Navigating through the NVIDIA Jetson AI Lab has been an exhilarating experience, showcasing the potential of generative AI powered by NVIDIA® Jetson™. With a plethora of labs to explore, it’s challenging to cover everything in a limited time. In this post, I’ll focus on labs related to text generation.
Preparation
If you follow my Jetson Orin NX flashing guide, you might have noticed that a browser is not pre-installed. I recommend installing Brave, a browser that blocks ads and conserves data. To install it, simply run:
sudo snap install brave
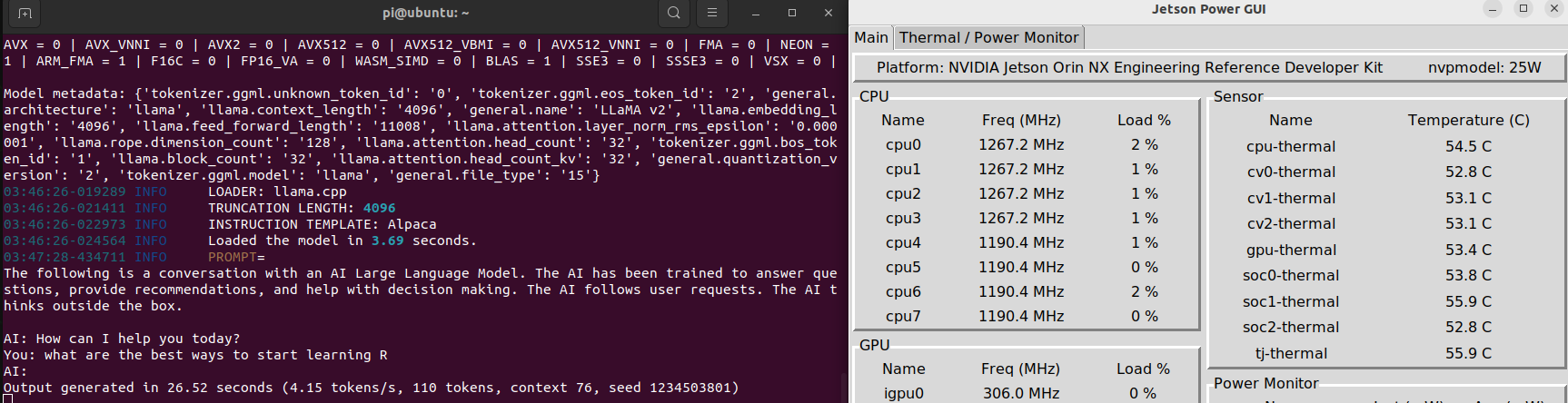
When running nvidia-smi, you might expect to see a GPU listed, but instead, you’ll find none. This is because the Jetson devices use an integrated GPU (iGPU) that connects directly to the memory controller. For monitoring