Deploying LLMs with WasmEdge in HomeLab
In this post, we delve into the deployment of Lightweight Language Models (LLMs) using WasmEdge, a lightweight, high-performance, and extensible WebAssembly runtime. This setup is tailored to run LLMs in our previously configured HomeLab environment.
Preparation
To establish an OpenAI-compatible API server, begin by downloading the API server application:
curl -LO https://github.com/LlamaEdge/LlamaEdge/releases/latest/download/llama-api-server.wasm
For Rust-based Llama 2 inference, we require the Wasi-NN plugin. The Dockerfile below reflects this configuration:
FROM wasmedge/wasmedge:ubuntu-build-gcc
ENV template sample_template
ENV model sample_model
RUN mkdir /models
RUN apt update && apt install -y curl git ninja-build
RUN git clone https://github.com/WasmEdge/WasmEdge.git -b0.14.0-alpha.1
# Ubuntu/Debian with OpenBLAS
RUN apt update
RUN apt install -y software-properties-common lsb-release cmake unzip pkg-config
RUN apt install -y libopenblas-dev
RUN cmake -GNinja -Bbuild -DCMAKE_BUILD_TYPE=Release \
-DWASMEDGE_PLUGIN_WASI_NN_BACKEND="GGML" \
-DWASMEDGE_PLUGIN_WASI_NN_GGML_LLAMA_BLAS=ON \
.
RUN cmake --build build
RUN cmake --install build
COPY ./llama-api-server.wasm /WasmEdge
RUN export WASMEDGE_PLUGIN_PATH=/WasmEdge/build/plugins/wasi_nn
