Scaling Kafka Workloads with KEDA in Kubernetes
Building up my previous Kafka post, this article focuses on leveraging KEDA to scale Kafka consumer workloads dynamically. KEDA is a Kubernetes-based Event Driven Autoscaler that enables automatic scaling of pods based on the volume of events to be processed.
KEDA Setup
To begin, after accessing the mk8s-vm, simply install KEDA with the following commands:
sudo microk8s enable community
sudo microk8s enable keda
# Disable KEDA if necessary
sudo microk8s disable keda
Preparation
Kafka Consumer
Below is a sample kafka-consumer.yaml workload file (located in the newly created keda directory). This consumer will process messages from the serve-uuid Kafka topic as part of the kafka-consumer-group. Referring back to my Travel Portal Design, this could represent the Payment Service, where each UUID corresponds to a unique Order ID. In this example, each pod can handle only two unique order IDs and takes 20 seconds to complete processing.
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-consumer
namespace: kafka
spec:
replicas: 0
selector:
matchLabels:
app: kafka-consumer
template:
metadata:
labels:
app: kafka-consumer
spec:
containers:
- name: kafka-consumer
image: bitnami/kafka:latest
command:
- /bin/sh
- -c
- |
kafka-console-consumer.sh \
--bootstrap-server kafka.kafka.svc.cluster.local:9092 \
--topic serve-uuid \
--group kafka-consumer-group \
--consumer-property security.protocol=SASL_PLAINTEXT \
--consumer-property sasl.mechanism=PLAIN \
--consumer-property sasl.jaas.config="org.apache.kafka.common.security.plain.PlainLoginModule required username='user1' password='password1';" \
--max-messages '2' && \
echo "Simulating order processing for 20 seconds..." && \
sleep 20 && \
echo "KEDA scaling down pod after cooldownPeriod..."
To deploy the consumer:
kubectl apply -f kafka-consumer.yaml
Kafka Secret and Trigger Authentication
