Porting Llama2.java to Micronaut
In this post, I’ll demonstrate how to port llama2.java into a Micronaut application. The goal is to expose APIs for text generation and chat functionality with continuous inference support. Along the way, we’ll explore GraalVM, parallelism configuration, and other optimizations.
Getting Started
GraalVM is an advanced JDK with ahead-of-time Native Image compilation.
java --version
# java 23.0.1 2024-10-15
# Java(TM) SE Runtime Environment Oracle GraalVM 23.0.1+11.1 (build 23.0.1+11-jvmci-b01)
# Java HotSpot(TM) 64-Bit Server VM Oracle GraalVM 23.0.1+11.1 (build 23.0.1+11-jvmci-b01, mixed mode, sharing)
First, create a new Micronaut project with GraalVM support:
mn create-app example.micronaut.llama2 --features=graalvm --build=gradle --lang=java --test=junit
Project Structure
The following structure organizes the core components of the Llama2 Micronaut application:
llama2/
├── src/
│ └── main/
│ ├── java/
│ │ └── example/
│ │ └── micronaut/
│ │ ├── Application.java
│ │ ├── model/
│ │ │ ├── Config.java
│ │ │ ├── Weights.java
│ │ │ ├── RunState.java
│ │ │ ├── Transformer.java
│ │ │ ├── Tokenizer.java
│ │ │ └── Sampler.java
│ │ ├── utils/
│ │ │ ├── TransformerUtils.java
│ │ │ ├── TokenUtils.java
│ │ │ └── SamplingUtils.java
│ │ ├── service/
│ │ │ └── Llama2Service.java
│ │ └── controller/
│ │ └── Llama2Controller.java
│ └── resources/
│ ├── application.properties
│ └── logback.xml
└── build.gradle
Configuring Parallelism
The parallelism for the ForkJoinPool is set programmatically within Application.java to improve performance during model inference:
@Singleton
public class Application {
private final String parallelism;
public Application(@Value("${java.util.concurrent.ForkJoinPool.common.parallelism:8}") String parallelism) {
this.parallelism = parallelism;
}
public void run(String[] args) {
// Programmatically set the parallelism property
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", parallelism);
System.out.println("ForkJoinPool parallelism set to: " + System.getProperty("java.util.concurrent.ForkJoinPool.common.parallelism"));
}
public static void main(String[] args) {
ApplicationContext context = Micronaut.run(Application.class, args);
Application app = context.getBean(Application.class);
app.run(args);
}
}
Application Configuration
In application.properties, you can define key settings such as parallelism and file paths for the transformer checkpoint and tokenizer:
micronaut.application.name=llama2
java.util.concurrent.ForkJoinPool.common.parallelism=8
transformer.checkpoint_path=stories15M.bin
transformer.tokenizer_path=tokenizer.bin
Gradle Modifications
The build.gradle file was updated to include dependencies and configurations required for GraalVM native image builds and other features:
dependencies {
annotationProcessor("org.projectlombok:lombok")
compileOnly("org.projectlombok:lombok")
}
application {
mainClass = "example.micronaut.Application"
applicationDefaultJvmArgs = [
'--enable-preview',
'--add-modules', 'jdk.incubator.vector',
]
}
java {
sourceCompatibility = JavaVersion.toVersion("23")
targetCompatibility = JavaVersion.toVersion("23")
}
tasks.withType(JavaCompile) {
options.compilerArgs += [
'--enable-preview',
'--add-modules', 'jdk.incubator.vector'
]
}
tasks.withType(JavaExec) {
jvmArgs += [
'--enable-preview',
'--add-modules', 'jdk.incubator.vector'
]
}
graalvmNative {
toolchainDetection = false
binaries {
main {
imageName = "application"
mainClass = "com.example.Application"
buildArgs.addAll([
'--enable-preview',
'--add-modules=jdk.incubator.vector',
'-march=x86-64',
'--initialize-at-build-time=com.example.Application',
'--enable-monitoring=heapdump,jfr',
'-H:+UnlockExperimentalVMOptions',
'-H:+ForeignAPISupport',
'-H:+ReportExceptionStackTraces',
])
}
}
}
...