GPU usage, I recommend using the built-in Jetson Power GUI.
Text Generation - WebUI
Following the guide on text-generation-webui, clone the repository to utilize the utilities that will automatically pull and start the appropriate container:
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
jetson-containers run $(autotag text-generation-webui)
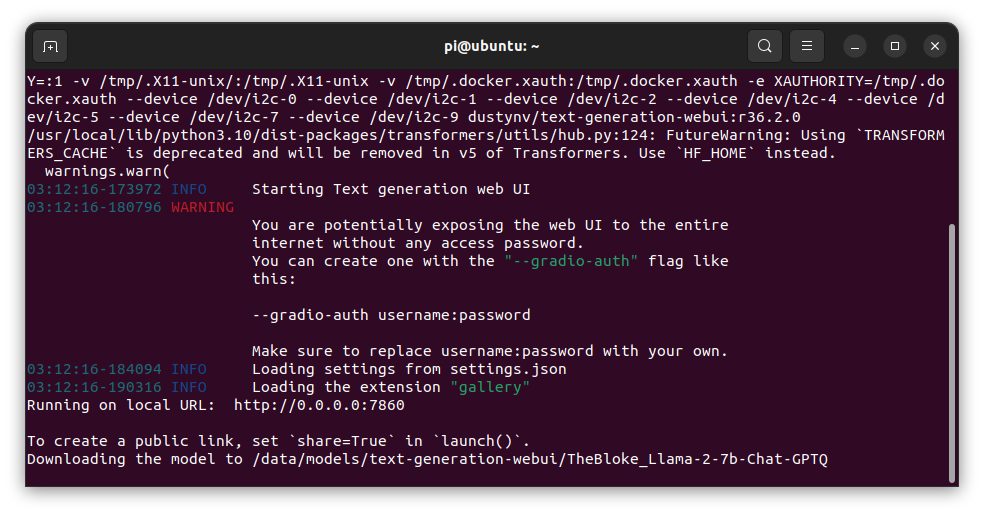
