In this post, I will explore MyScaleDB, an open-source, high-performance SQL vector database built on ClickHouse, and LlamaIndex, the leading data framework for building LLM applications.
Installation
After installing VSCodium as my primary IDE, I proceeded with installing the Python extension via Marketplace Link. Next, I created the virtual environment using venv:
# Create the envrionment
python -m venv myscaledb
# Activate the environment
myscaledb\Scripts\activate
This is my requirements.txt:
langchain
langchain_community
pydantic
clickhouse-connect
llama-index
llama-index-llms-ollama
llama-index-vector-stores-myscale
llama-index-embeddings-langchain
Install all the requirement pakcages with:
pip install -r requirements.txt
Preparation
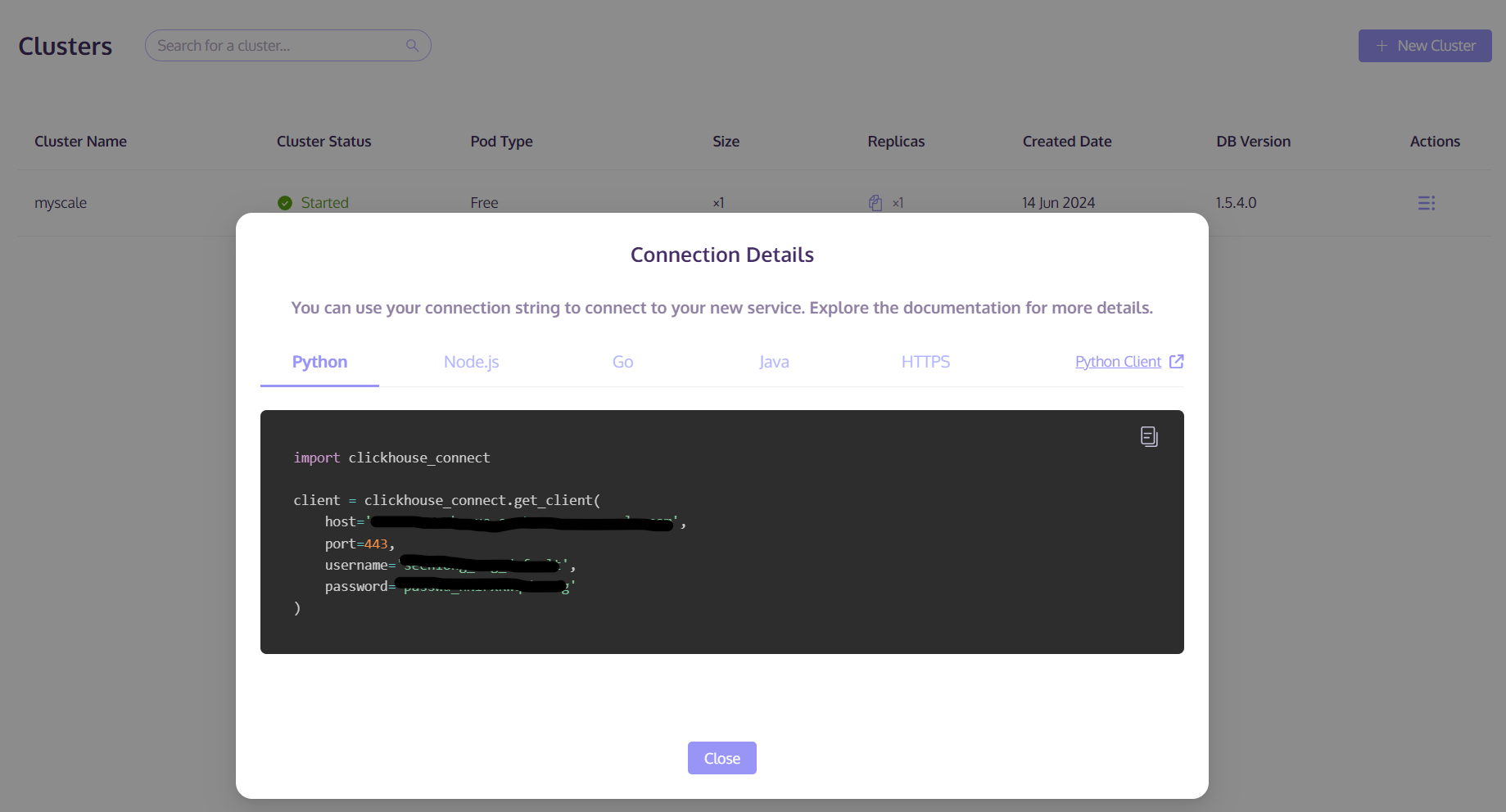
After signing up an account with MyScale, click on the Clusters and from the Actions, select Connection Details:
Building an RAG application
By following closely to Build An Advanced RAG Application using MyScaleDB and LlamaIndex, this is my rag.py:
from llama_index.llms.ollama import Ollama
llm = Ollama(model="llama3")
# NOTE: I added the send_receive_timeout and connect_timeout settings to fix the write operation timeout
# SEE: https://clickhouse.com/docs/en/integrations/python#clickhouse-connect-driver-api
import clickhouse_connect
client = clickhouse_connect.get_client(
host='xxxxxx.myscale.com',
port=443,
username='xxxxxx',
password='xxxxxx',
send_receive_timeout=600000,
connect_timeout=600000
)
Next, download and load the data:
import requests
url = 'https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(