WORKDIR /WasmEdge
CMD ["sh", "-c", "wasmedge --dir .:. --nn-preload default:GGML:AUTO:/models/\"$model\" llama-api-server.wasm --prompt-template ${template} --log-stat"]
The template and model environment variables in the Dockerfile are parameters that can be customized later in the K3s YAML file.
Build and push the image to registry:
docker build . -t wasmedge-wasi-nn:0.14.0-alpha.1
docker tag wasmedge-wasi-nn:0.14.0-alpha.1 registry.local:5000/wasmedge-wasi-nn:0.14.0-alpha.1
docker push registry.local:5000/wasmedge-wasi-nn:0.14.0-alpha.1
Download the LLM:
wget https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/blob/main/llama-2-7b-chat.Q4_K_M.gguf
Run the image:
docker run -p 8080:8080 -v $PWD:/models -e "model=llama-2-7b-chat.Q4_K_M.gguf" -e "template=llama-2-chat" wasmedge-wasi-nn:0.14.0-alpha.1
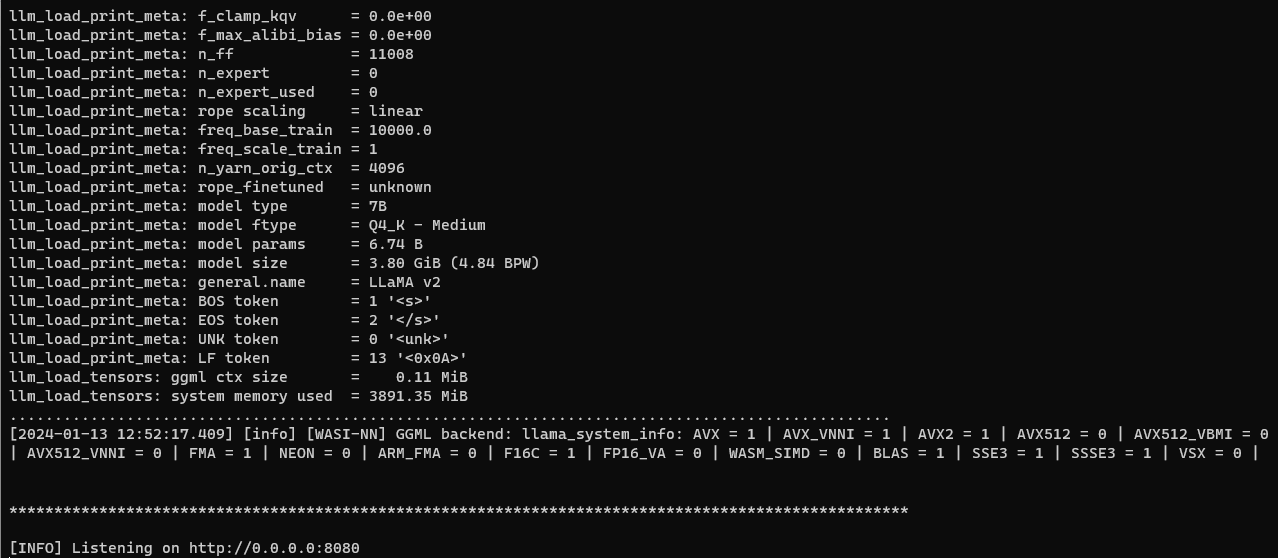
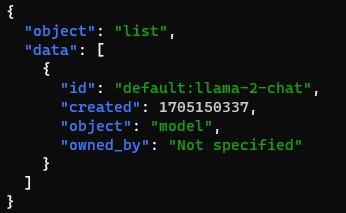
Test the API server:
curl -X POST http://localhost:8080/v1/models -H 'accept:application/json' | jq
Deploying to HomeLab
After moving the downloaded LLM to the NAS server, create the deploy.yaml file:
apiVersion: apps/v1
kind: Deployment
metadata:
name: wasmedge-llama2-7b-chat
namespace: llm
spec:
replicas: 1
selector:
matchLabels:
app: wasmedge-llama2-7b-chat
template:
metadata:
labels:
app: wasmedge-llama2-7b-chat
spec:
containers:
- name: wasmedge-llama2-7b-chat
image: registry.local:5000/wasmedge-wasi-nn:0.14.0-alpha.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
env:
- name: model
value: llama-2-7b-chat.Q4_K_M.gguf
- name: template
value: llama-2-chat
resources:
requests:
memory: "8Gi"
limits:
memory: "8Gi"
volumeMounts:
- name: models-store
mountPath: /models
imagePullSecrets:
- name: regcred
volumes:
- name: models-store
persistentVolumeClaim:
claimName: nfs-models
Create the corresponding svc.yaml file:
apiVersion: v1
kind: Service
metadata:
name: wasmedge-llama2-7b-chat-svc
namespace: llm
spec:
selector:
app: wasmedge-llama2-7b-chat
type: ClusterIP
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8080
Apply the changes:
kca deploy.yaml
kca svc.yaml
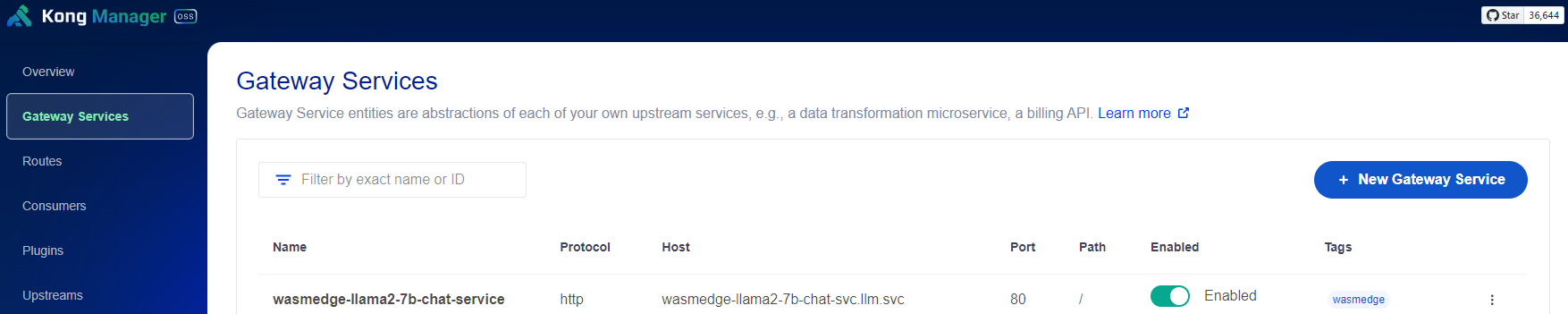
Next, set up both the Kong service and route:
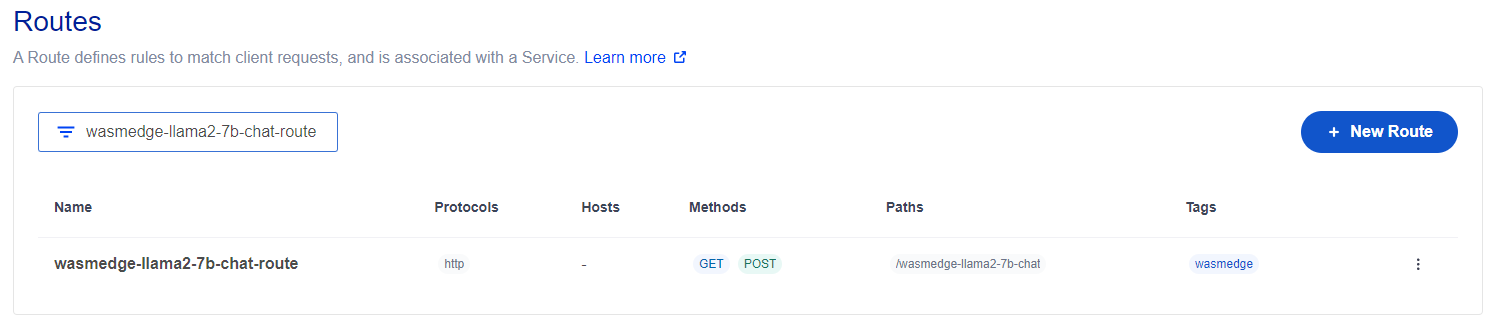
In Action
Chnage to using the new path in the Langchain4j application:
private static final String LOCAL_AI_URL = "http://api.local/wasmedge-llama2-7b-chat/v1";
After running the Spring Boot application, observe the result from the retrieve API:
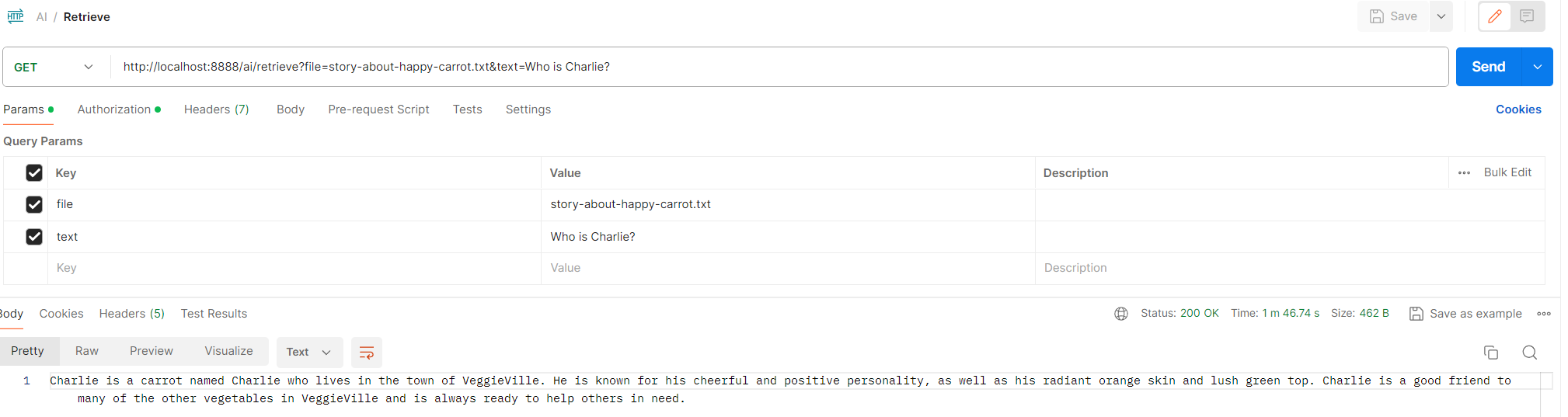
And that concludes our setup! Feel free to drop any questions or comments below.