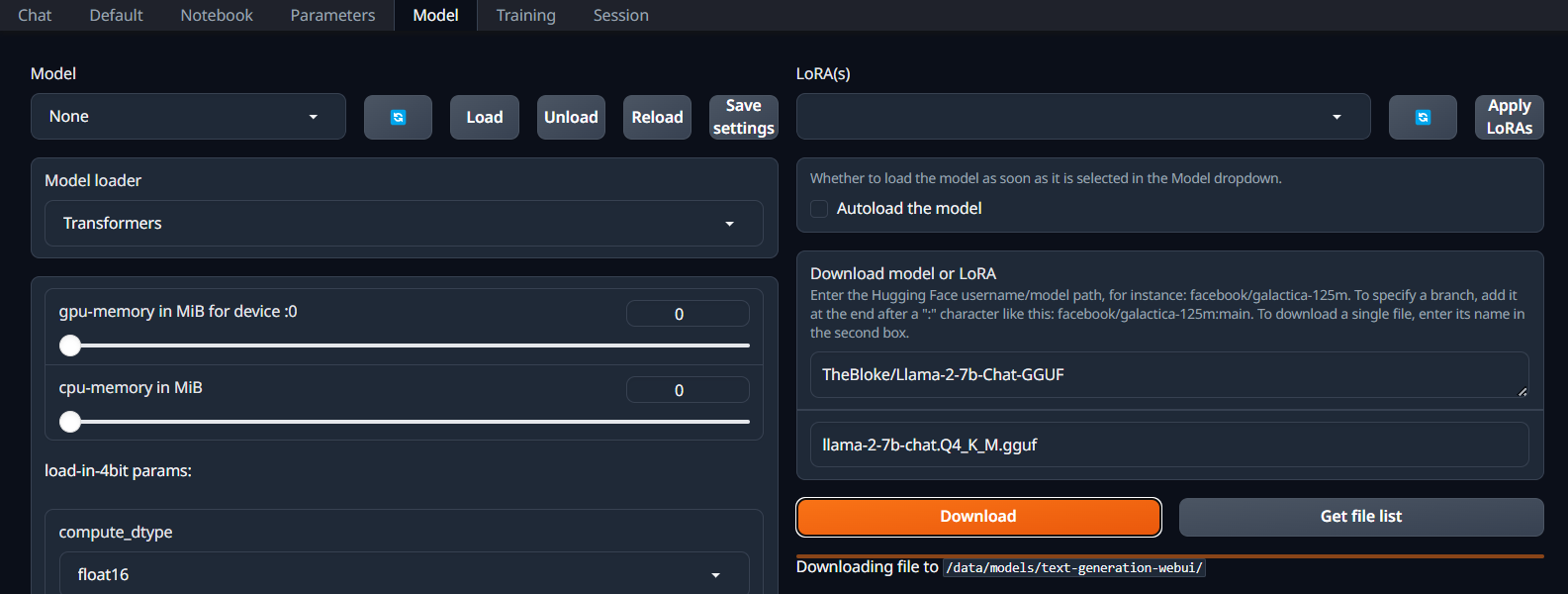
LLama-2-7b-Chat-GGUF
To start, I used TheBloke/Llama-2-7b-Chat-GGUF with the single-file model quantization llama-2-7b-chat.Q4_K_M.gguf:
After downloading the model, I loaded it:
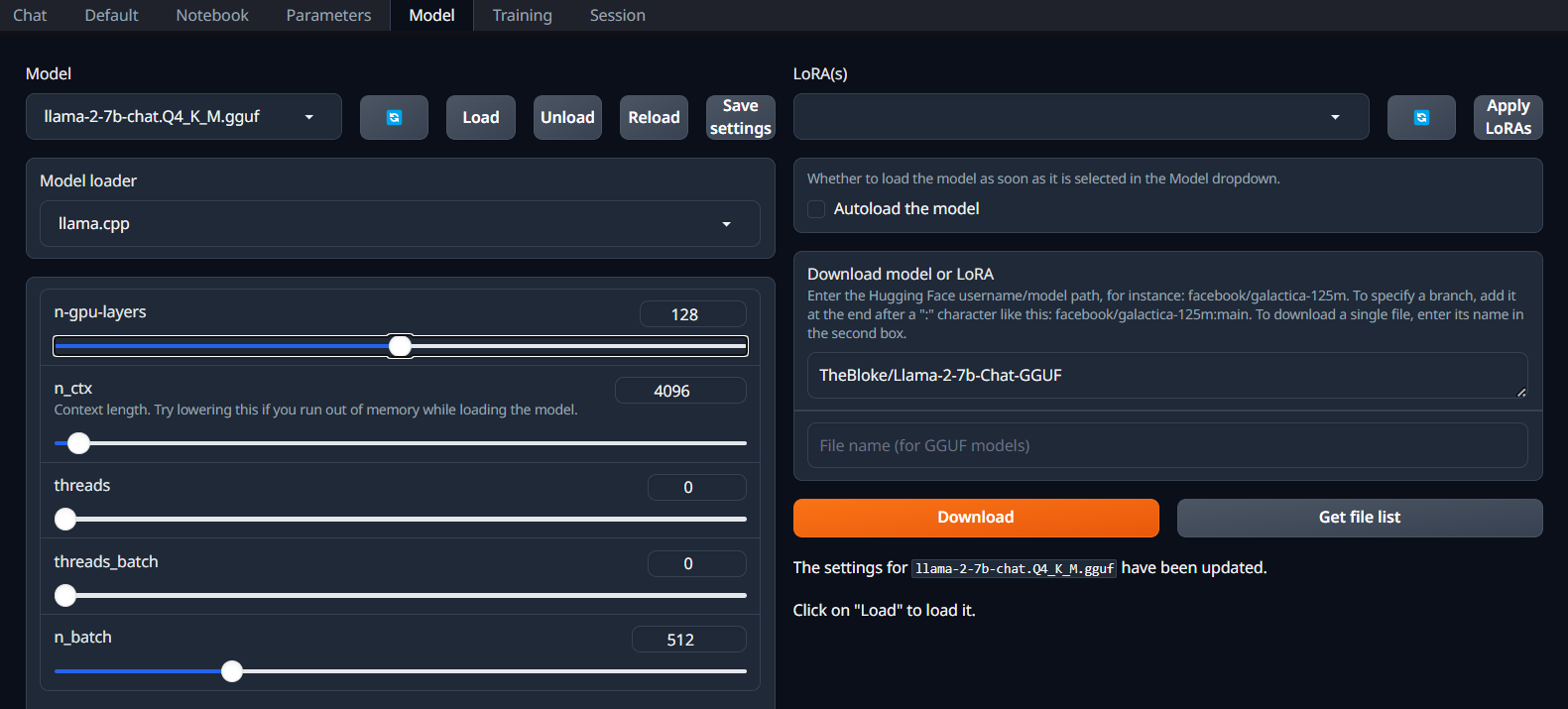
Once set up, I was able to start chatting locally. On my Orin NX 16G, the typical rate was 4.15 tokens per second:

Sheared-LLaMa-1-3b-ShareGPT
