)]
with psycopg2.connect(**self.db_config) as conn:
with conn.cursor() as cursor:
print(f"Storing {len(data)} embeddings...")
execute_values(
cursor,
f"""
INSERT INTO {self.target_schema}.{self.embedding_table} (movieid, embedding)
VALUES %s
ON CONFLICT (movieid) DO UPDATE
SET embedding = EXCLUDED.embedding;
""",
data,
page_size=500
)
conn.commit()
print("Embeddings stored successfully")
def get_similar_movies(self, movie_id, top_n=5):
with self.engine.connect() as conn:
result = conn.execute(text(f"""
SELECT m.movieid, m.title, m.genres,
e.embedding <-> (SELECT embedding FROM {self.target_schema}.{self.embedding_table}
WHERE movieid = :movie_id) AS distance
FROM {self.target_schema}.{self.embedding_table} e
JOIN {self.target_schema}.movies m ON e.movieid = m.movieid
WHERE e.movieid != :movie_id
ORDER BY distance ASC
LIMIT :top_n;
"""), {'movie_id': movie_id, 'top_n': top_n})
return result.fetchall()
def get_user_recommendations(self, user_id, top_n=10):
with self.engine.connect() as conn:
top_rated = conn.execute(text(f"""
SELECT movieid FROM {self.target_schema}.ratings
WHERE userid = :user_id
ORDER BY rating DESC
LIMIT 3;
"""), {'user_id': user_id}).fetchall()
if not top_rated:
return None
recommendations = []
for (movie_id,) in top_rated:
similar = self.get_similar_movies(movie_id, top_n)
recommendations.extend(similar)
recs_formatted = []
for rec in recommendations:
recs_formatted.append({
'movieid': rec.movieid,
'title': rec.title,
'genres': rec.genres,
'distance': rec.distance
})
# Deduplicate by closest distance
unique_recs = {}
for rec in recs_formatted:
if rec['movieid'] not in unique_recs or rec['distance'] < unique_recs[rec['movieid']]['distance']:
unique_recs[rec['movieid']] = rec
return sorted(unique_recs.values(), key=lambda x: x['distance'])[:top_n]
Example Usage:
# Database configuration
db_config = {
'database': 'postgres',
'user': 'postgres',
'password': 'W8oMlEyhq9',
'host': 'postgres-postgresql.postgres',
'port': '5432'
}
# Initialize recommender
recommender = VectorRecommender(db_config)
# Run only once to populate the embeddings
if False:
if not recommender.setup_embeddings(model, item_features_df, scalerItem):
print("Failed to setup embeddings")
# Get personalized recommendations
user_id = 2
print(f"\nRecommendations for user {user_id}:")
recs = recommender.get_user_recommendations(user_id)
if recs:
for rec in recs:
print(f"- {rec['title']} ({rec['genres']}) [similarity: {rec['distance']:.3f}]")
else:
print("No recommendations found")

2. Finding Similar Items
Once embeddings are stored in PostgreSQL with pgvector, you can quickly find similar items using the <-> operator for cosine distance:
# Find similar movies
movie_id = 1 # Toy Story
print(f"\nMovies similar to ID {movie_id}:")
similar = recommender.get_similar_movies(movie_id)
if similar:
for movie in similar:
print(f"- {movie.title} ({movie.genres}) [distance: {movie.distance:.3f}]")
else:
print("No similar movies found")