Referring to the Apache Kafka Scaler documentation, I set up the Kafka authentication. Below is the keda-kafka-secrets.yaml file:
apiVersion: v1
kind: Secret
metadata:
name: keda-kafka-secrets
namespace: kafka
stringData:
sasl: "plaintext"
username: "user1"
password: "password1"
And here is the keda-trigger-auth-kafka.yaml file:
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-kafka-credential
namespace: kafka
spec:
secretTargetRef:
- parameter: sasl
name: keda-kafka-secrets
key: sasl
- parameter: username
name: keda-kafka-secrets
key: username
- parameter: password
name: keda-kafka-secrets
key: password
To apply the secret and trigger authentication:
kubectl apply -f keda-kafka-secrets.yaml
kubectl apply -f keda-trigger-auth-kafka.yaml
Kafka Scaled Object
For this proof of concept, I started with zero replicas of the kafka-consumer pod. Referencing the official Scaling Deployments documentation, here is my kafka-scaledobject.yaml file:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-scaledobject
namespace: kafka
spec:
scaleTargetRef:
name: kafka-consumer
minReplicaCount: 0
maxReplicaCount: 10
pollingInterval: 1 # KEDA check queue length every polling interval
cooldownPeriod: 120 # Seconds to wait before scaling resource back to 0
triggers:
- type: kafka
metadata:
bootstrapServers: kafka.kafka.svc.cluster.local:9092
topic: serve-uuid
consumerGroup: kafka-consumer-group
lagThreshold: "1"
authenticationRef:
name: keda-trigger-auth-kafka-credential
To deploy the scaled object:
kubectl apply -f kafka-scaledobject.yaml
Creating a New Consumer Pod with KEDA
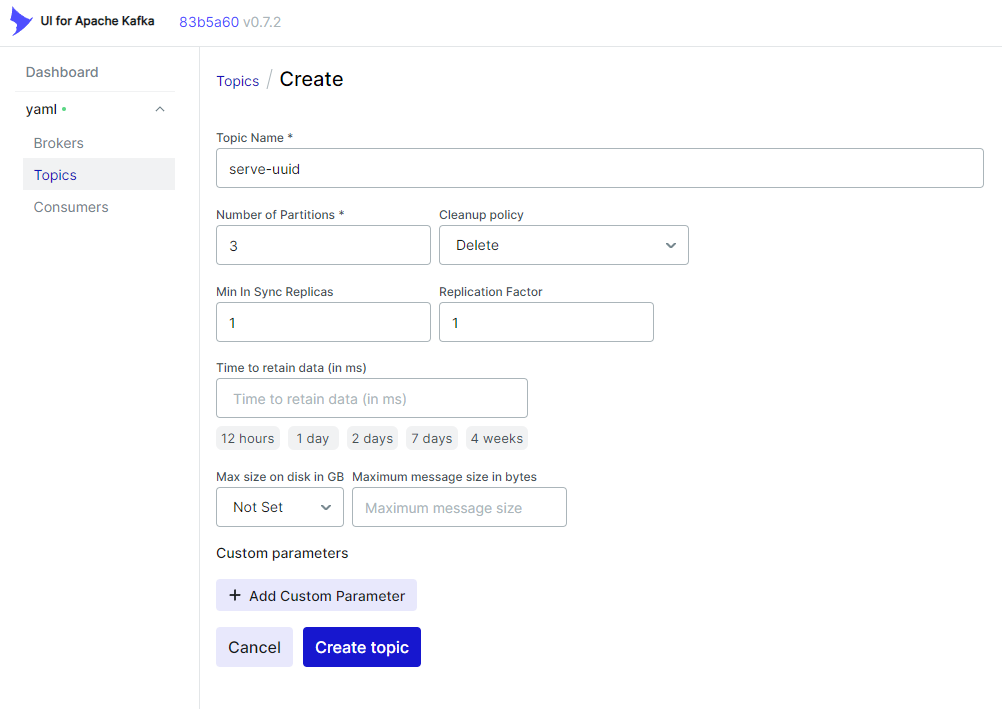
First, create the topic named serve-uuid:
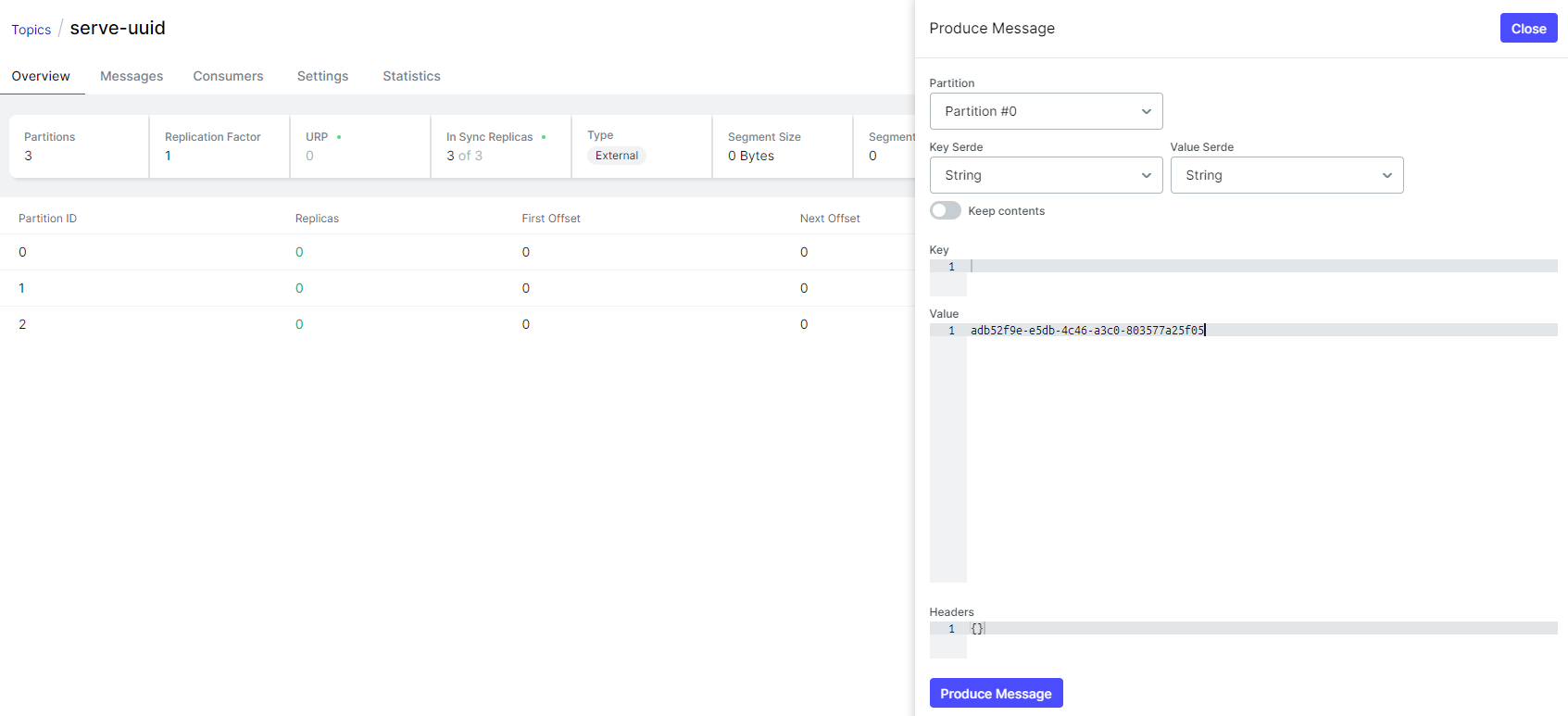
Next, simulate the receipt of the first order from the frontend store:
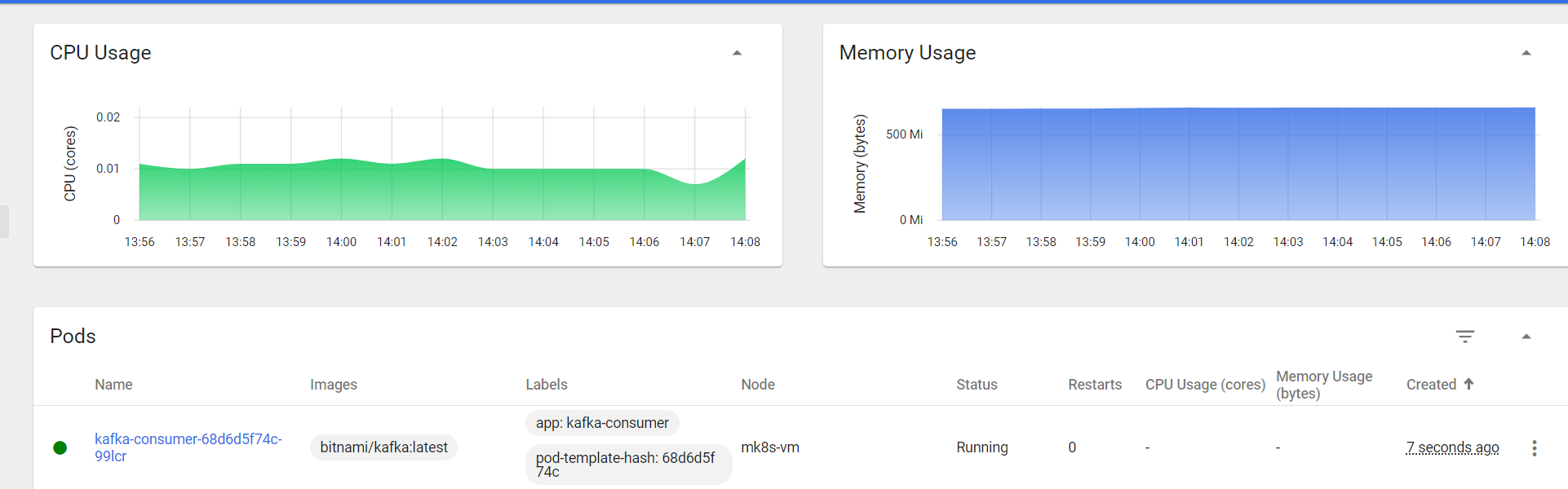
Once the first order is received, KEDA will automatically scale up the kafka-consumer pod:
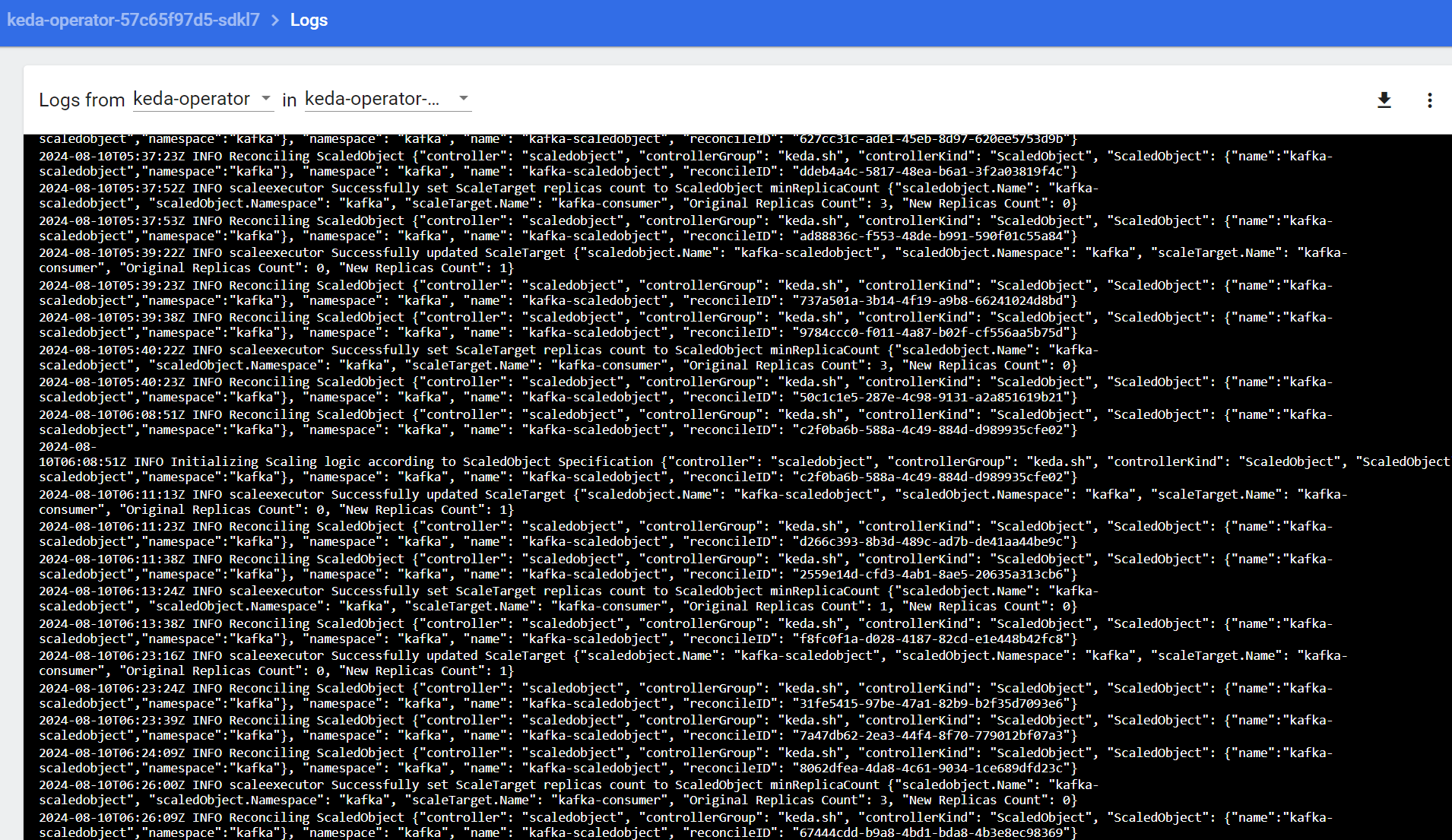
Here is the log for the first order:
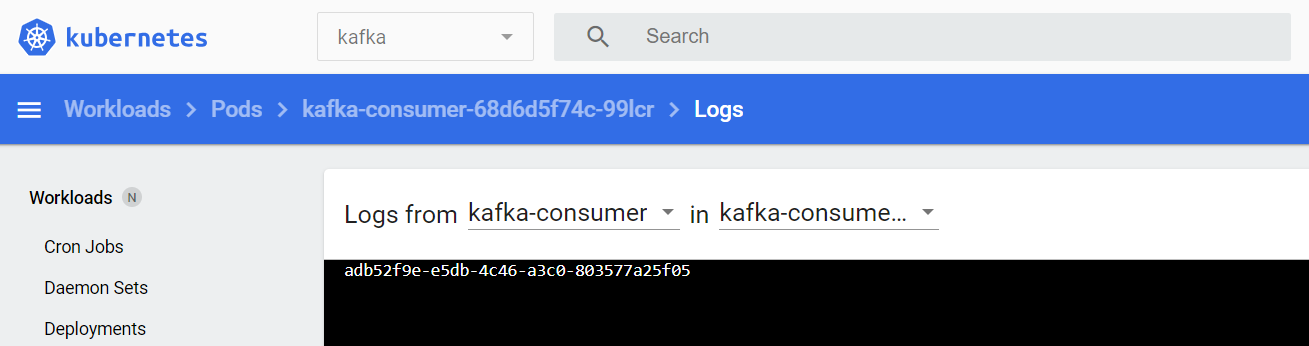
Assuming each microservice pod can process two orders at a time:
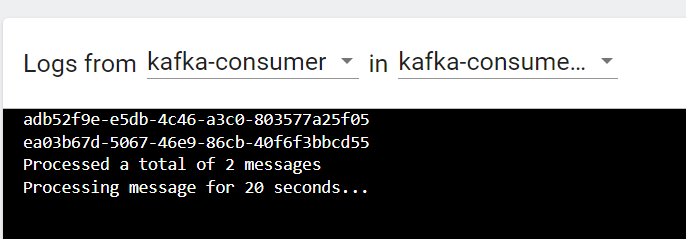
Once the specified cooldownPeriod has elapsed, KEDA will scale the kafka-consumer pod back down to the defined minReplicaCount.
Scaling Under Heavy Load
By sending multiple messages simultaneously (simulating heavy load), KEDA will check the Kafka serve-uuid topic every pollingInterval and scale horizontally to meet the load requirements.
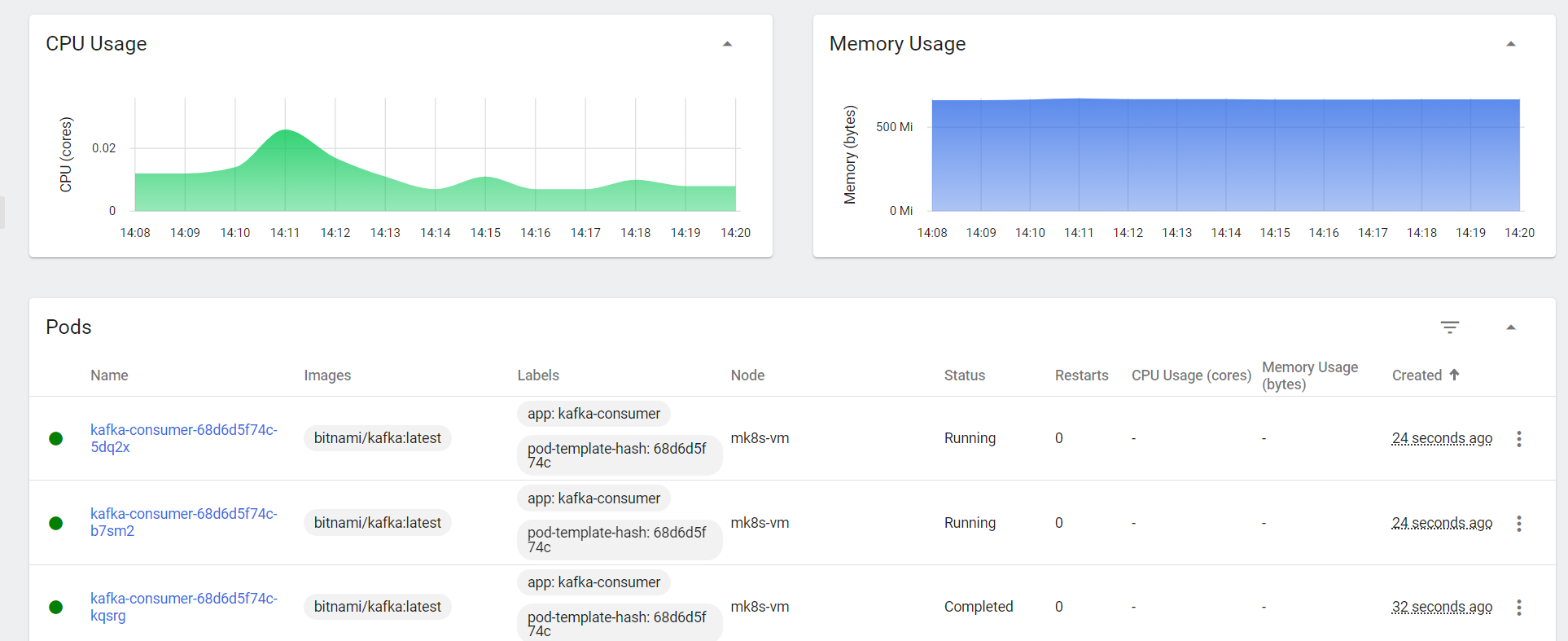
With this setup, developers can continue creating their order or payment microservices without worrying about manual scaling. KEDA handles the horizontal scaling automatically, relieving developers of the burden of implementing scaling logic in their code!
Optional - Kafka Scaled Job
In addition to scaling Deployments, you can also scale your code as Kubernetes Jobs using a ScaledJob. Here’s a sample kafka-scaledjob.yaml file:
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: kafka-scaledjob
namespace: kafka
spec:
jobTargetRef:
parallelism: 5 # Max number of desired pods
completions: 5 # Desired number of successfully finished pods
template:
spec:
containers:
- name: kafka-single-consumer
image: bitnami/kafka:latest
command:
- /bin/sh
- -c
- |
kafka-console-consumer.sh \
--bootstrap-server kafka.kafka.svc.cluster.local:9092 \
--topic serve-uuid \
--group kafka-consumer-group \
--consumer-property security.protocol=SASL_PLAINTEXT \
--consumer-property sasl.mechanism=PLAIN \
--consumer-property sasl.jaas.config="org.apache.kafka.common.security.plain.PlainLoginModule required username='user1' password='password1';" \
--max-messages '1' && \
echo "Simulating order processing for 20 seconds..." && \
sleep 20 && \
echo "Job completed..."
