AutoPilot Setup for VS Code
In this post, I’m going to demonstrate the setup of Continue, an open-source autopilot designed for VS Code.
Getting Started
Once you’ve installed the plugin from the market place, let’s proceed by adding Continue to the right sidebar of VS Code, as recommended.
Provider - LM Studio
First, on my Windows machine, I’ll execute LM Studio and download Google’s Gemma 2B Instruct model.
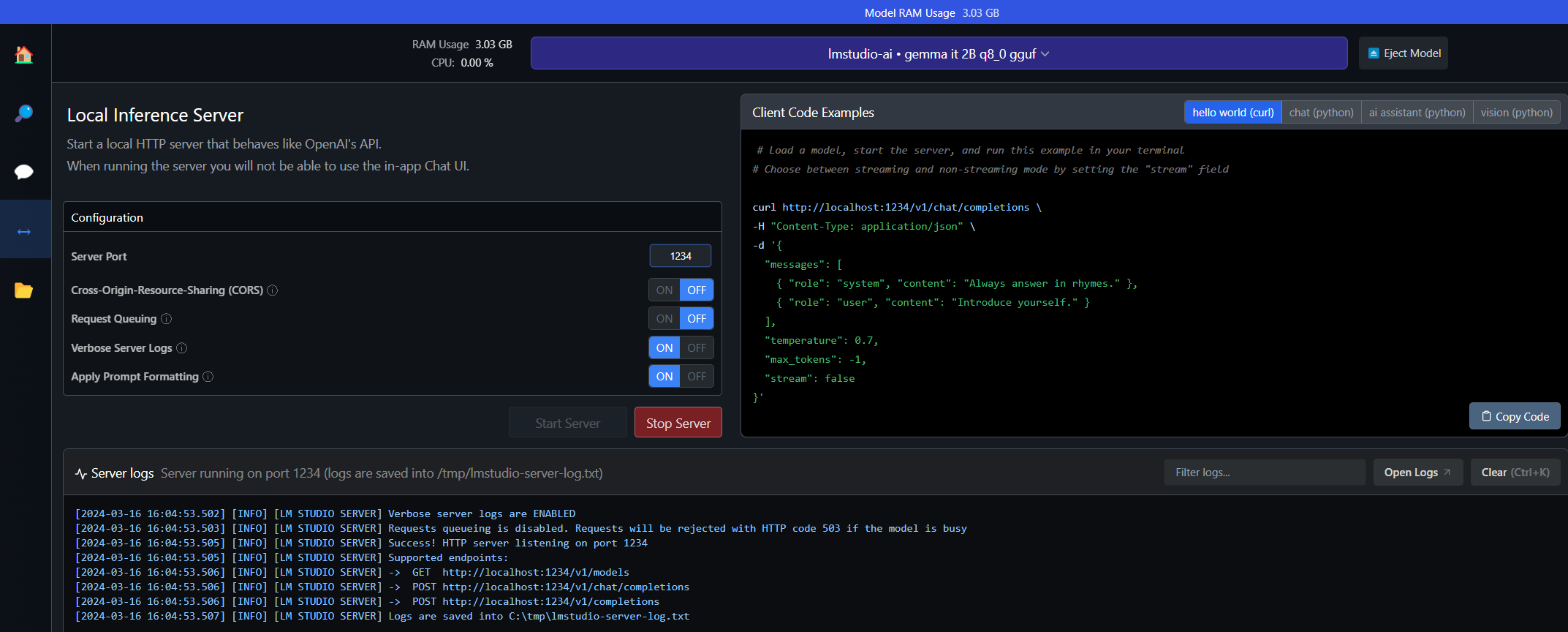
Provider - OpenAI-compatible
Next, let’s configure another LLM in our Home Lab. Here’s the Dockerfile from my previous post:
FROM python:3-slim-bullseye
ENV model sample_model
# We need to set the host to 0.0.0.0 to allow outside access
ENV HOST 0.0.0.0
# Install the package
RUN apt update && apt install -y libopenblas-dev ninja-build build-essential pkg-config
RUN pip install --upgrade pip
RUN python -m pip install --no-cache-dir --upgrade pip pytest cmake scikit-build setuptools fastapi uvicorn sse-starlette pydantic-settings starlette-context
RUN CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install --no-cache-dir --force-reinstall llama_cpp_python==0.2.27 --verbose
# Run the server
CMD ["sh", "-c", "python3 -m llama_cpp.server --model /models/\"$model\""]
Now, let’s build it:
# Build the image
docker build . -t llama-cpp-python:0.2.27