input_files=["Nike_Catalog.pdf"]
)
documents = reader.load_data()
Categorize the data:
def analyze_and_assign_category(text):
if "football" in text.lower():
return "Football"
elif "basketball" in text.lower():
return "Basketball"
elif "running" in text.lower():
return "Running"
else:
return "Uncategorized"
Since I am using Ollama, pull the embedding model with ollama pull mxbai-embed-large. This is how it is used:
from langchain_community.embeddings import OllamaEmbeddings
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
from llama_index.core import VectorStoreIndex, Settings
Settings.embed_model = embeddings
Settings.llm = llm
Next, creates an index:
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
for document in documents:
category = analyze_and_assign_category(document.text)
document.metadata = {"Category": category}
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
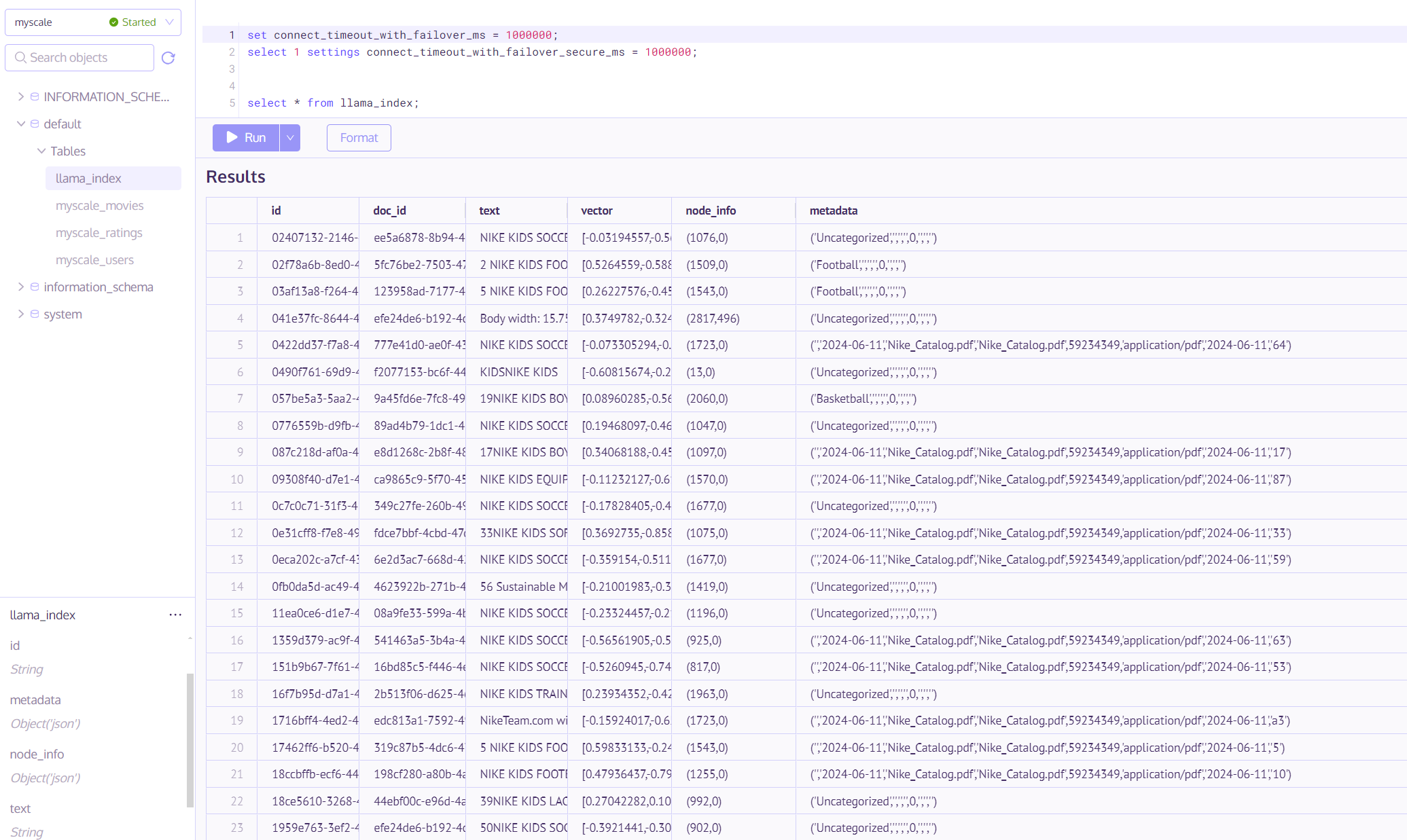
This is a sample result with this command from SQL workspace:
select * from llama_index;
Simple Query
To test it out with a simple query:
query_engine = index.as_query_engine()
response = query_engine.query("I want a few running shoes")
print(response)
This is a sample response:

Filtered Query
The query engine is configured with the metadata filter:
# Connect to the external vector store directly
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store
)
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
query_engine = index.as_query_engine(
filters=MetadataFilters(
filters=[
ExactMatchFilter(key="Category", value="Running"),
]
),
similarity_top_k=2,
vector_store_query_mode="hybrid",