Next, I experimented with princeton-nlp/Sheared-LLaMA-1.3B-ShareGPT and set the Model Loader to Transformers using the same input prompt:
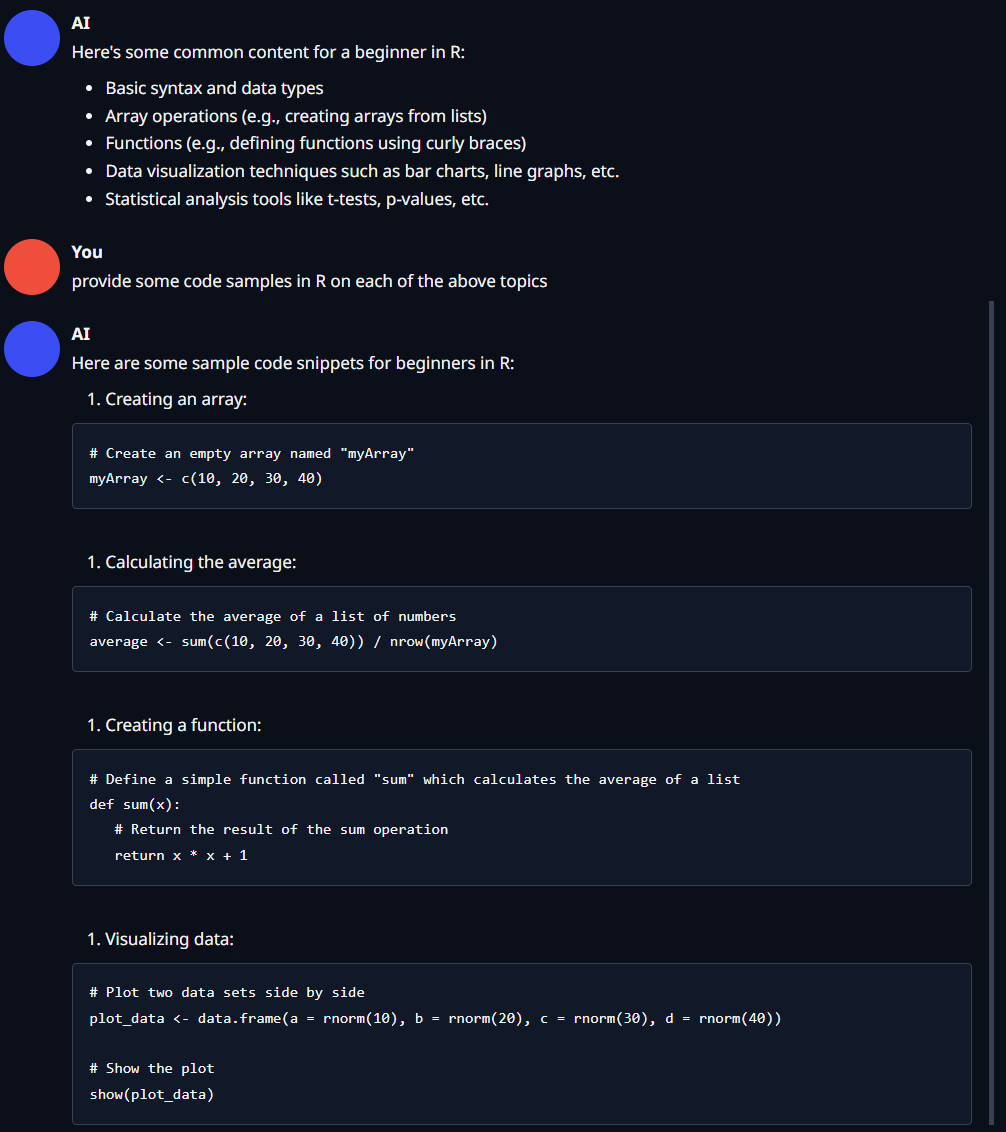
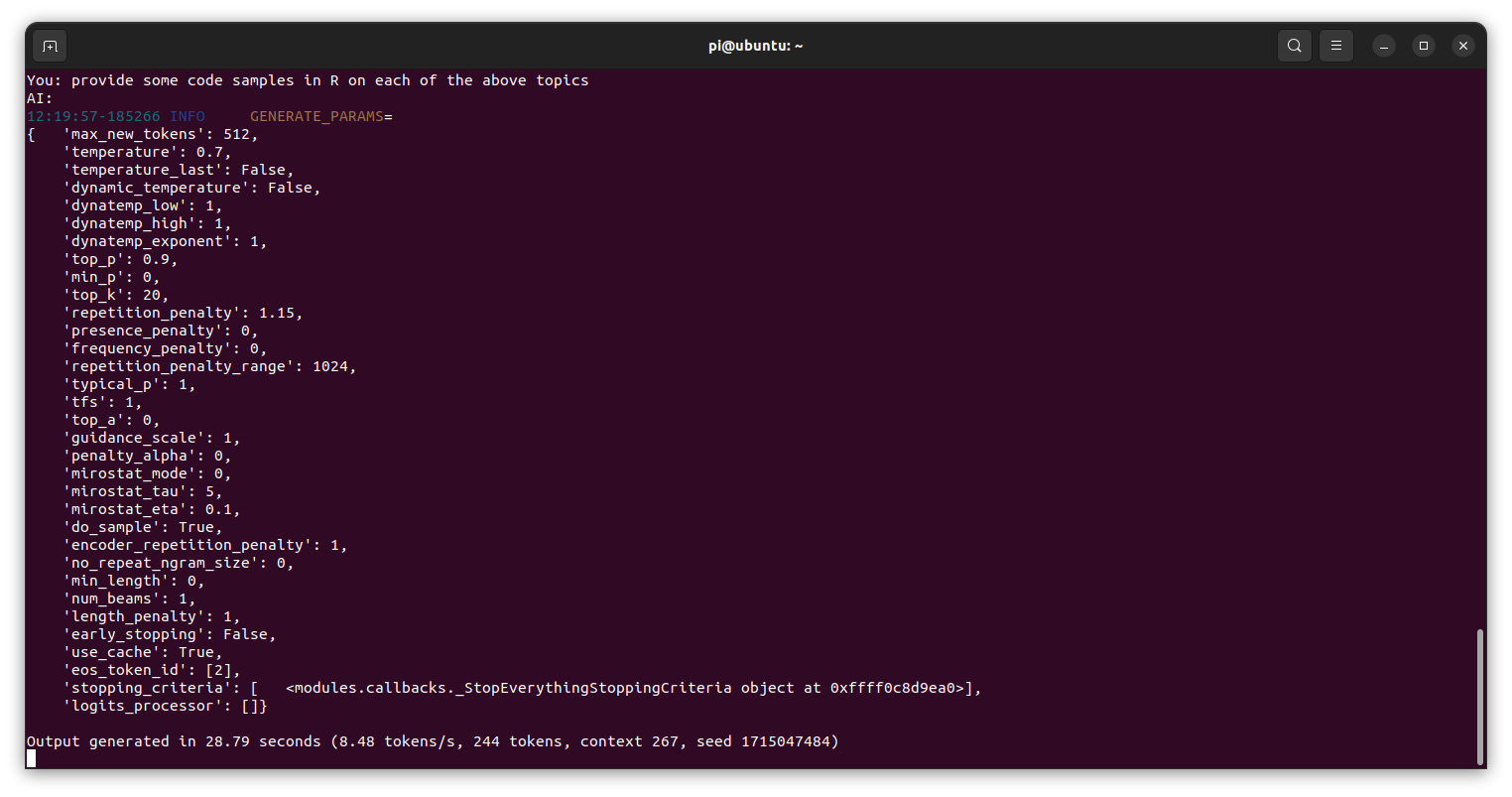
On average, this setup yielded a higher inference rate of around 8.48 tokens per second without compromising chat quality.
Sheared-LLaMA-1.3B is a model pruned and further pre-trained from meta-llama/Llama-2-7b-hf.