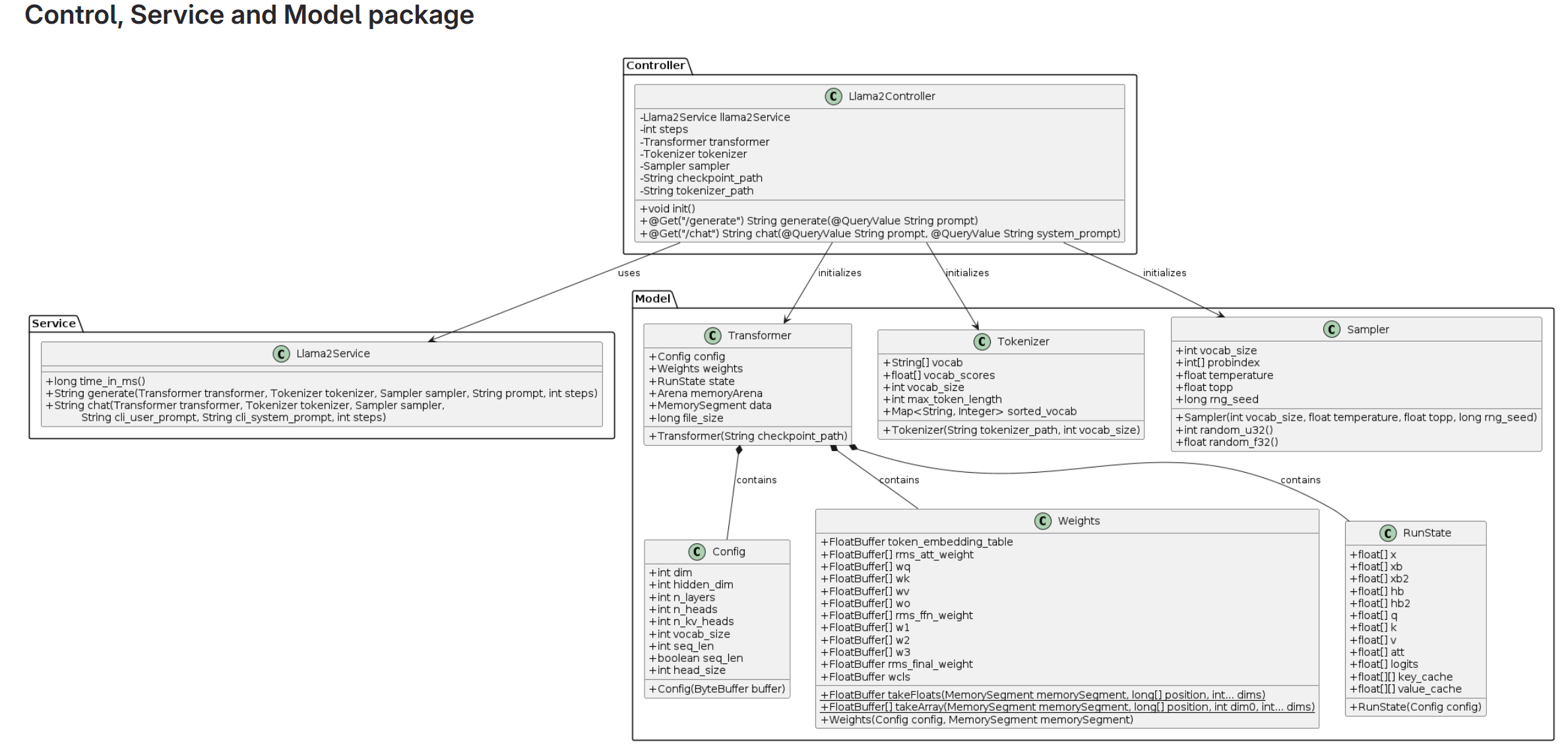
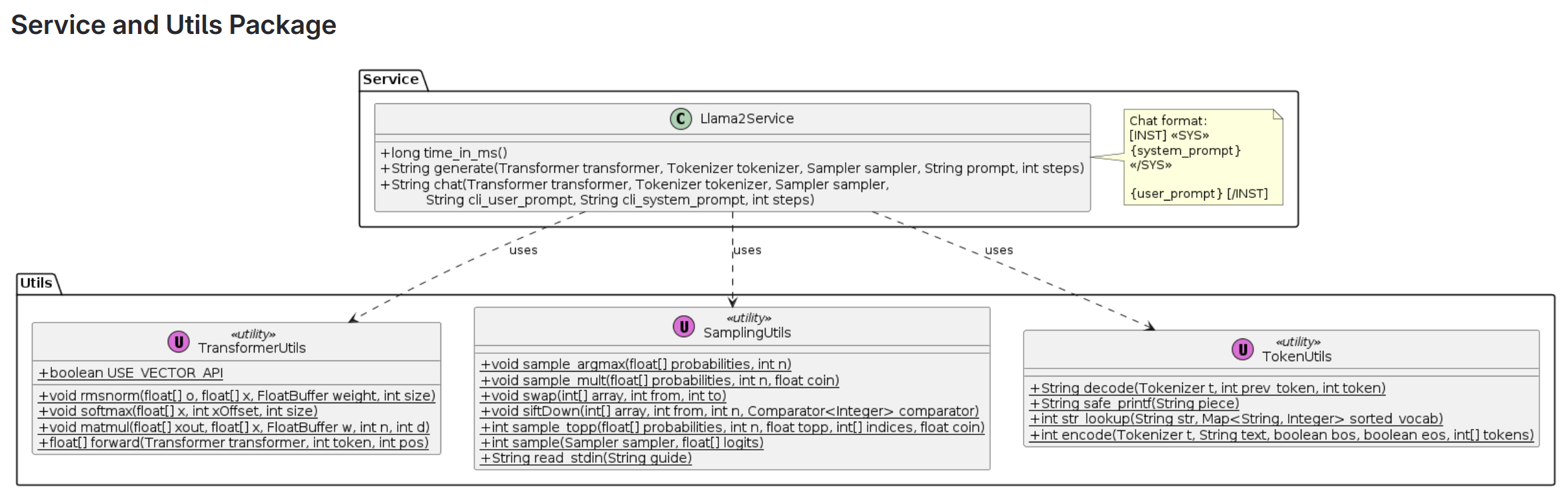
Class Diagram
These are the class diagrams:
Porting Llama2.java to Micronaut
Following Alfonso² Peterssen’s original llama2.java, the codebase was refactored and modularized into logical packages. Below are the highlights of each package:
Model Package
The model package defines data structures such as Config, Weights, and RunState. For example, here’s the Config.java class:
@ToString
public class Config {
...
Config(ByteBuffer buffer) {
this.dim = buffer.getInt();
this.hidden_dim = buffer.getInt();
this.n_layers = buffer.getInt();
this.n_heads = buffer.getInt();
this.n_kv_heads = buffer.getInt();
int vocab_size = buffer.getInt();
this.vocab_size = Math.abs(vocab_size);
this.seq_len = buffer.getInt();
this.shared_weights = vocab_size > 0;
this.head_size = dim / n_heads;
}
}
Utils Package
The utils package contains helper classes for neural network operations and token management. For example, TransformerUtils.java handles RMS normalization and others:
@UtilityClass
public class TransformerUtils {
public void rmsnorm(float[] o, float[] x, FloatBuffer weight, int size) {
// calculate sum of squares
float ss = 0.0f;
for (int j = 0; j < size; j++) {
ss += x[j] * x[j];
}
ss /= size;
ss += 1e-5f;
ss = 1.0f / (float) Math.sqrt(ss);
// normalize and scale
for (int j = 0; j < size; j++) {
o[j] = weight.get(j) * (ss * x[j]);
}
}
Service Package
The Llama2Service class provides core inference methods like generate and chat:
@Singleton
public class Llama2Service {
public String generate(Transformer transformer, Tokenizer tokenizer, Sampler sampler, String prompt, int steps) {
// Perform text generation
...