)
response = query_engine.query("I want a few running shoes?")
print(response.source_nodes[0].text)
This is a sample response:
Troubleshooting
Initially I wanted to self-host MyScaleDB with this docker-compose.yaml:
version: '3.7'
services:
myscaledb:
image: myscale/myscaledb:1.5
tty: true
ports:
- '8123:8123'
- '9000:9000'
- '8998:8998'
- '9363:9363'
- '9116:9116'
networks:
myscaledb_network:
ipv4_address: 10.0.0.2
volumes:
- C:\myscaledb\volumes\data:/var/lib/clickhouse
- C:\myscaledb\volumes\log:/var/log/clickhouse-server
- C:\myscaledb\volumes\config\users.d\custom_users_config.xml:/etc/clickhouse-server/users.d/custom_users_config.xml
deploy:
resources:
limits:
cpus: "4.00"
memory: 32Gb
networks:
myscaledb_network:
driver: bridge
ipam:
driver: default
config:
- subnet: 10.0.0.0/24
and this custom_users_config.yaml:
<clickhouse>
<users>
<default>
<password></password>
<networks>
<ip>::1</ip>
<ip>127.0.0.1</ip>
<ip>10.0.0.0/24</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
<access_management>1</access_management>
<named_collection_control>1</named_collection_control>
<show_named_collections>1</show_named_collections>
<show_named_collections_secrets>1</show_named_collections_secrets>
</default>
</users>
</clickhouse>
I tried to create the user after logging into the console:
clickhouse-client
CREATE USER myscale IDENTIFIED WITH plaintext_password BY 'myscale'
COMMIT
GRANT ALL ON *.* TO myscale WITH GRANT OPTION;
quit
But I was greeted with this error:
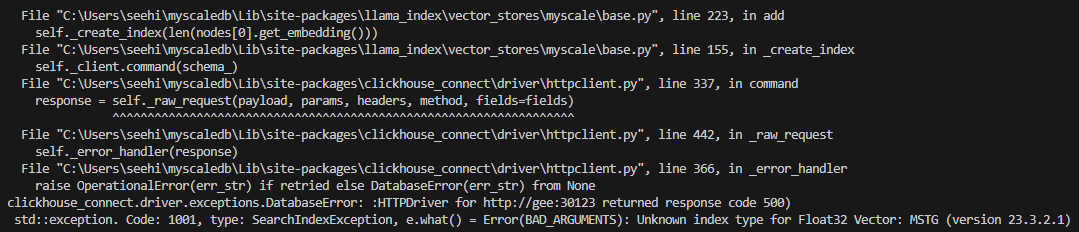
I realised that MSTG (Multi-scale Tree Graph) algorithm is provided through MyScale Cloud.