Jetson Examples
The jetson-examples repository by Seed Studio offers a straightforward, one-line command deployment for running Vision AI and Generative AI models on the NVIDIA Jetson platform.
To install the package, run:
pip3 install jetson-examples
Before proceeding to next section, add the required path to .bashrc file:
export PATH=/home/pi/.local/bin:$PATH
Text (LLM) - Llama3
To run Llama3, use the one-line command:
reComputer run llama3
Here is an example of the container in action:
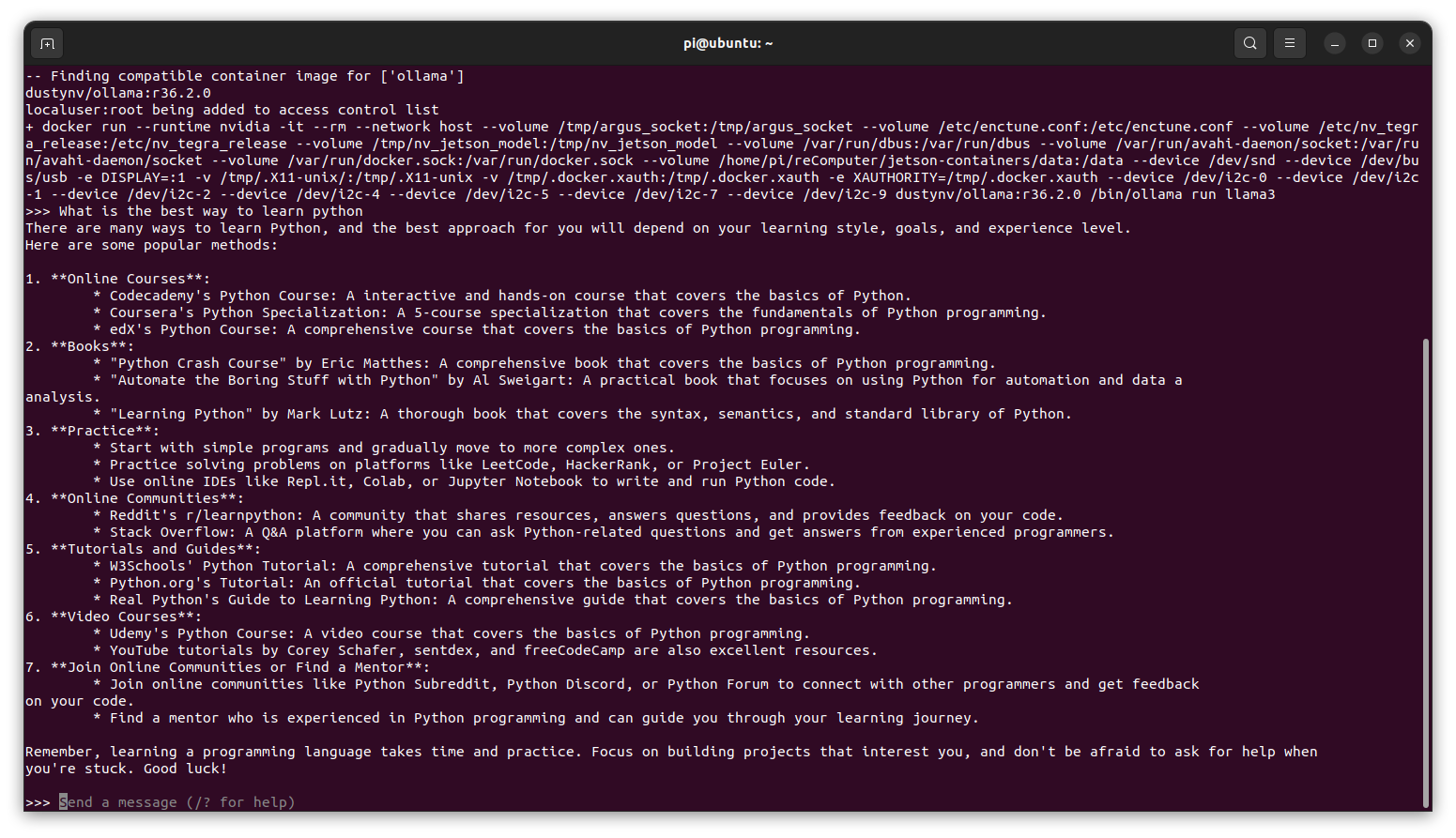
Text (LLM) - Sheared-LLaMA-2.7B-ShareGPT
For speed comparison, to run Sheared LLaMA, use the one-line command:
reComputer run Sheared-LLaMA-2.7B-ShareGPT
Here is an another example of the container in action:
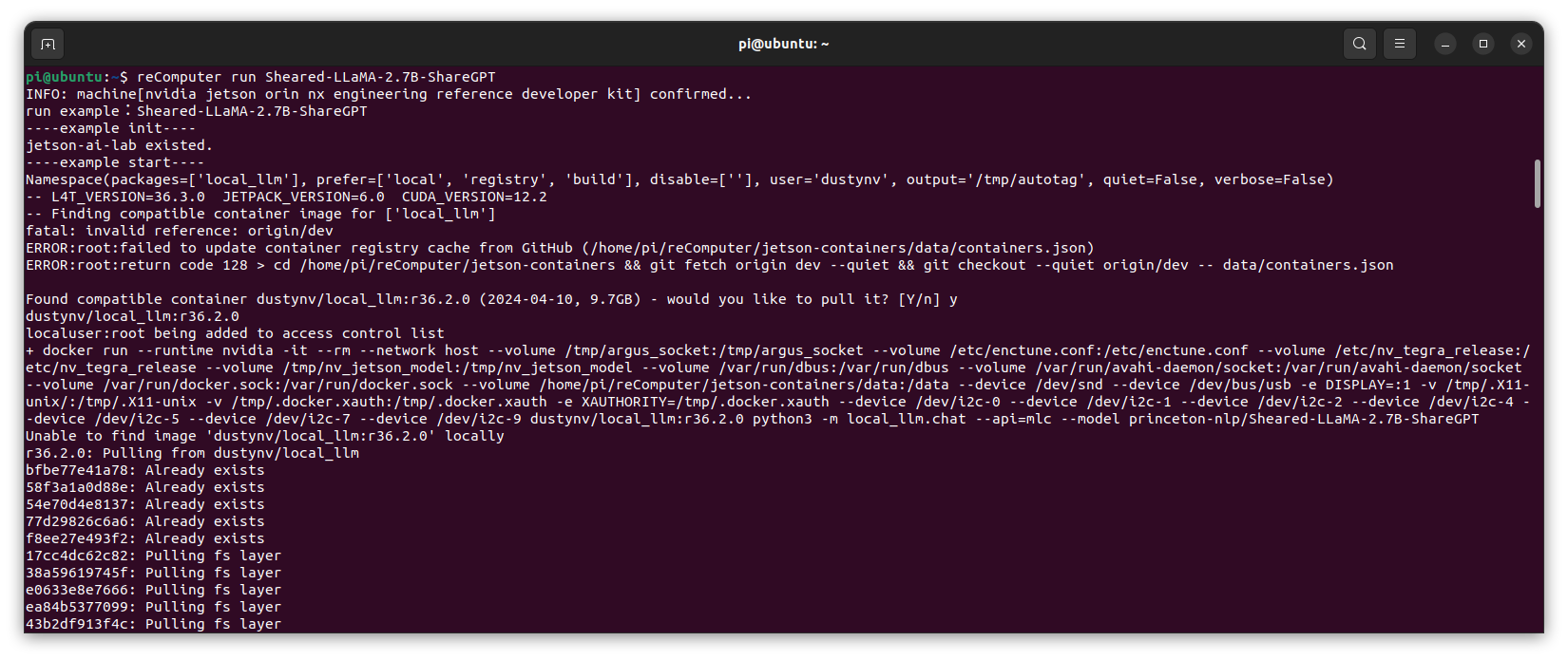