}
public String chat(Transformer transformer, Tokenizer tokenizer, Sampler sampler,
String cli_user_prompt, String cli_system_prompt, int steps) {
// Handle chat interactions
...
}
Controller Package
Finally, the Llama2Controller exposes REST APIs for text generation and chat functionality:
@Controller("/api/llama2")
@RequiredArgsConstructor
public class Llama2Controller {
private final Llama2Service llama2Service;
@PostConstruct
public void init() throws IOException {
// Initialize model
...
}
@Get("/generate")
public String generate(@QueryValue(defaultValue = "Once upon a time") String prompt) {
return llama2Service.generate(transformer, tokenizer, sampler, prompt, steps);
}
@Get("/chat")
public String chat(@QueryValue(defaultValue = "Once upon a time") String prompt,
@QueryValue(defaultValue = "You are a helpful assistant.") String system_prompt) {
return llama2Service.chat(transformer, tokenizer, sampler, prompt, system_prompt, steps);
}
}
Running the Application
To run the application in JDK mode, execute the following commands:
cd llama2
# Build the project and run it
.\gradlew build
.\gradlew run
# Clean, build and run the project
.\gradlew clean build run

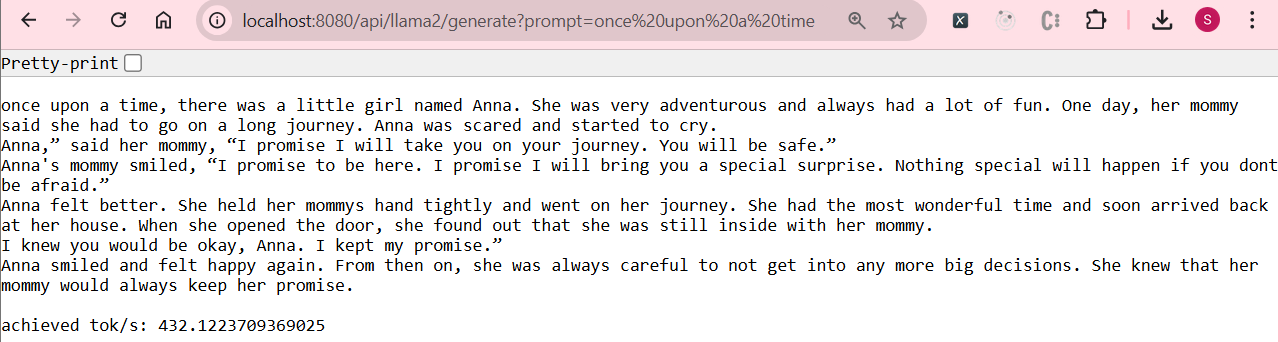
The application starts in approximately 425ms. You can test it by navigating to:
http://localhost:8080/api/llama2/generate?prompt=once%20upon%20a%20time
This will return a generated response based on the Llama2 model, achieving 432 token/seconds:
Running in GraalVM
To compile and run the application in native mode, follow these steps:
cd llama2
# Clean and compile the project in native mode
.\gradlew clean nativeCompile
# Execute the compiled binary
.\build\native\nativeCompile\application.exe
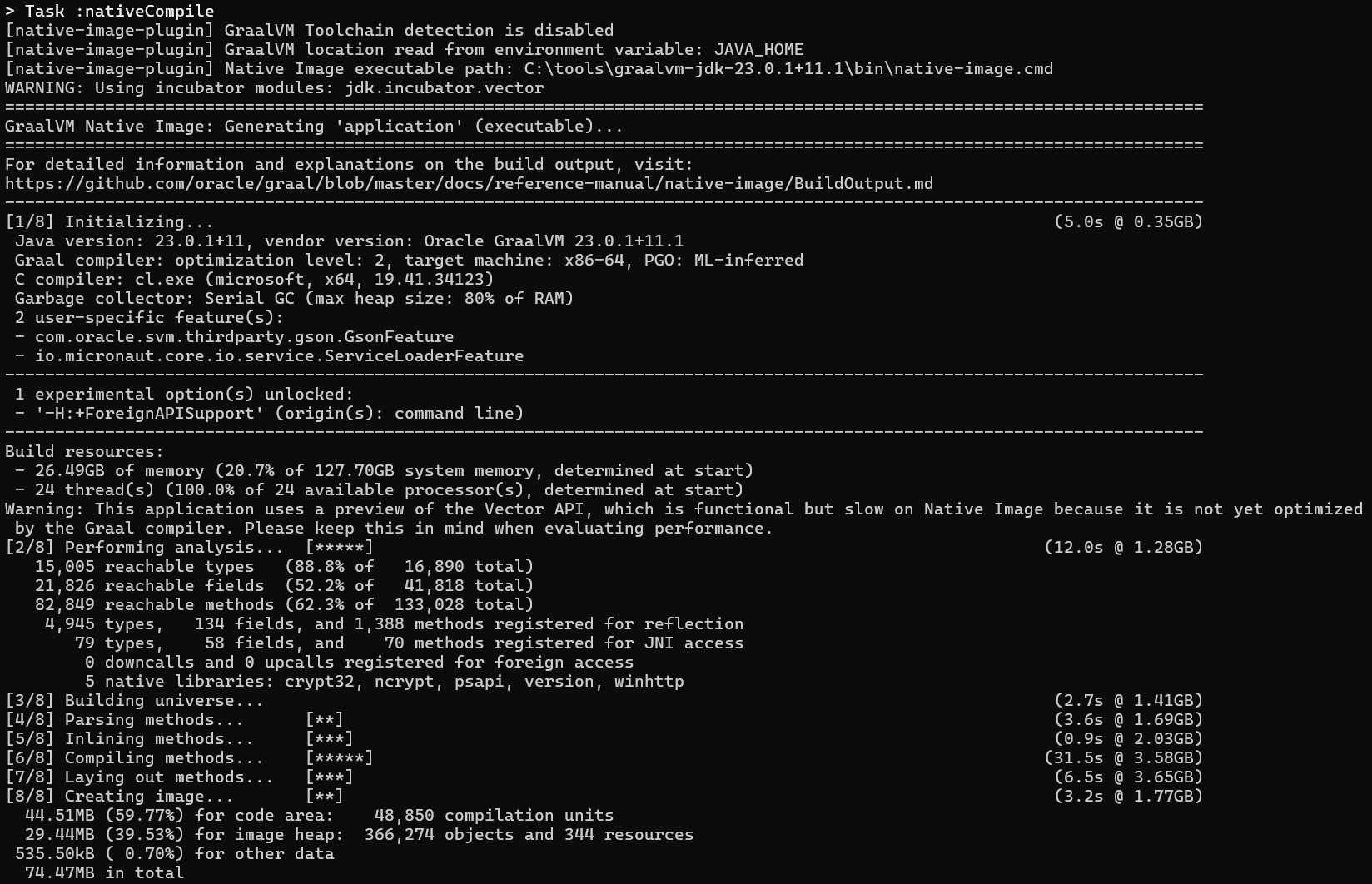
The startup time in native mode is impressively fast, taking only about 50ms:

However, serving in native mode results in a slower processing rate, averaging around 237 tokens/second:

Code Repository
The full implementation of this Micronaut Llama2 project is available on GitHub. Check out the repository and try it out yourself: https://github.com/seehiong/micronaut-llama2.git