# Tag it
docker tag llama-cpp-python:0.2.27 registry.local:5000/llama-cpp-python:0.2.27
# Push to the registry
docker push registry.local:5000/llama-cpp-python:0.2.27
In this post, I’ll utilize the Deepseek-Coder model. Here’s the deploy.yaml file:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deepseek-coder-instruct
namespace: llm
spec:
replicas: 1
selector:
matchLabels:
app: deepseek-coder-instruct
template:
metadata:
labels:
app: deepseek-coder-instruct
spec:
containers:
- name: deepseek-coder-instruct
image: registry.local:5000/llama-cpp-python:0.2.27
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8000
securityContext:
capabilities:
add:
- IPC_LOCK
volumeMounts:
- name: models-store
mountPath: /models
subPath: ./llama-models
env:
- name: model
value: deepseek-coder-6.7b-instruct.Q4_K_M.gguf
resources:
requests:
memory: "6Gi"
limits:
memory: "6Gi"
imagePullSecrets:
- name: regcred
volumes:
- name: models-store
persistentVolumeClaim:
claimName: nfs
Here’s the svc.yaml file:
apiVersion: v1
kind: Service
metadata:
name: deepseek-coder-instruct-svc
namespace: llm
spec:
selector:
app: deepseek-coder-instruct
type: ClusterIP
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8000
Depending on your Home Lab configuration, I’m utilizing Kong Manager. Here’s my Gateway Service setup:
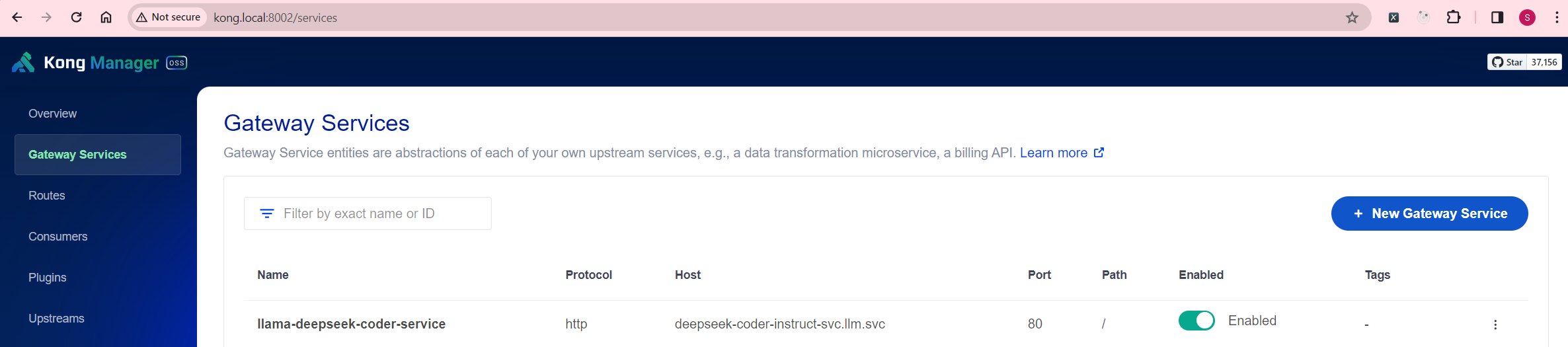