restartPolicy: Never
pollingInterval: 1 # KEDA checks queue length every polling interval
maxReplicaCount: 2 # Max number of replicas
successfulJobsHistoryLimit: 0 # Optional
failedJobsHistoryLimit: 3 # Optional
triggers:
- type: kafka
metadata:
bootstrapServers: kafka.kafka.svc.cluster.local:9092
topic: serve-uuid
consumerGroup: kafka-consumer-group
lagThreshold: "1"
authenticationRef:
name: keda-trigger-auth-kafka-credential
To deploy this:
- Delete the previous ScaledObject
kubectl delete -f kafka-scaledobject.yaml
- Apply the new ScaledJob:
kubectl apply -f kafka-scaledjob.yaml
With this setup, when a new order UUID is received, a new job will be created:
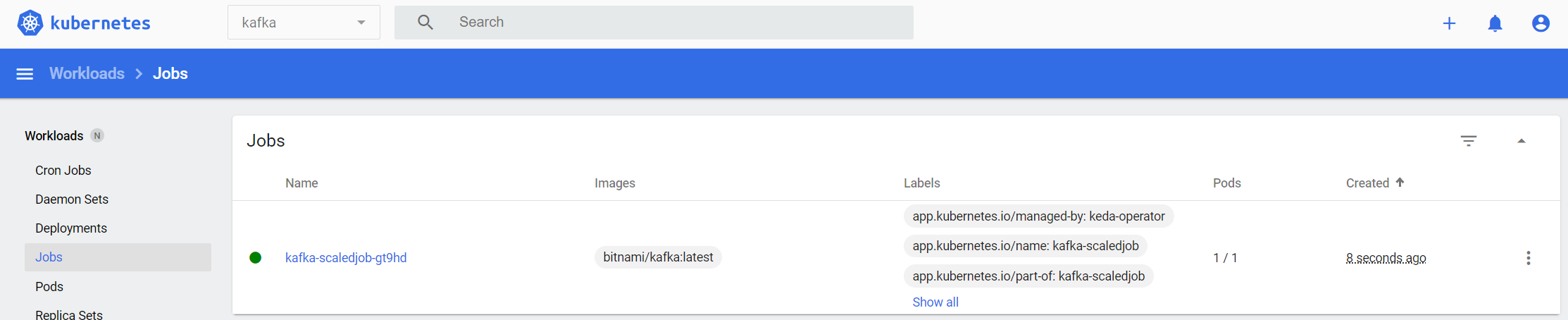
Here’s a log view of the job:
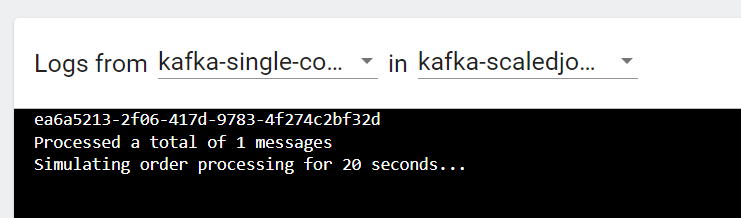
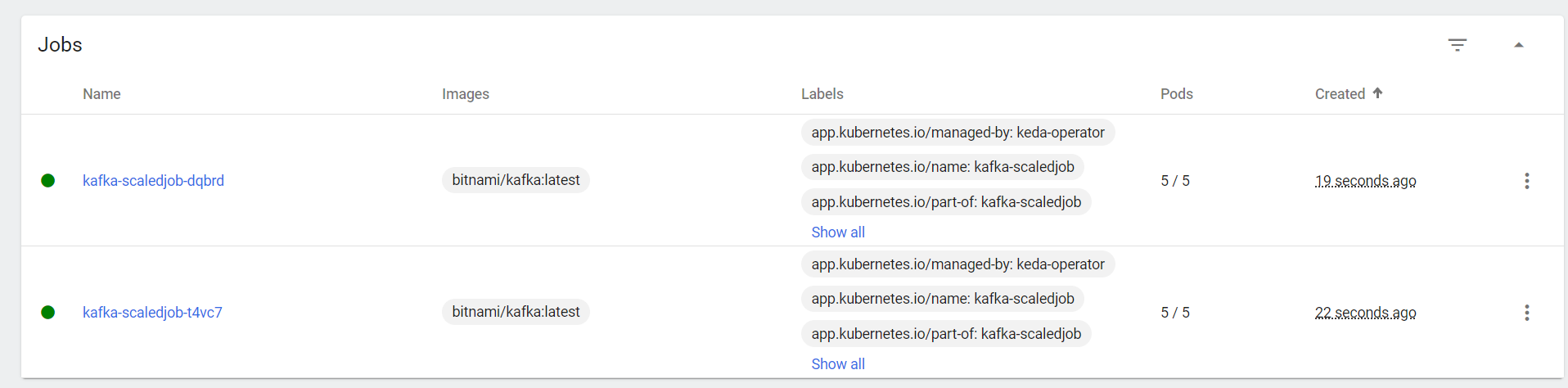
To handle more concurrent jobs, the serve-uuid topic has been updated to 5 partitions. Under heavy load, a maximum of 2 replicas will be created as shown below:
Troubleshooting
If you encounter any issues with KEDA scaling, you can check the logs of the keda-operator pod for more details.