Stable Diffusion: Text-to-Image Modeling Journey
In this article, we will delve into Stable Diffusion, a latent text-to-image diffusion model. In simple terms, diffusion models in machine learning represent a type of sophisticated computer program designed to learn how patterns evolve over time. Comprising three essential components – a forward process, a reverse process, and a sampling procedure – these models aim to comprehend and generate intricate patterns within a given dataset.
Consider having a blurry image that needs enhancement. Diffusion models act as intelligent tools that learn to eliminate blurriness by grasping how images blur and then effectively reversing that process.
These models find applications in various tasks, including image denoising, completing missing portions of an image, improving image clarity, and even generating entirely new images. For instance, OpenAI’s DALL-E 2, unveiled in April 2022, utilizes diffusion models to create images based on text descriptions.
Preparation
Upon installing Anaconda3 on my Windows Subsystem for Linux (WSL) machine, I cloned stable-diffusion.
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
Next, from Hugging Face, I obtained the provided checkpoint:
wget https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
Linked the model:
mkdir -p models/ldm/stable-diffusion-v1/
# Actual path to the checkpoint file
ln -s ~/stable-diffusion/sd-v1-4.ckpt models/ldm/stable-diffusion-v1/model.ckpt
Image generation
Let’s experiment with generating a sample:
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
This image is from outputs/txt2img-samples/:

Trying another sample:
python scripts/txt2img.py --prompt "an astronaut riding a horse in photorealistic style" --plms

Image modification
Resizing my original image, st-john-island-original.jpeg, to 512 x 512 with resize.py and executing with “python resize.py”:
from PIL import Image
def resize_image(input_path, output_path, new_size):
try:
with Image.open(input_path) as img:
resized_img = img.resize(new_size)
resized_img.save(output_path)
print(f"Image resized and saved to {output_path}")
except Exception as e:
print(f"Error: {e}")
input_image_path = "./st-john-island-original.jpeg"
output_image_path = "./st-john-island-resized.jpg"
new_size = (512, 512)
resize_image(input_image_path, output_image_path, new_size)

Modifying the image with this prompt:
python scripts/img2img.py --prompt "monkey swinging from tree to tree on island" --init-img st-john-island-resized.jpg --strength 0.8

Troubleshooting
The original image, st-john-island-original.jpeg, is 1600 x 1200 in size.

However, encountered this error with the same prompt:
RuntimeError: CUDA out of memory. Tried to allocate 52.22 GiB (GPU 0; 5.99 GiB total capacity; 56.84 GiB already allocated; 0 bytes free; 58.18 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
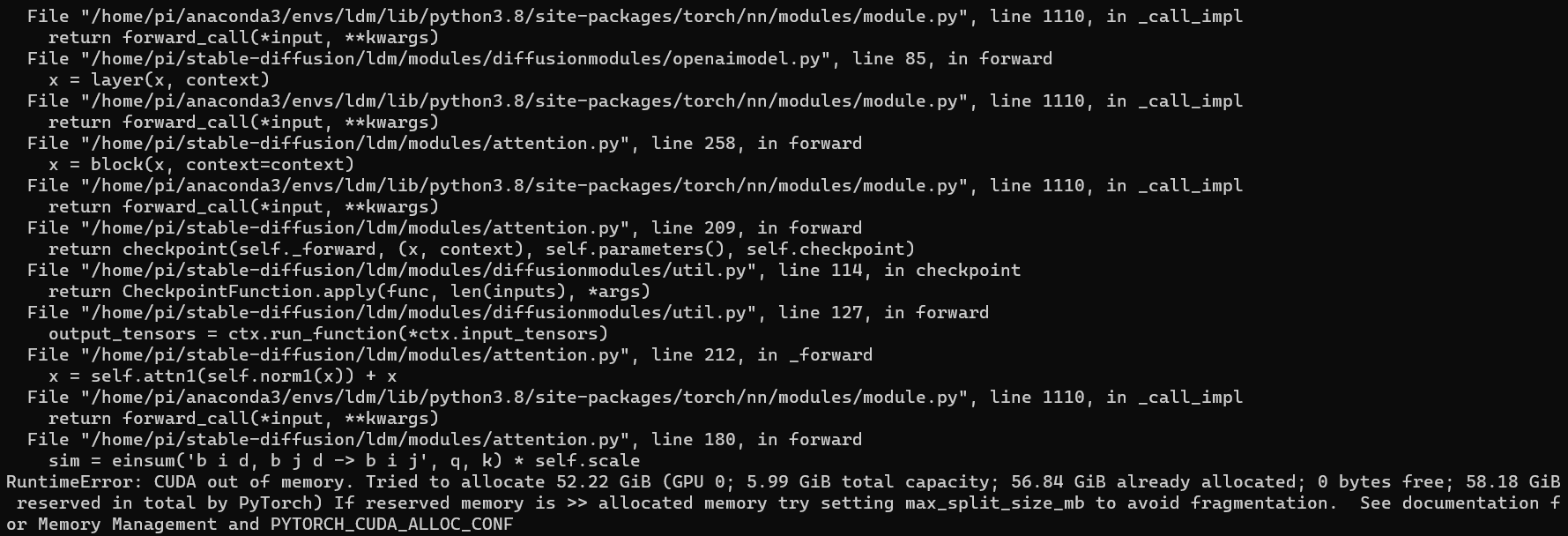
Even after attempting to expand memory in the .wslconfig file and restarting WSL with wsl –shutdown, the error persisted:
# Settings apply across all Linux distros running on WSL 2
[wsl2]
nestedVirtualization=true
kernelCommandLine=ipv6.disable=1
memory=80GB
processors=8
On further research, realised that the model is trained on 512x512 images and hence I resized my image instead.