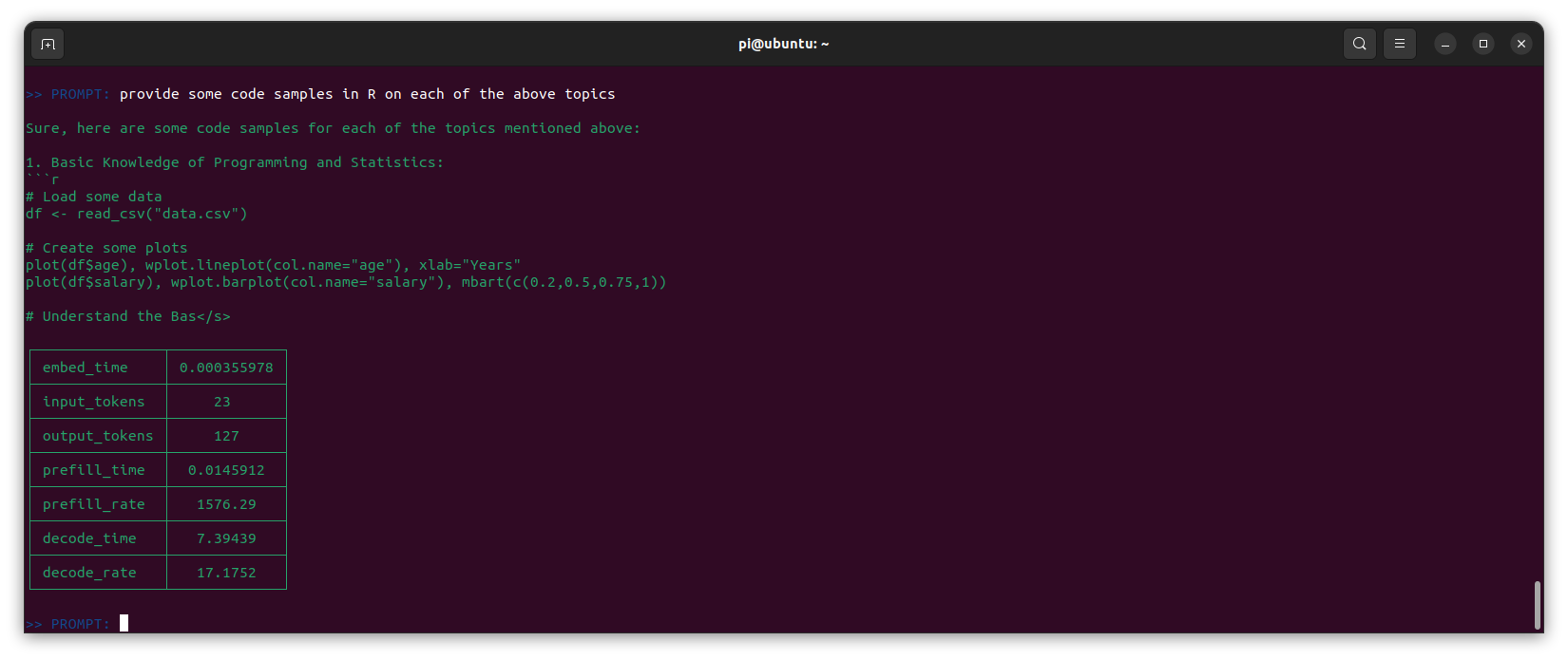
Inference Server - Ollama
To run the Ollama inference server, use the command:
reComputer run ollama
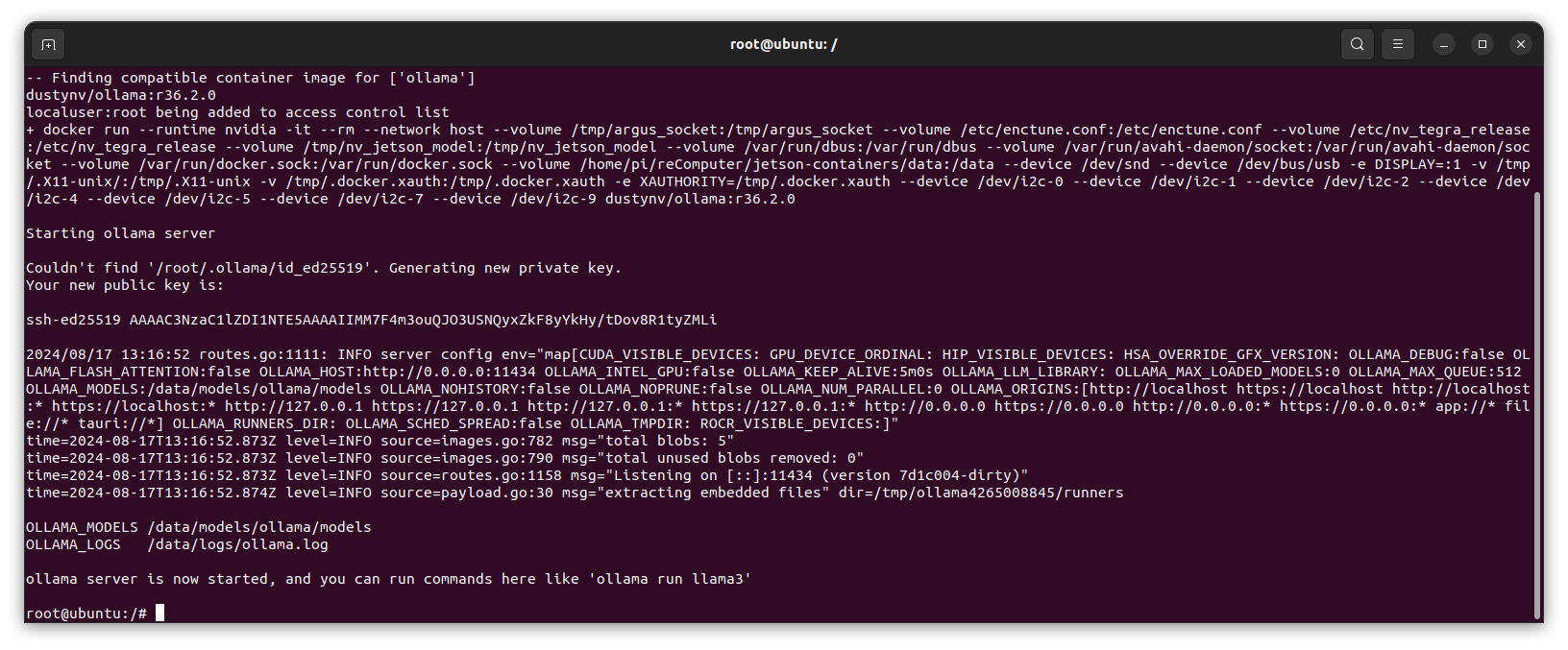
Once the Ollama inference server is running, you can interact with it by executing commands such as ollama run llama3 to start a chat session:
There’s much more to explore, but I’ll stop here for now. Enjoy your journey with Jetson!