And here’s the Route setup:

Additionally, here’s the Application Log for the deployed pod:
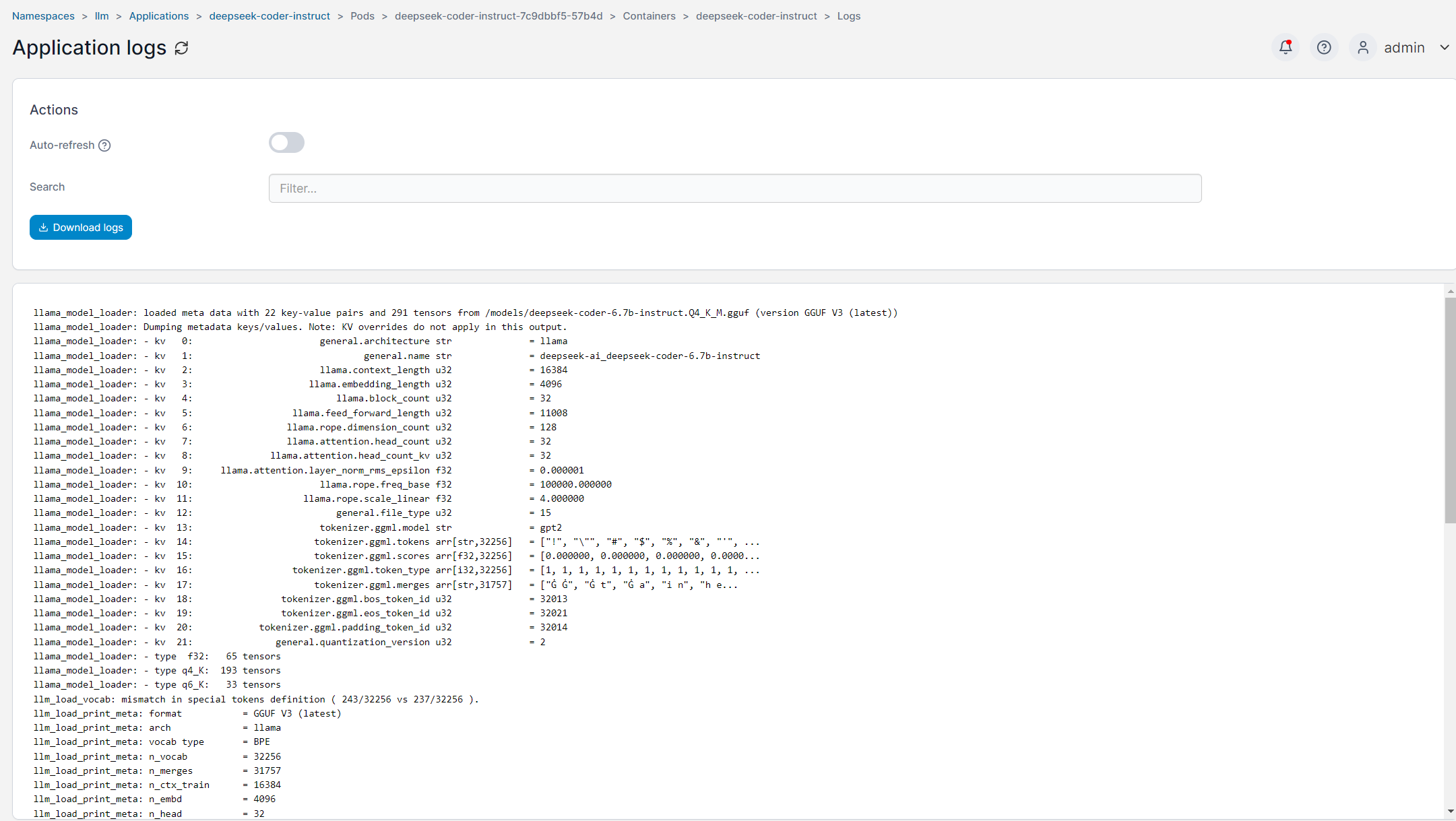
Configuration
From the Continue sidebar, click on the Plus icon at the bottom, then scroll all the way down and click on the Open config.json button.
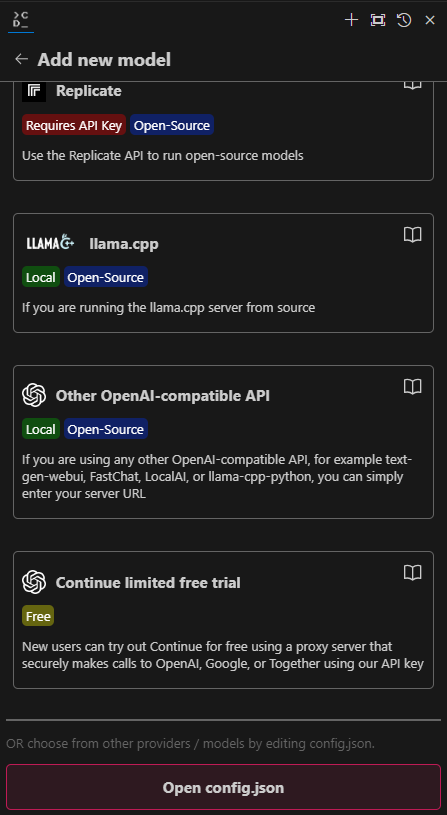
Since I’ve set up 2 models locally, here are the corresponding config values:
{
"models": [
{
"title": "LM Studio",
"provider": "lmstudio",
"model": "gemma-2b-it"
},
{
"title": "llama-cpp-python",
"provider": "openai",
"model": "deepseek-coder-6.7b-instruct.Q4_K_M.gguf",
"apiKey": "EMPTY",
"apiBase": "http://kong.local:8000/deepseek/v1"
}
],
...
For the tabAutocompleteModel, I am using:
"tabAutocompleteModel": {
"title": "llama-cpp-python",
"provider": "openai",
"model": "deepseek-coder-6.7b-instruct.Q4_K_M.gguf",
"apiKey": "EMPTY",
"apiBase": "http://kong.local:8000/deepseek/v1"
},
"allowAnonymousTelemetry": false,
...
}
Putting it into Action
Let’s test it out by inserting the dockerfile block into this post. After selecting the block of code, press CTRL-L, and it will appear on the right.
LM Studio
Let’s experiment with the LM Studio model:
OpenAI-compatible
Now, let’s experiment with the llama-cpp-python model:

That’s all there is to it! We now have a locally enabled autopilot for code completion!